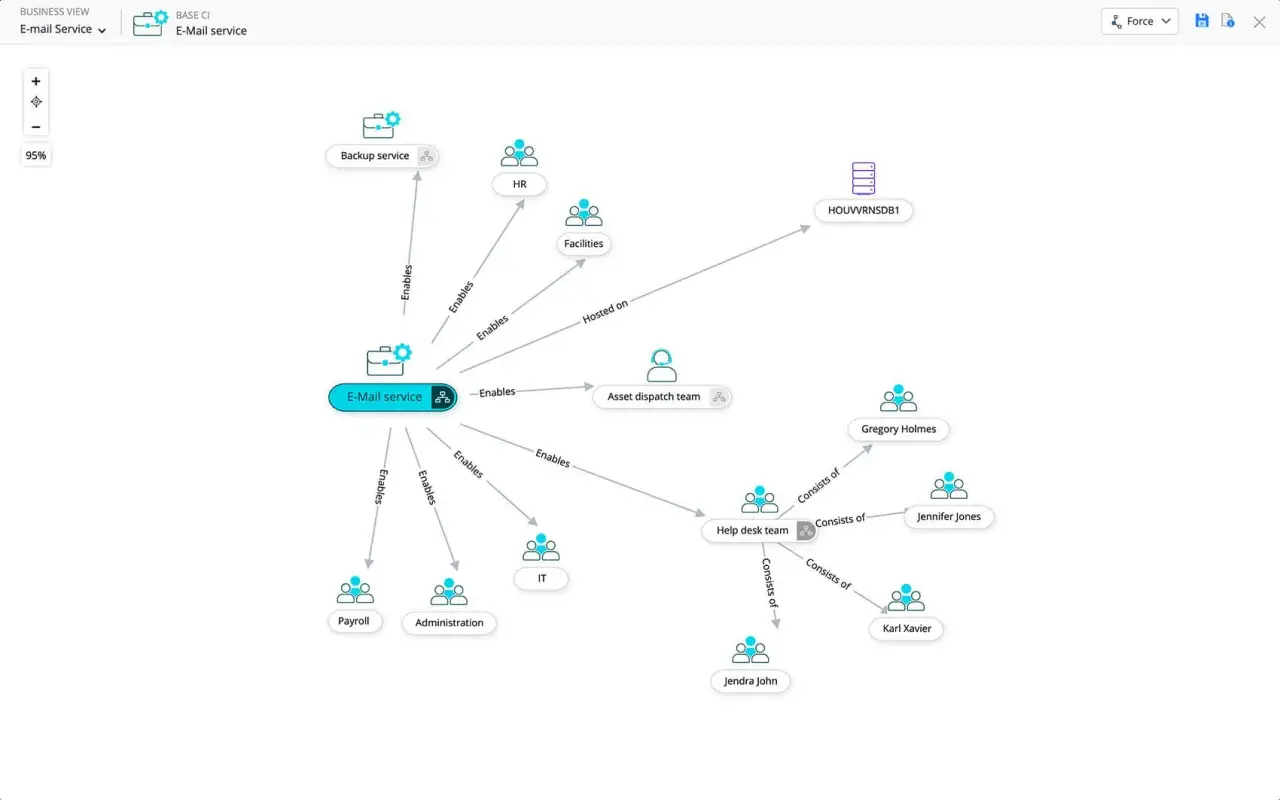
CMDB, czyli baza danych zarządzania konfiguracją, porządkuje to, czego w środowisku IT nie da się ogarnąć samą listą serwerów czy aplikacji. W praktyce pokazuje, jakie elementy składają się na usługę, jak są ze sobą powiązane i co może ucierpieć, gdy zmienisz jeden z nich. Dla backendu i DevOps to nie teoria, tylko narzędzie do bezpieczniejszych wdrożeń, szybszej diagnozy incydentów i lepszego zarządzania zależnościami.
Ja patrzę na nią przede wszystkim jak na mapę zależności, a nie kolejny katalog zasobów. I właśnie dlatego tak często wraca przy zmianach, awariach i audytach. Poniżej rozkładam temat na definicję, zastosowanie i praktyczne pułapki, które najczęściej psują wdrożenia.
Najważniejsze informacje w skrócie
- CMDB nie jest zwykłą inwentaryzacją, tylko modelem elementów konfiguracji i ich zależności.
- Największą wartość daje przy zmianach, analizie wpływu, incydentach i root cause analysis.
- W backendzie i DevOps pomaga ograniczyć blast radius, czyli zasięg potencjalnej awarii.
- CMDB nie zastępuje ITAM ani monitoringu, bo każde z tych narzędzi odpowiada na inne pytania.
- Dobrze działa tylko wtedy, gdy dane są aktualizowane automatycznie i mają właścicieli.
- Najlepsza CMDB jest selektywna, a nie przeładowana szczegółami, które niczego nie ułatwiają.
Czym jest CMDB i co faktycznie w niej trzymam
CMDB nie jest zwykłą bazą inwentaryzacyjną. Jej sednem są elementy konfiguracji, czyli zasoby, które mają znaczenie dla działania usługi: serwery, kontenery, bazy danych, klastry Kubernetes, load balancery, kolejki, usługi API, a czasem także zasoby logiczne lub zewnętrzne, jeśli wpływają na dostępność systemu.
Najważniejsze nie jest jednak samo istnienie rekordu, tylko relacja między rekordami. Jeśli wiem, że usługa płatności zależy od API autoryzacji, które korzysta z Redis i PostgreSQL, to mam materiał do analizy wpływu zmiany. Bez tego CMDB staje się tylko ładnie nazwanym katalogiem.
- serwer aplikacyjny i jego wersja systemu
- kontener lub deployment w Kubernetes
- instancja bazy danych i powiązana aplikacja
- kolejka wiadomości i konsumenci
- usługa zewnętrzna, jeśli jest krytyczna dla procesu biznesowego
Nie wrzucałbym do CMDB każdego drobiazgu. Jeżeli element nie zmienia ryzyka, nie wpływa na zależności i nie pomaga w decyzjach operacyjnych, zwykle tylko zaśmieca model. I właśnie tu wchodzi praktyka DevOps, bo wartość CMDB widać dopiero wtedy, gdy zaczyna wspierać zmiany i incydenty.
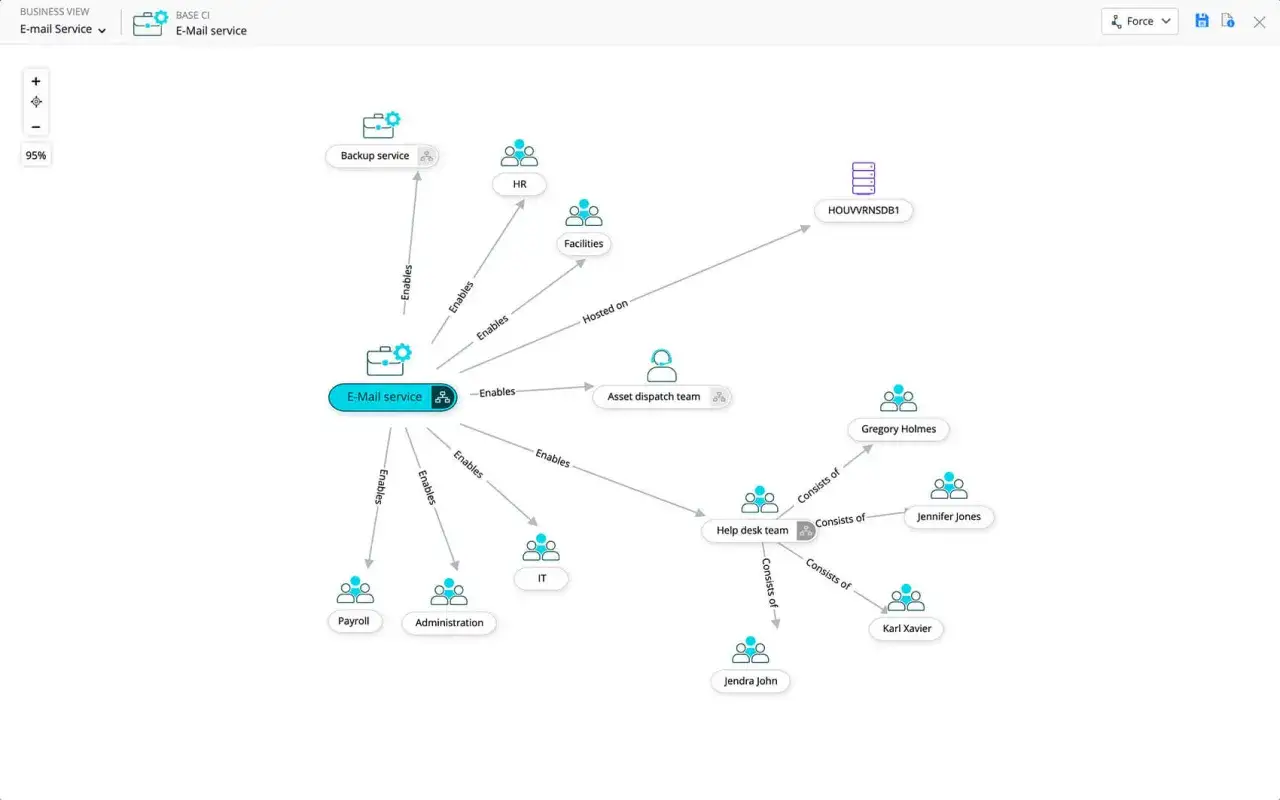
Jak CMDB wspiera backend i DevOps
W zespołach backendowych i DevOps CMDB jest najbardziej użyteczna tam, gdzie zmiany są częste, a zależności rozproszone. Nie chodzi o biurokrację, tylko o to, żeby przed wdrożeniem albo podczas awarii wiedzieć, które usługi i komponenty są naprawdę powiązane.
- Zmiana w API - widzisz, które frontendy, integracje i joby korzystają z danego endpointu.
- Incydent w bazie danych - szybciej oceniasz, które usługi mogą mieć opóźnienia albo błędy.
- Wdrożenie w chmurze - rozumiesz, czy nowy klaster lub namespace nie dzieli zasobów z krytycznym środowiskiem.
- Root cause analysis - zamiast sprawdzać wszystko po kolei, zawężasz obszar problemu do realnych zależności.
To szczególnie ważne w architekturach mikroserwisowych, gdzie pojedynczy problem rzadko pozostaje lokalny. Jedna słaba konfiguracja potrafi odbić się na kilku usługach naraz, a CMDB pomaga ten łańcuch zobaczyć. W środowiskach opartych na Pythonie, na przykład przy aplikacjach FastAPI lub Django, dochodzą jeszcze zależności od brokera kolejki, cache i warstwy danych, więc pełny obraz ma realną wartość operacyjną. Gdy rozdzielisz te role, łatwiej odróżnić CMDB od innych narzędzi i nie przypisać jej zadań, których po prostu nie powinna dźwigać.
CMDB, ITAM i monitoring rozwiązują różne problemy
W praktyce najczęstszy błąd polega na mieszaniu tych trzech warstw. Monitoring może powiedzieć, że CPU skoczył do 95%, ale nie pokaże pełnego kontekstu biznesowego. ITAM powie, kto kupił serwer i kiedy kończy się licencja, ale nie wyjaśni, które usługi się na nim opierają. CMDB odpowiada na pytanie: co się stanie, jeśli ruszę ten element?
| Obszar | Na jakie pytanie odpowiada | Typowe dane | Po co to jest |
|---|---|---|---|
| CMDB | Co zależy od czego i jaki będzie skutek zmiany? | Elementy konfiguracji, relacje, właściciele, topologia usług | Zmiany, incydenty, analiza wpływu |
| ITAM | Co posiadamy, kto za to odpowiada i jaki ma cykl życia? | Licencje, zakupy, lokalizacja, amortyzacja | Kontrola kosztów i zgodność |
| Monitoring | Czy usługa działa teraz? | Metryki, logi, alerty, SLI/SLO | Wykrywanie anomalii i reakcja na awarie |
To rozróżnienie ma znaczenie, bo każde z tych narzędzi ma inny rytm życia. Monitoring jest dynamiczny, ITAM jest bardziej finansowo-operacyjny, a CMDB ma dostarczać kontekstu. Jeśli próbujesz zrobić z niej wszystko naraz, zwykle kończysz z danymi, którym nikt nie ufa. Żeby tego uniknąć, trzeba zbudować model, który zaczyna od realnych potrzeb zespołu, a nie od ambicji opisania całej infrastruktury w jednym kroku.
Jak zbudować sensowną CMDB bez biurokracji
Jeśli zaczynasz od zera, nie próbuj opisać całej organizacji jednym ruchem. W dobrze działających wdrożeniach CMDB rośnie od usług krytycznych, a nie od katalogu wszystkiego, co istnieje w sieci.
Zacznij od usług, nie od sprzętu
Najpierw wybieram kilka usług produkcyjnych, które naprawdę bolą przy awarii: płatności, logowanie, kolejki, API dla partnerów, dane klienta. Dopiero potem dołączam komponenty wspierające. Taki porządek pomaga utrzymać sens modelu, bo każda pozycja ma biznesowy powód, by w nim być.
Modeluj zależności, które zmieniają decyzje
Nie każda relacja jest równie ważna. W CMDB warto utrzymywać te powiązania, które realnie wpływają na zmianę, awarię lub odpowiedzialność: usługa do bazy danych, aplikacja do klastra, API do kolejki, system do dostawcy zewnętrznego. Jeśli relacja nic nie wnosi, zwykle tylko zwiększa szum.
Zasilaj dane automatycznie
Ręczne wpisy sprawdzają się na starcie, ale szybko stają się wąskim gardłem. Lepszy kierunek to integracje z narzędziami wdrożeniowymi, chmurą, orkiestracją, monitoringiem i discovery, czyli automatycznym wykrywaniem zasobów w środowisku. Dzięki temu CMDB żyje razem z systemem, zamiast starzeć się z dnia na dzień. Warto też myśleć o federacji danych, czyli pobieraniu wybranych informacji z innych systemów zamiast kopiowania wszystkiego do jednego miejsca.
Przeczytaj również: REST API w praktyce - Jak budować przewidywalne integracje?
Ustal właścicieli i rytm przeglądu
Każdy kluczowy element konfiguracji powinien mieć właściciela, a dane powinny wracać do przeglądu w określonym rytmie. Bez tego szybko pojawia się klasyczny problem: nikt nie wie, kto ma poprawić nieaktualny rekord, więc nikt tego nie robi. Do tego dochodzi drift konfiguracyjny, czyli rozjazd między stanem zapisanym a rzeczywistym, który przy braku automatyzacji rośnie wyjątkowo szybko.
A kiedy model już rośnie, najłatwiej zepsuć go kilkoma powtarzalnymi błędami.
Najczęstsze błędy, które zamieniają CMDB w martwy katalog
- Próba opisania wszystkiego - rośnie koszt utrzymania, a wartość biznesowa nie nadąża.
- Brak automatyzacji - dane są nieaktualne po pierwszym większym wdrożeniu.
- Brak relacji między elementami - rekordy istnieją, ale nie pomagają przy analizie wpływu.
- Brak właścicieli - nikt nie odpowiada za poprawność danych.
- Oderwanie od procesów change i incident - CMDB istnieje, ale nikt z niej nie korzysta.
Kiedy CMDB daje realną przewagę, a kiedy lepiej ją odchudzić
- Ma sens, gdy środowisko ma wiele zależności, częste wdrożenia i kilka warstw usług.
- Jest mocno przydatna, gdy incydenty rozlewają się na kilka komponentów i trzeba szybko ocenić zasięg problemu.
- Sprawdza się najlepiej, gdy jest selektywna i federacyjna, czyli pobiera dane z innych systemów zamiast dublować wszystko ręcznie.
- W środowiskach cloud-native trzeba uwzględniać zasoby efemeryczne, kontenery i komponenty, które zmieniają się szybciej niż klasyczny sprzęt.
- Bywa zbędnie ciężka w małych, stabilnych środowiskach, gdzie prosty inventory i solidny monitoring załatwiają większość potrzeb.
Jeżeli miałbym zamknąć temat jednym zdaniem, powiedziałbym tak: dobra CMDB nie wygrywa rozmiarem, tylko jakością relacji i aktualnością danych. W praktyce to ona decyduje, czy zespół widzi środowisko jako zbiór przypadkowych komponentów, czy jako działający system z przewidywalnymi skutkami zmian. I właśnie w tym sensie CMDB jest dla backendu i DevOps narzędziem operacyjnym, a nie tylko formalnym dodatkiem do procesu.