
AWS Fargate pozwala uruchamiać kontenery bez zarządzania serwerami, ale to nie jest „magia bez obowiązków”. W praktyce zyskujesz mniej pracy operacyjnej, prostsze wdrożenia i szybsze skalowanie, a jednocześnie nadal musisz dobrze dobrać CPU, pamięć, sieć i uprawnienia. W tym artykule rozkładam temat na części: jak działa to w ECS i EKS, ile kosztuje, gdzie ma sens oraz kiedy lepiej wybrać inną ścieżkę.
Najważniejsze fakty o uruchamianiu kontenerów bez serwerów
- AWS Fargate odciąża z zarządzania hostami, ale nie zwalnia z decyzji o CPU, pamięci, sieci i IAM.
- W ECS każdy task działa na własnym ENI, a w EKS trzeba zdefiniować profil Fargate dla namespace lub etykiet.
- Rozliczenie jest sekundowe, z 1-minutowym minimum; dodatkowy storage i publiczne adresy IPv4 mogą podnieść koszt.
- Najlepiej sprawdza się przy API, workerach, mikrousługach i ruchu o zmiennym profilu.
- Słabiej pasuje do scenariuszy z daemonami, privileged containers, GPU, host networking i ciężkim toolingu node-level.
Czym jest Fargate i co naprawdę upraszcza
Fargate od AWS jest serwerlessowym silnikiem obliczeniowym dla kontenerów. W praktyce oznacza to, że nie stawiasz, nie łatasz i nie skalujesz własnych instancji EC2 tylko po to, żeby uruchomić task albo pod. Orkiestracja nadal należy do ECS albo EKS, ale warstwa infrastruktury schodzi z Twojej głowy.
Ja patrzę na to tak: Fargate dobrze sprawdza się wtedy, gdy chcesz skupić się na aplikacji, a nie na utrzymaniu klastra. Nadal definiujesz obraz kontenera, porty, zmienne środowiskowe, pamięć, CPU, IAM i polityki sieciowe. Znika natomiast cała obsługa hostów, patchowania systemu, doboru rozmiaru nodów i planowania pojemności.
To jest ważne rozróżnienie, bo Fargate nie zwalnia z architektury. Jeśli obraz jest ciężki, logów jest za dużo, a aplikacja nie reaguje dobrze na SIGTERM, problem zostanie, tylko będzie działał na mniej widocznej warstwie. Największa korzyść polega więc nie na „braku DevOps”, lecz na redukcji operacyjnego tarcia.
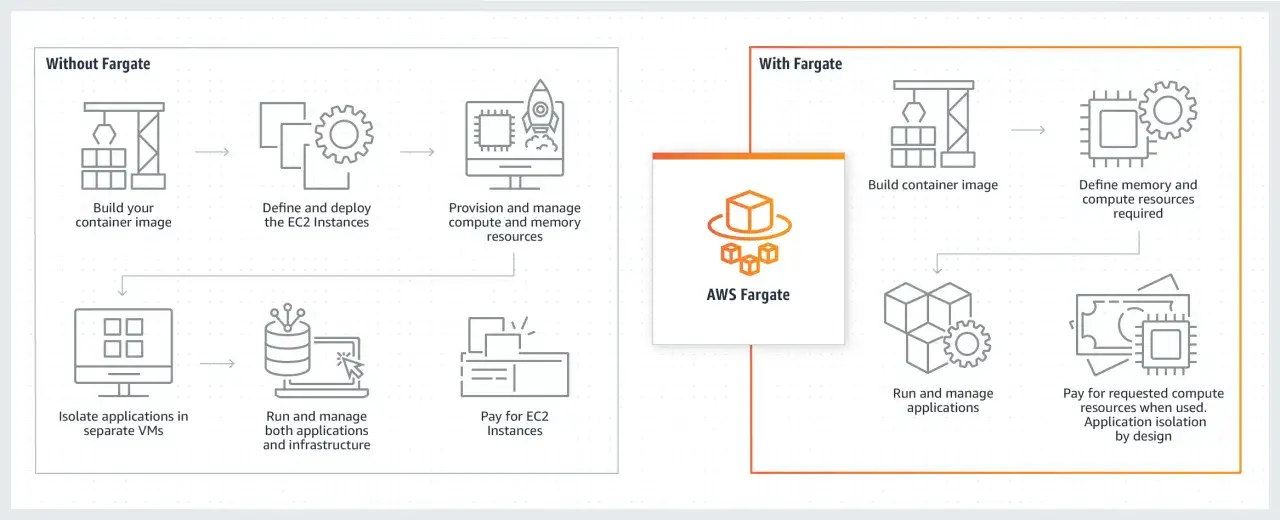
Jak działa to w ECS i EKS
Najprościej: ECS i EKS decydują co ma działać, a Fargate dostarcza na czym to działa bez Twojego udziału w zarządzaniu hostem. Różnica między tymi dwoma torami jest istotna, bo w każdym z nich konfiguracja wygląda inaczej.
W ECS
W Amazon ECS task na Fargate wymaga trybu awsvpc, czyli każdy task dostaje własną elastyczną kartę sieciową ENI. To upraszcza izolację i reguły bezpieczeństwa, ale oznacza też, że musisz wskazać subnety i security groups. Jeśli deployujesz usługę w subnetach publicznych, możesz przydzielić publiczny adres IP. Jeśli zostajesz w prywatnych, przygotuj NAT albo prywatne endpointy do usług, z których task musi korzystać.
W praktyce oznacza to zwykle taki przepływ: budujesz obraz, wypychasz go do rejestru, definiujesz task definition z CPU, pamięcią, logowaniem i rolą IAM, a potem uruchamiasz service. Same kontenery w obrębie jednego taska mogą rozmawiać przez localhost, co bywa wygodne przy sidecarach.
Przeczytaj również: REST API w praktyce - Jak budować przewidywalne integracje?
W EKS
W Amazon EKS nie wybierasz po prostu „włącz Fargate” i koniec. Najpierw tworzysz Fargate profile, czyli regułę, która mówi, które namespace’y lub etykiety mają być planowane na Fargate. Do tego dochodzi pod execution role, bo infrastruktura uruchamiająca pod musi mieć prawo pobrać obrazy, odczytać sekrety i wykonać wymagane akcje w AWS.
Tu ważne są też subnety. Pods na Fargate w EKS działają w prywatnych subnetach i nie dostają publicznych adresów IP. Jeśli pod nie pasuje do profilu w momencie planowania, może utknąć w stanie Pending. To jeden z tych szczegółów, które lubią zaskoczyć przy pierwszym wdrożeniu.
Wniosek jest prosty: w ECS konfigurujesz taski i sieć bardziej „aplikacyjnie”, a w EKS musisz dodatkowo pilnować selektorów profili i zasad planowania podów. Następny krok to policzyć, kiedy taki model ma sens finansowy.
Koszty, rozmiary i billing, które warto policzyć wcześniej
Według AWS rozliczenie jest oparte na przydzielonych zasobach: vCPU, pamięci, systemie operacyjnym, architekturze CPU i storage. Liczenie zaczyna się w chwili rozpoczęcia pobierania obrazu, a kończy po zakończeniu taska lub poda, z rozliczeniem sekundowym i minimalnym czasem 1 minuty. Dla Windows minimalny czas rozliczenia wynosi 5 minut. Do tego dochodzi domyślne 20 GB storage ephemeral; wszystko ponad ten limit jest dodatkowo płatne.
Praktyczne znaczenie jest takie: płacisz za to, co zarezerwowałeś, a nie za sam fakt, że kontener chwilowo „czeka”. Dla ruchu skokowego to bywa bardzo wygodne. Dla obciążeń stale wysokich model per-second nie zawsze wygrywa z własnymi nodami, bo rezerwujesz CPU i pamięć cały czas.
| CPU | Dozwolona pamięć | Typowy sens użycia |
|---|---|---|
| 0,25 vCPU | 0,5 GB, 1 GB, 2 GB | Małe API, cron, lekki worker |
| 0,5 vCPU | 1-4 GB | Mała usługa backendowa |
| 1 vCPU | 2-8 GB | Standardowy mikroserwis |
| 2 vCPU | 4-16 GB | Cięższe API, integracje, worker CPU-bound |
| 4 vCPU | 8-30 GB | Większe usługi, większy cache, większe batch'e |
| 8 vCPU | 16-60 GB | Duże procesy przetwarzające |
| 16 vCPU | 32-120 GB | Największe workloady na Fargate |
W ECS możesz też rozważyć Fargate Spot dla zadań odpornych na przerwania. AWS podaje, że pozwala to zejść nawet o 70% względem standardowej ceny Fargate, ale dotyczy to tylko ECS, tylko Linux i tylko x86/ARM. Jeśli masz stałe użycie, warto natomiast sprawdzić Savings Plans, bo dla przewidywalnych obciążeń potrafią dać do 50% oszczędności.
Jeśli więc ktoś pyta mnie, czy Fargate jest „tani”, odpowiadam ostrożnie: bywa bardzo opłacalny operacyjnie, ale finansowo trzeba go liczyć razem z siecią, logami i profilem zużycia. Po kosztach naturalnie pojawia się pytanie o ograniczenia, bo to właśnie one decydują, czy wybór jest bezpieczny.
Ograniczenia i typowe pułapki, które warto znać przed startem
- Jak podaje AWS, EKS Fargate nie wspiera Fargate Spot, więc nie zbudujesz tam taniego, przerywalnego poola w ten sam sposób co w ECS.
- W EKS nie ma wsparcia dla DaemonSetów, kontenerów uprzywilejowanych,
HostNetwork,HostPortani GPU. Jeśli agent monitoringowy albo bezpieczeństwa działa jak daemon, trzeba go przeprojektować. - W EKS pods działają w prywatnych subnetach i nie dostają publicznych IP, więc architektura sieci musi to uwzględnić od początku.
- W ECS Fargate wymagany jest tryb
awsvpc. Jeśli nie przygotujesz subnetów, security groups i drogi do internetu albo endpointów VPC, pull obrazu lub pobieranie sekretów nie ruszy. - Windows containers działają na Fargate w ECS, ale nie na podach EKS. To ważny szczegół przy migracjach starszych aplikacji.
- W EKS Fargate zasoby zadeklarowane w podzie mają realne znaczenie, bo to one determinują, co zostanie aprowizowane. Zbyt ciasne requesty szybko kończą się throttlingiem albo restartami.
- Domyślne 20 GB storage ephemeral wystarcza dla wielu usług, ale przy większych plikach tymczasowych, buforach i buildach trzeba to policzyć wcześniej.
To nie są wady w sensie „usługa jest zła”. To są granice modelu. Ja traktuję je jak filtr: jeśli aplikacja wymaga zachowania hostowego, licznych agentów albo niestandardowej kontroli kernela, Fargate po prostu nie jest właściwym miejscem. To prowadzi do najpraktyczniejszego pytania: kiedy wybrać ten model, a kiedy zostać przy EC2 lub nodach klastra.
Kiedy wybrać Fargate, a kiedy EC2 lub klasyczny EKS na nodach
W praktyce to nie jest decyzja zero-jedynkowa. Często najlepszy układ to mieszanka: część usług na Fargate, część na managed nodes albo EC2. Poniższa tabela pomaga mi szybko ocenić, gdzie leży przewaga.
| Sytuacja | Fargate | EC2 lub nody EKS |
|---|---|---|
| Zmienne obciążenie, skoki ruchu | Dobry wybór, bo łatwiej skalować bez zarządzania hostami | Wymaga więcej strojenia capacity i autoskalowania |
| Stałe, wysokie wykorzystanie | Wygodny operacyjnie, ale nie zawsze najtańszy | Często lepszy koszt jednostkowy |
| Potrzeba daemonów, agentów node-level, privileged containers | Nie pasuje | Pasuje lepiej |
| GPU, specjalistyczny sprzęt, mocna kontrola hosta | Nie jest właściwym wyborem | Lepsza ścieżka |
| Mały zespół backend/DevOps i chęć ograniczenia utrzymania | Bardzo mocny argument za | Więcej pracy operacyjnej |
| Chęć pełnej kontroli nad node'ami i ich tuningiem | Ograniczona kontrola | Większa elastyczność |
Moja reguła jest dość prosta: jeśli usługa ma być po prostu stabilnie uruchomiona, łatwo skalowana i nie wymaga hostowego „grzebania”, Fargate wygrywa wygodą. Jeśli zaś muszę instalować dodatkowe agenty, korzystać z GPU, robić głębokie strojenie albo maksymalnie ciąć koszt przy stałym obciążeniu, wracam do EC2 lub managed nodes. To z kolei naturalnie prowadzi do pytania, jak taki wybór przełożyć na realny backend w Pythonie.
Jak wdrażałbym to w backendzie Pythona
W projektach Pythonowych najczęściej widzę trzy dobre wzorce: API w FastAPI albo Django, osobny worker do zadań w tle i osobny proces do zadań cyklicznych. Na Fargate taki podział ma sens, bo każdy komponent można skalować niezależnie i rozliczać oddzielnie.
- Utrzymuj obrazy małe - bazuj na lekkim obrazie Pythona, usuwaj zbędne zależności i nie pakuj do kontenera narzędzi, których aplikacja nie potrzebuje. Krótszy pull to szybszy start i mniej kosztów sieciowych.
- Dobierz CPU i pamięć z zapasem - małe API często startuje od 0,5 vCPU i 1-2 GB RAM, ale worker Celery, biblioteki ML albo cięższe parsowanie danych mogą potrzebować dużo więcej. Zbyt mały przydział daje throttling albo OOM, a nie oszczędność.
- Obsłuż SIGTERM i health checki - task na Fargate może zostać zatrzymany podczas skalowania albo aktualizacji. Aplikacja powinna zamykać połączenia, domykać kolejki i kończyć requesty bez brutalnego ubicia procesu.
- Oddziel logi, metryki i sekrety - logi wysyłaj do CloudWatch, sekrety trzymaj w Secrets Manager albo SSM, a nie w obrazie. To banalne, ale często decyduje o tym, czy wdrożenie jest bezpieczne i diagnostyczne.
- Planuj sieć od początku - jeśli backend ma gadać z RDS, Redisem, S3 albo ECR, dobrze zaprojektuj subnety, NAT i VPC endpoints. W prywatnej architekturze to nie jest detal, tylko warunek uruchomienia.
- Rozdziel API od workerów - w mojej praktyce jedna usługa obsługująca requesty i kolejkę zadań na jednym kontenerze kończy się szybciej niż osobne task definitions. Lepiej dać API jeden profil, a workerom drugi.
Jeżeli pracujesz z mikroserwisem w Pythonie, to Fargate dobrze pasuje szczególnie do FastAPI + Uvicorn, Celery z SQS lub Redisem oraz krótkich jobów ETL. Nie jest to jednak usprawiedliwienie dla ciężkich, monolitycznych obrazów. Im bardziej przewidywalnie dzielisz komponenty, tym mniej zaskoczeń przy skalowaniu i rozliczeniach.
Po takim wdrożeniu zostaje ostatni etap, który często pomija się w pośpiechu: co sprawdzić przez pierwsze dni działania, żeby nie wyciągać pochopnych wniosków z pierwszej wersji.
Co sprawdziłbym po pierwszym wdrożeniu, żeby nie przepalić czasu i budżetu
- Czas startu tasków - jeśli pull obrazu trwa zbyt długo, zwykle problemem jest zbyt duży image albo zła droga do rejestru.
- Headroom pamięci - obserwuję, czy kontener nie działa stale na granicy limitu. To szybki sygnał, że przydział jest źle dobrany.
- Zużycie logów - nadmiar logowania potrafi generować koszt większy niż sam compute przy małych usługach.
- Networking i egress - jeśli ruch wychodzi poza VPC, sprawdzam NAT, PrivateLink i publiczne IPv4, bo tam często giną pieniądze.
- Zachowanie przy skalowaniu - patrzę, czy aplikacja dobrze znosi wzrost liczby tasków, czy nie ma konfliktów na cache, lockach lub migracjach.
- Różnicę między requestem a limitem - szczególnie w EKS Fargate zbyt ciasne wartości są prostą drogą do niestabilności.
Najlepszy efekt daje zwykle podejście stopniowe: zacząć od jednej usługi, zrozumieć jej profil kosztowy i sieciowy, a dopiero potem przenosić kolejne elementy. Wtedy Fargate naprawdę robi to, do czego został zaprojektowany: upraszcza operacje bez udawania, że architektura przestaje mieć znaczenie.