Tree shaking to technika, która usuwa z produkcyjnej paczki JavaScript kod, z którego aplikacja faktycznie nie korzysta. W praktyce daje krótsze ładowanie, mniejszy koszt parsowania skryptów i mniej pracy na głównym wątku, co bezpośrednio wpływa na odczuwalną szybkość interfejsu. Pokażę, jak to działa, kiedy zawodzi i co robię w projekcie, żeby ta optymalizacja naprawdę miała sens.
Najkrócej: chodzi o mniejszy bundle i mniej zbędnego kodu
- Mechanizm działa najlepiej z modułami ES i statycznymi importami.
- Nie zastępuje minifikacji ani code splittingu, bo rozwiązuje inny problem.
- Najwięcej psują go CommonJS, efekty uboczne i błędna konfiguracja bundlera.
- W UX i UI największy zysk widać tam, gdzie interfejs ładuje dużo komponentów i bibliotek naraz.
- Efekt trzeba mierzyć na buildzie produkcyjnym, a nie „na oko”.
Na czym polega usuwanie zbędnego kodu
W skrócie: bundler buduje graf zależności, sprawdza, które eksporty są rzeczywiście użyte, i odcina resztę, jeśli moduł nie robi nic istotnego przy samym imporcie. MDN i dokumentacja webpacka opisują ten mechanizm jako eliminację martwego kodu na podstawie statycznej struktury modułów. To ważne rozróżnienie, bo tutaj nie chodzi o sprzątanie pamięci w przeglądarce, tylko o etap buildu, zanim użytkownik zobaczy stronę.
Ja patrzę na to tak: jeśli moduł jest czysty, a jego eksporty są jednoznaczne, bundler ma jasny sygnał, co można wyrzucić. Jeśli kod uruchamia coś „przy okazji” importu, na przykład rejestruje globalny stan albo odpala inicjalizację, analiza staje się dużo ostrożniejsza. Wtedy oszczędność może być mniejsza albo żadna.
To właśnie dlatego nie wystarczy powiedzieć, że aplikacja „ma optymalizację”. Trzeba jeszcze wiedzieć, z jakiego typu modułów korzysta i czy build potrafi je bezpiecznie odczytać. Gdy to rozumiesz, łatwiej odróżnić realny efekt od marketingowego skrótu myślowego.
Czym różni się od minifikacji i code splittingu
Te trzy pojęcia są często wrzucane do jednego worka, a to błąd. Minifikacja zmniejsza zapis kodu, na przykład usuwa spacje, skraca nazwy lokalne i upraszcza składnię. Code splitting dzieli aplikację na kawałki ładowane osobno. Mechanizm usuwania zbędnego kodu robi coś innego: odcina fragmenty, których nikt nie używa, zanim trafią do paczki produkcyjnej.
| Technika | Co robi | Kiedy daje największy efekt |
|---|---|---|
| Minifikacja | Skraca i upraszcza zapis kodu | Na każdym projekcie, ale zwykle oszczędza mniej niż eliminacja nieużywanych modułów |
| Code splitting | Dzieli aplikację na osobne chunki | W rozbudowanych interfejsach, panelach administracyjnych i aplikacjach z wieloma widokami |
| Eliminacja martwego kodu | Usuwa nieużywane eksporty lub całe moduły | W bibliotekach komponentów, dużych utilach i design systemach |
Najlepszy wynik daje zwykle połączenie wszystkich trzech rzeczy, ale nie należy ich mylić. Sama minifikacja nie uratuje projektu, który ładuje połowę biblioteki „na wszelki wypadek”. To właśnie tu zaczyna się praktyczna praca nad frontem, a nie tylko nad jego rozmiarem.
Jak pisać moduły, które dają się analizować
Jeśli chcesz, żeby bundler miał z czego wycinać zbędny kod, zacznij od struktury modułów. W praktyce najlepiej działają moduły ES z jasnymi, statycznymi importami i eksportami. Dokumentacja webpacka podkreśla też znaczenie pola sideEffects w package.json, bo to ono pomaga odróżnić pliki bez skutków ubocznych od tych, które trzeba zachować.
| Wzorzec | Wpływ na analizę | Moja uwaga |
|---|---|---|
| ESM z jawnie nazwanymi eksportami | Bardzo dobry | Bundler widzi zależności bez zgadywania |
CommonJS z require i module.exports
|
Słaby | Statyczna analiza jest dużo trudniejsza |
| Czysty moduł bez efektów ubocznych | Bardzo dobry | Całość może zniknąć, jeśli nikt jej nie importuje |
| Moduł, który przy imporcie rejestruje globalny stan | Ostrożnie | Trzeba go oznaczyć jako wyjątek w sideEffects
|
| Transpilacja ESM do CommonJS w buildzie | Problemowa | Potrafi wyłączyć część optymalizacji jeszcze przed bundlowaniem |
Dobry, prosty przykład wygląda tak:
// math.js
export function square(x) {
return x * x;
}
export function cube(x) {
return x * x * x;
}
// main.js
import { square } from './math.js';
console.log(square(5));Jeśli aplikacja używa tylko square, bundler może pominąć cube, o ile cały moduł pozostaje czysty. Właśnie w takich drobiazgach widać różnicę między kodem, który „da się zbudować”, a kodem, który faktycznie wspiera optymalizację. I tu zaczynają się najczęstsze pułapki.
Kiedy tree shaking nie działa tak, jak oczekujesz
Największy problem zwykle nie leży w samym bundlerze, tylko w drodze, jaką kod przechodzi po drodze do produkcji. Jeśli gdzieś pośrodku ESM zostanie zamieniony na CommonJS, analiza traci precyzję. Jeśli moduł ma skutki uboczne, bundler nie może go bezpiecznie odrzucić. Jeśli do tego dojdzie błędne ustawienie sideEffects, można przypadkiem uciąć CSS, polyfille albo rejestrację komponentów.
- CommonJS w pipeline - utrudnia statyczną analizę i zmniejsza skuteczność optymalizacji.
- Skutki uboczne przy imporcie - wymuszają zachowanie modułu, nawet jeśli nic z niego nie jest używane.
-
Zbyt agresywne
sideEffects: false- może wyciąć potrzebne style, inicjalizację lub kod globalny. - Re-exporty w gęstych plikach pośrednich - nie zawsze psują wynik, ale utrudniają zrozumienie, co naprawdę ląduje w paczce.
- Sprawdzanie tylko dev builda - myli, bo produkcyjna konfiguracja działa inaczej.
W praktyce jedna z najlepszych rzeczy, jakie można zrobić, to przejrzeć ścieżkę kompilacji od źródeł aż do bundle i sprawdzić, czy po drodze nie ginie informacja o module. Gdy ta warstwa jest uporządkowana, można sensownie ocenić wpływ na doświadczenie użytkownika.
Dlaczego to ma znaczenie dla UX i UI
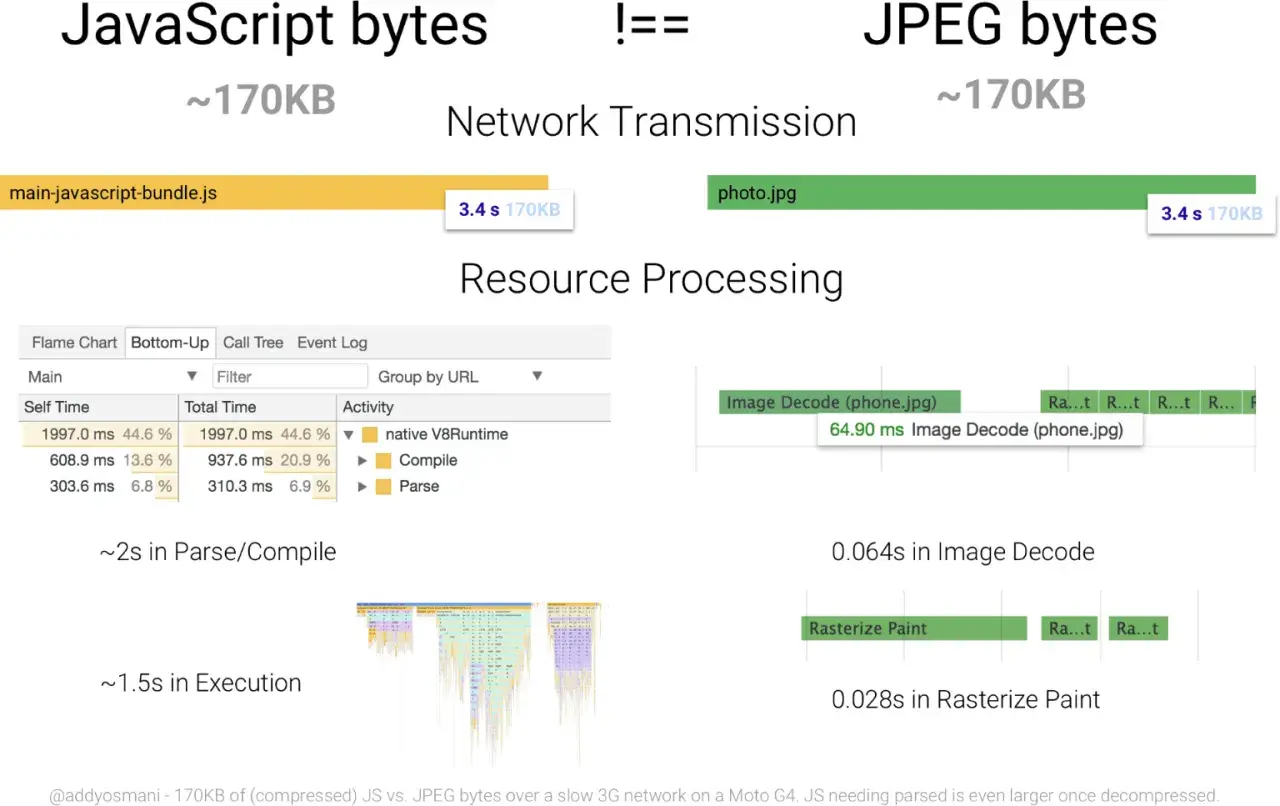
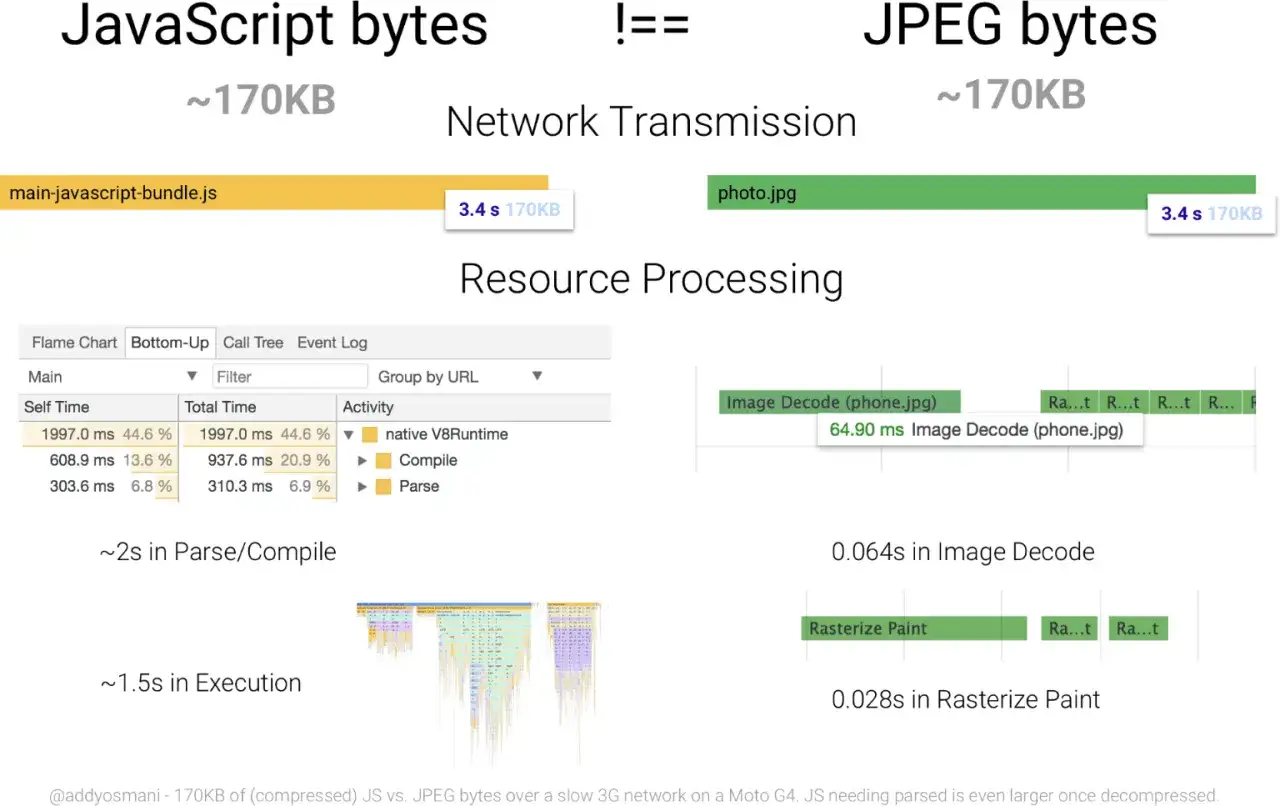
W frontendzie rozmiar paczki nie jest tylko techniczną ciekawostką. Mniej kodu do pobrania i wykonania oznacza zwykle krótszy czas do pierwszej interakcji, mniejsze obciążenie głównego wątku i mniej szarpnięć przy przewijaniu czy klikaniu. Dla użytkownika to po prostu bardziej responsywny interfejs.
Najwięcej zyskują projekty, które noszą na plecach dużo elementów UI, ale używają tylko części z nich. Widziałem to szczególnie w design systemach, bibliotekach ikon, dużych zestawach helperów i aplikacjach dashboardowych, gdzie na jednej stronie ląduje zbyt wiele rzeczy naraz. Jeśli UI wygląda lekko, ale skrypt jest ciężki, użytkownik i tak odczuwa opóźnienie. Wizualna elegancja nie przykryje wolnej reakcji na akcję.
- Landing page - zysk bywa umiarkowany, bo główny problem częściej siedzi w obrazach, fontach lub skryptach zewnętrznych.
- Panel administracyjny - zysk jest większy, bo aplikacja zwykle importuje dużo komponentów, utili i integracji.
- Design system - każda nadmiarowa zależność ma znaczenie, bo biblioteka trafia do wielu miejsc naraz.
To dobry przykład na to, że wydajność frontendowa i jakość UX są ze sobą sprzężone. Kiedy interfejs reaguje szybciej, użytkownik ma wrażenie większej płynności, nawet jeśli sam nie widzi, co dokładnie zostało usunięte z bundle. Dlatego warto sprawdzać efekt nie tylko w megabajtach, ale też w realnym zachowaniu strony.
Jak sprawdzić efekt w praktyce
Ja zawsze zaczynam od builda produkcyjnego, bo tylko on pokazuje prawdziwy obraz sytuacji. Potem patrzę na strukturę paczki i sprawdzam, czy to, co zniknęło, rzeczywiście było zbędne, a nie tylko przypadkiem niewidoczne w konkretnej ścieżce testowej. Przydatne są tu narzędzia takie jak webpack-bundle-analyzer, source-map-explorer albo wizualizery dla Rollupa.
| Narzędzie | Po co go używam |
|---|---|
webpack-bundle-analyzer |
Do zobaczenia, które pakiety i moduły zajmują najwięcej miejsca |
source-map-explorer |
Do śledzenia, skąd dokładnie bierze się rozmiar kodu |
| Chrome Coverage | Do sprawdzenia, ile kodu w danej sesji zostało faktycznie użyte |
Patrzę na trzy rzeczy naraz: rozmiar paczki, koszt wykonania skryptu i to, czy po zmianie nie ucierpiała funkcjonalność. Jeśli bundle zmalał, ale interfejs dalej działa tak samo wolno, to znaczy, że problem leży gdzie indziej. Wtedy bardziej opłaca się szukać ciężkich zależności, niepotrzebnych inicjalizacji albo zbyt późno ładowanych komponentów.
To prowadzi do ostatniego kroku, czyli krótkiej listy rzeczy, które sprawdzam przed wypchnięciem frontendu na produkcję.
Co sprawdzam przed wdrożeniem na produkcję
Gdybym miał zostawić tylko jedną praktyczną checklistę, wyglądałaby tak:
- Czy build produkcyjny faktycznie działa na modułach ES od początku do końca?
- Czy w projekcie nie ma niepotrzebnej konwersji do CommonJS po drodze?
- Czy pliki z efektami ubocznymi są jawnie oznaczone w
sideEffects? - Czy CSS, polyfille i kod inicjalizacyjny zostały wyłączone z agresywnego wycinania?
- Czy po zmianie zmalała tylko paczka, czy także czas reakcji interfejsu?
- Czy test na słabszym urządzeniu daje ten sam obraz, co test na mocnym laptopie?
Jeśli miałbym streścić całą praktykę w jednym zdaniu, powiedziałbym tak: najpierw porządny model modułów, potem dopiero optymalizacja. Sama technika nie naprawi przeładowanego frontendu, ale dobrze wdrożona potrafi wyraźnie odchudzić paczkę i poprawić odczucie szybkości. W projektach UI właśnie to zwykle robi największą różnicę.