Warstwa pośrednia przed backendem potrafi uporządkować cały ruch, odciążyć usługi i ujednolicić zasady bezpieczeństwa. W praktyce to api gateway, czyli brama API, która przyjmuje żądania, sprawdza reguły i dopiero potem kieruje je do właściwych usług. W tym tekście pokazuję, jak działa taki punkt wejścia, kiedy naprawdę pomaga, czym różni się od reverse proxy i load balancera oraz jakie błędy najczęściej psują wdrożenie.
Najważniejsze informacje, które pomogą ci ocenić to rozwiązanie
- Brama API stoi między klientem a backendem i przejmuje wspólne polityki, takie jak uwierzytelnianie, limity i routing.
- Największą wartość daje wtedy, gdy masz wiele usług, wielu klientów albo potrzebujesz jednego miejsca do egzekwowania zasad.
- Nie zastępuje całej architektury bezpieczeństwa. Logika domenowa nadal powinna zostać w usługach.
- W praktyce warto rozróżnić ją od reverse proxy, load balancera i service mesh, bo każde z tych narzędzi rozwiązuje inny problem.
- Wybór między modelem zarządzanym a self-hosted wpływa nie tylko na koszty, ale też na kontrolę sieci, zgodność i utrzymanie.
- Najczęstsze awarie wdrożeniowe wynikają nie z technologii, tylko z nadmiaru odpowiedzialności wrzuconej do jednej warstwy.
Czym jest brama API i dlaczego nie jest zwykłym proxy
Najprościej mówiąc, brama API to kontrolowany punkt wejścia do systemu. Zamiast wystawiać każdą usługę osobno, stawiasz jedną warstwę, która przyjmuje ruch z zewnątrz, sprawdza warunki dostępu i kieruje żądanie tam, gdzie powinno trafić. Dzięki temu klient widzi spójny interfejs, a ty możesz zmieniać backend bez rozbijania integracji po stronie aplikacji mobilnej, frontendu czy partnerów biznesowych.
Ja patrzę na tę warstwę jak na mechanizm porządkujący chaos. Gdy system rośnie, szybko pojawiają się różne wersje API, różni konsumenci i różne zasady bezpieczeństwa. Bez centralnego punktu kontroli reguły zaczynają się rozjeżdżać, a debugowanie problemów zajmuje niepotrzebnie dużo czasu.
To właśnie odróżnia ją od zwykłego reverse proxy. Reverse proxy przede wszystkim przekazuje ruch, czasem równoważy obciążenie, ale nie musi rozumieć polityk API ani kontraktu biznesowego. Brama API robi krok dalej, bo egzekwuje zasady, które chcesz stosować konsekwentnie dla całego wejścia do systemu. Skoro to już jasne, zobaczmy, co dokładnie dzieje się z pojedynczym żądaniem.
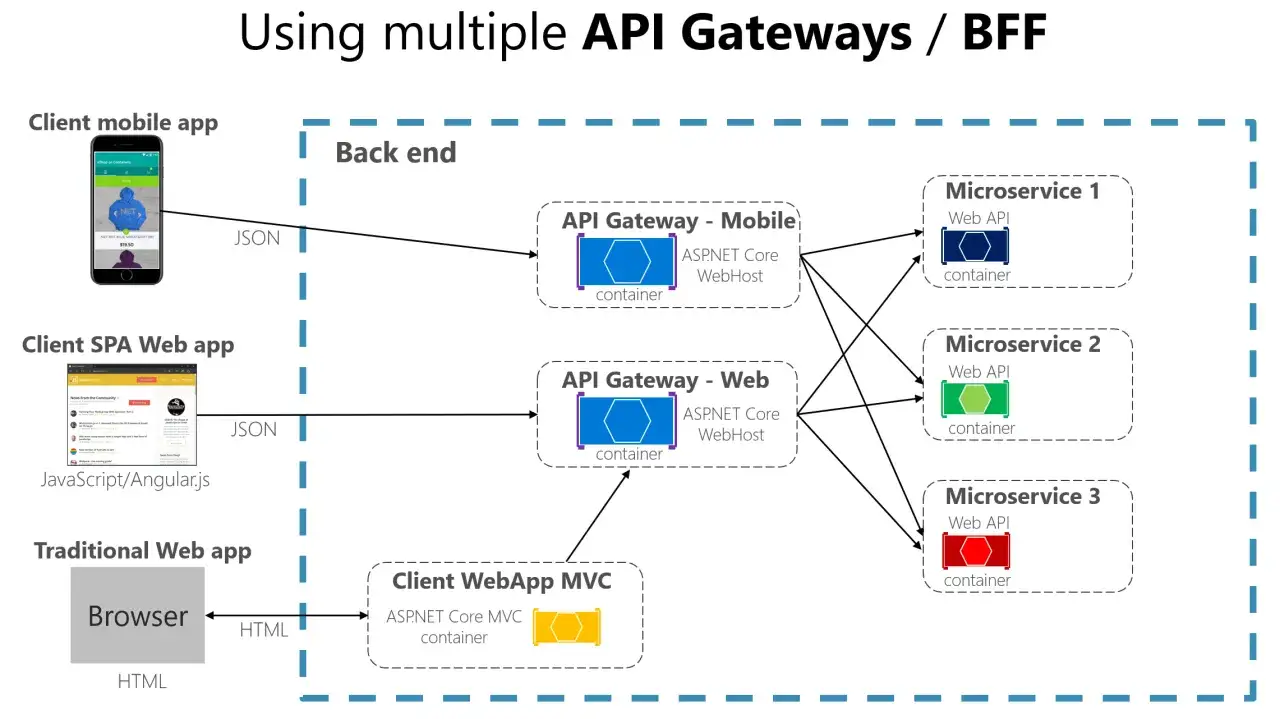
Jak działa żądanie przez warstwę brzegową
Przepływ zwykle wygląda podobnie niezależnie od dostawcy. Klient wysyła request do jednego adresu, a warstwa brzegowa wykonuje serię sprawdzeń zanim puści go dalej. W praktyce oznacza to kilka kroków, które warto rozumieć, bo od nich zależy bezpieczeństwo, wydajność i łatwość utrzymania.
- Identyfikacja klienta na podstawie klucza API, tokenu JWT, certyfikatu albo innego mechanizmu uwierzytelniania.
- Sprawdzenie polityk, czyli zasad dostępu, limitów, dozwolonych metod i ewentualnych reguł zależnych od aplikacji lub partnera.
- Limitowanie ruchu, które chroni backend przed zalewem żądań. Jeśli próg zostanie przekroczony, klient może dostać odpowiedź 429 Too Many Requests.
- Routing do właściwej usługi, wersji API albo konkretnego endpointu.
- Transformacja i odpowiedź, jeśli trzeba zmienić nagłówki, format danych albo scalić odpowiedzi z kilku usług.
- Logowanie i telemetryka, czyli zbieranie logów, metryk i śladów wykonania do monitoringu oraz diagnozy incydentów.
W dokumentacji Google Cloud widać wyraźnie, że taka warstwa pomaga zbierać opóźnienia, ruch i błędy, czyli dane, bez których trudno sensownie prowadzić produkcję. Z kolei w Azure API Management ważny niuans jest taki, że nawet żądania odrzucone przez politykę mogą nadal liczyć się do limitów i rozliczeń w danym planie. To drobiazg, ale w praktyce potrafi zmienić sposób projektowania reguł. Następny krok to odpowiedź na pytanie, co najlepiej przenieść na brzeg, a czego tam nie upychać.
Jakie zadania najlepiej przenieść na bramę
Nie każda odpowiedzialność nadaje się do tej samej warstwy. Najbardziej opłaca się przenosić tam rzeczy wspólne dla wielu usług, czyli takie, które nie są biznesową logiką jednego konkretnego serwisu. Wtedy zyskujesz spójność i ograniczasz duplikację kodu.
| Zadanie | Co daje | Na co uważać |
|---|---|---|
| Uwierzytelnianie i autoryzacja | Jedno miejsce sprawdzania tokenów, kluczy, certyfikatów i ról | Nie zastępuje decyzji domenowych w samych usługach |
| Limity i throttling | Chroni backend przed nadmiarem ruchu i nadużyciami | Zbyt agresywne limity psują integracje partnerów i aplikacji mobilnych |
| Transformacja żądań i odpowiedzi | Ujednolica format danych, nagłówki i wersje kontraktów | Łatwo przesadzić i zrobić z bramy dodatkowy silnik integracyjny |
| Cache | Zmniejsza opóźnienia i odciąża backend przy powtarzalnych odczytach | Trzeba dobrze rozwiązać unieważnianie i spójność danych |
| Obserwowalność | Daje logi, metryki i tracing potrzebne do diagnozy błędów | Bez spójnego identyfikatora żądania analiza incydentu robi się chaotyczna |
| Agregacja odpowiedzi | Łączy dane z kilku usług w jeden prostszy response | To bywa wygodne, ale zwiększa zależność od wielu backendów naraz |
W praktyce dobrze działa zasada, którą sam stosuję dość konsekwentnie: na brzegu zostawiam polityki i mechanikę ruchu, a logikę domenową trzymam w usługach. Jeśli te granice się zacierają, później bardzo trudno rozpoznać, gdzie kończy się infrastruktura, a zaczyna biznes. To prowadzi prosto do porównania z innymi elementami architektury, które często są mylone z bramą API.
Czym różni się od reverse proxy, load balancera i service mesh
Te pojęcia są często wrzucane do jednego worka, a to błąd. Każde z nich rozwiązuje trochę inny problem i jeśli pomylisz ich role, łatwo przepłacisz albo zbudujesz coś, czego zespół nie będzie umiał utrzymać.
| Narzędzie | Główna rola | Kiedy wystarczy | Czego nie rozwiązuje |
|---|---|---|---|
| Reverse proxy | Przekazuje ruch do backendów i często kończy TLS | Gdy potrzebujesz prostego wejścia przed aplikacją | Nie daje pełnego zestawu polityk API i zarządzania kontraktem |
| Load balancer | Rozkłada ruch na zdrowe instancje | Gdy celem jest głównie dostępność i skalowanie | Nie zarządza detalami związanymi z API, wersjami i politykami |
| Brama API | Kontroluje wejście do API, stosuje polityki i routing | Gdy masz wielu konsumentów, limity, autoryzację i wersjonowanie | Nie powinna zastępować całej logiki aplikacji |
| Service mesh | Ułatwia komunikację między usługami wewnątrz klastra i egzekwuje zasady ruchu | Gdy masz rozbudowane mikroserwisy i potrzebujesz kontroli ruchu wewnętrznego | Nie jest zamiennikiem zewnętrznej bramy dla klientów końcowych |
Kiedy wdrożenie ma sens, a kiedy tylko komplikuje architekturę
Nie stawiałbym takiej warstwy wszędzie. Ma największy sens wtedy, gdy system jest już zbyt duży, by zarządzać nim bez wspólnych polityk, ale jeszcze nie tak chaotyczny, by próbować wszystko sklejać ręcznie w usługach.
Najczęściej brama API ma sens, gdy:
- obsługujesz wiele klientów, na przykład web, mobile i partnerów zewnętrznych,
- masz kilka lub kilkanaście usług i chcesz je pokazać jako jeden spójny interfejs,
- musisz egzekwować limity, autoryzację i zasady bezpieczeństwa w jednym miejscu,
- planujesz wersjonowanie API i stopniowe wycofywanie starych endpointów,
- potrzebujesz centralnej obserwowalności ruchu na wejściu do systemu.
Wstrzymałbym się z wdrożeniem, gdy:
- masz mały monolit z kilkoma endpointami i jednym konsumentem,
- zespół nie ma jeszcze procesu utrzymania polityk i konfiguracji,
- nie masz realnej potrzeby wspólnych limitów albo transformacji,
- architektura jest na etapie szybkiego prototypu i każda dodatkowa warstwa spowolni cię bardziej, niż pomoże.
To jest moment, w którym pragmatyzm wygrywa z architektoniczną ambicją. Jeśli warstwa brzegowa nie rozwiązuje konkretnego problemu, tylko wygląda dobrze na diagramie, to zwykle oznacza dodatkowy koszt operacyjny bez proporcjonalnego zwrotu. A skoro koszt operacyjny ma znaczenie, warto porównać modele wdrożenia i utrzymania.
Managed czy self-hosted, czyli jak wybrać model utrzymania
Tu decyzja dotyczy nie tylko technologii, ale też sposobu pracy zespołu. W modelu zarządzanym oddajesz więcej odpowiedzialności dostawcy chmurowego, a w self-hosted przejmujesz większą kontrolę nad miejscem działania, siecią i cyklem życia komponentu.
| Kryterium | Model zarządzany | Self-hosted |
|---|---|---|
| Utrzymanie | Mniej własnej administracji i szybszy start | Więcej pracy po stronie zespołu platformowego |
| Kontrola nad siecią | Mniejsza elastyczność, ale prostsza eksploatacja | Pełniejsza kontrola, przydatna w hybrydzie i on-prem |
| Zgodność i lokalizacja | Wygodne, jeśli region chmurowy spełnia wymagania | Lepiej pasuje do ścisłych wymogów organizacyjnych lub regulacyjnych |
| Skalowanie | Najczęściej prostsze operacyjnie | Zależy od tego, jak dobrze zarządzasz własną infrastrukturą |
| Najlepsze zastosowanie | Publiczne API, szybki rollout, mniejszy zespół DevOps | Środowiska hybrydowe, wewnętrzne strefy sieci, większa kontrola nad ruchem |
W dokumentacji Azure API Management wprost pokazano, że istnieją zarówno gatewaye zarządzane, jak i self-hosted, a w modelu zarządzanym ruch przechodzi przez infrastrukturę dostawcy. To praktyczna różnica, bo wpływa na monitoring, zgodność i odpowiedzialność za awarie. Warto też pamiętać o drobnym, ale kosztownym szczególe: w niektórych planach nawet żądania odrzucone przez polityki mogą liczyć się do limitów i rozliczeń. Jeśli więc masz wrażliwy budżet lub duży ruch testowy, konfiguracja polityk ma znaczenie większe, niż wydaje się na pierwszy rzut oka.
Wybór modelu nie powinien być modą, tylko odpowiedzią na to, gdzie zespół naprawdę chce mieć kontrolę. Gdy ten temat jest jasny, najłatwiej wskazać błędy, które w praktyce najczęściej psują całe wdrożenie.
Najczęstsze błędy, które widzę w projektach
Najwięcej problemów nie bierze się z samej technologii, tylko z tego, że brama dostaje za dużo obowiązków albo za mało uwagi. Poniżej są błędy, które pojawiają się regularnie i zwykle wracają jak bumerang w czasie awarii albo zmian w API.
- Przenoszenie logiki domenowej na brzeg, bo potem każda zmiana biznesowa wymaga grzebania w konfiguracji infrastruktury zamiast w kodzie usługi.
- Brak redundancji, czyli traktowanie bramy jak pojedynczego punktu, który może się wyłożyć i zatrzymać cały ruch.
- Mylenie uwierzytelniania z autoryzacją, bo samo sprawdzenie tokenu nie odpowiada jeszcze na pytanie, czy użytkownik może wykonać konkretną akcję.
- Brak obserwowalności, przez co awaria zamienia się w zgadywanie, a nie w analizę logów, metryk i śladów.
- Zbyt wiele transformacji, bo wtedy brama staje się drugim backendem, którego nikt nie chce utrzymywać.
- Chaotyczne wersjonowanie, które potrafi złamać starszych klientów po drobnej zmianie trasy albo schematu odpowiedzi.
- Niejasny podział odpowiedzialności między zespołem platformowym a zespołami backendowymi, co kończy się sporami o to, kto ma naprawić problem.
To właśnie te błędy najczęściej odróżniają poprawny projekt od rozwiązania, które po roku wszyscy omijają szerokim łukiem. Jeśli chcesz, by brama pomagała zespołowi, musi być przewidywalna, dobrze monitorowana i możliwie nudna w eksploatacji. W przypadku zespołów Python i DevOps kilka dodatkowych zasad robi tu szczególnie dużą różnicę.
Co ustalić przed produkcyjnym uruchomieniem bramy API
Gdy pracuję z backendem w Pythonie, zawsze zaczynam od kontraktu i odpowiedzialności. FastAPI, Django REST Framework czy Flask mogą świetnie działać za bramą, ale tylko wtedy, gdy ta warstwa nie przejmuje zadań, które powinny należeć do aplikacji.
- Ustal właściciela konfiguracji, czyli kto reviewuje zmiany w politykach, trasach i limitach.
- Zdefiniuj wspólny kontrakt, najlepiej w OpenAPI, bo wtedy łatwiej testować zgodność i wersje endpointów.
- Włącz podstawową obserwowalność, czyli logi, metryki, tracing i identyfikator żądania przenoszony przez cały łańcuch.
- Przetestuj zachowanie pod skokiem ruchu, a nie tylko przy spokojnym obciążeniu, bo to właśnie burst często ujawnia problemy z limitami.
- Zaplanuj rollback, żeby błędna polityka albo routing nie wymagały ręcznej walki w środku incydentu.
- Rozdziel odpowiedzialność między brzegiem a usługami, tak by limity i autoryzacja były wspólne, ale decyzje biznesowe zostawały w kodzie aplikacji.
Jeśli miałbym zostawić jedną praktyczną wskazówkę, byłaby prosta: traktuj bramę API jak kontrolowany punkt wejścia, a nie miejsce na wszystko, czego nie chciało się dopisać w usługach. Taka dyscyplina daje lepsze bezpieczeństwo, prostszy monitoring i mniej niespodzianek przy rozwoju systemu, zwłaszcza gdy backend budujesz w Pythonie i utrzymujesz go w zespole DevOps.