
W architekturze mikroserwisów sama komunikacja między usługami szybko staje się równie ważna jak kod biznesowy. Warstwa typu service mesh przenosi część odpowiedzialności za bezpieczeństwo, obserwowalność i sterowanie ruchem do infrastruktury, dzięki czemu zespoły nie muszą powielać tych samych mechanizmów w każdej usłudze.
W tym tekście pokazuję, jak działa taki model, kiedy naprawdę pomaga, czym różni się od bramy API i własnych bibliotek oraz jak podejść do wdrożenia bez dokładania sobie niepotrzebnej złożoności. To temat szczególnie ważny, gdy backend rośnie szybciej niż pojedynczy zespół jest w stanie go „ręcznie” ogarnąć.
Kluczowe informacje, które warto zapamiętać przed decyzją o wdrożeniu
- Największa wartość tej warstwy to spójne zarządzanie ruchem między usługami, a nie tylko szyfrowanie połączeń.
- Model opiera się zwykle na rozdzieleniu płaszczyzny danych od płaszczyzny sterowania.
- Najlepiej sprawdza się w środowiskach mikroserwisowych, zwłaszcza tam, gdzie działa Kubernetes i rośnie liczba zależności.
- Pomaga przy mTLS, obserwowalności, retries, timeoutach i stopniowym wdrażaniu nowych wersji.
- Nie jest dobrym pierwszym krokiem dla małego systemu, w którym problemem nie jest jeszcze komunikacja, tylko podstawowa architektura.
- Wybór między bardziej rozbudowanym a prostszym rozwiązaniem zależy głównie od tego, ile złożoności operacyjnej zespół jest gotowy utrzymać.
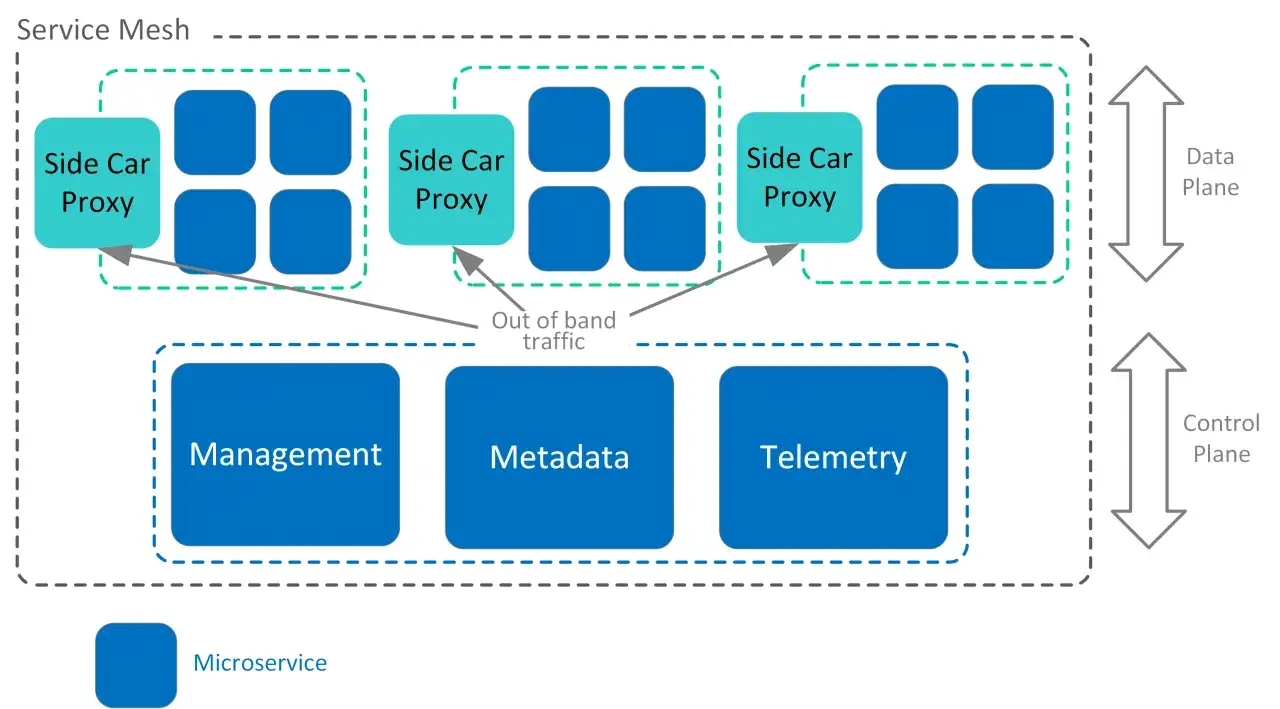
Jak działa warstwa pośrednia między usługami
Najprościej mówiąc, ruch nie idzie już bezpośrednio z usługi A do usługi B. Przechodzi przez proxy, które przechwytuje połączenie, stosuje reguły, zbiera metryki i dopiero potem przepuszcza ruch dalej. W dokumentacji Istio i Linkerd ten model jest opisywany jako rozdzielenie płaszczyzny danych od płaszczyzny sterowania.
Ja traktuję to tak: aplikacja zajmuje się logiką biznesową, a infrastruktura przejmuje zadania „sieciowe”, które w przeciwnym razie trzeba by było implementować w każdym serwisie osobno. To ważne, bo z czasem nie chodzi już tylko o to, żeby usługi się widziały, ale żeby robiły to w przewidywalny, bezpieczny i mierzalny sposób.
Dwie warstwy odpowiedzialności
Płaszczyzna danych obsługuje sam ruch: połączenia, szyfrowanie, retry, timeouty i telemetrię. Płaszczyzna sterowania ustala polityki, rozsyła konfigurację do proxy i pilnuje, żeby cały system zachowywał się spójnie.
| Element | Rola | Po co to wdrażać |
|---|---|---|
| Proxy przy usłudze | Przechwytuje ruch przychodzący i wychodzący | Odciąża kod aplikacji i pozwala stosować wspólne reguły |
| Płaszczyzna sterowania | Zarządza konfiguracją i politykami | Ułatwia centralne wprowadzanie zmian |
| Telemetria | Zbiera metryki, logi i ślady żądań | Pomaga szybko znaleźć opóźnienia i błędy po drodze |
Co dzieje się przy jednym wywołaniu
- Usługa wysyła żądanie do lokalnego proxy, zamiast łączyć się bezpośrednio z inną usługą.
- Proxy sprawdza reguły ruchu, certyfikaty i polityki bezpieczeństwa.
- Po drodze zapisuje metryki, które później widać w dashboardach i alertach.
- Jeśli warunki są spełnione, żądanie trafia do drugiej usługi. Jeśli nie, jest odrzucane albo przekierowywane zgodnie z polityką.
W modelu sidecar zwykle każdy pod dostaje dodatkowy kontener proxy. W nowszych podejściach część odpowiedzialności przenosi się bliżej węzła albo do osobnej warstwy routingu, co może uprościć utrzymanie, ale nie usuwa potrzeby dobrej obserwowalności. Z tego właśnie powodu sama architektura nie wystarcza, jeśli nie wiesz, czym różni się od API gateway i od logiki zapisanej w kodzie.
Czym to się różni od bramy API i własnej biblioteki
Najwięcej zamieszania bierze się z tego, że ludzie wrzucają do jednego worka bramę API, bibliotekę w aplikacji i warstwę pośrednią między usługami. To są trzy różne poziomy odpowiedzialności, a każdy rozwiązuje inny problem.
| Rozwiązanie | Gdzie działa | Najlepiej nadaje się do | Ograniczenie |
|---|---|---|---|
| API gateway | Na brzegu systemu | Ruchu zewnętrznego, autoryzacji klientów, limitów i ekspozycji API | Nie widzi całej komunikacji między mikroserwisami |
| Biblioteka w kodzie | W samej aplikacji | Ścisłej kontroli nad zachowaniem konkretnej usługi | Trzeba utrzymywać to w każdym serwisie osobno |
| Warstwa między usługami | W komunikacji service-to-service | Polityk bezpieczeństwa, retry, telemetrii i sterowania ruchem | Dodaje komponent infrastrukturalny i zwiększa złożoność operacyjną |
W praktyce gateway obsługuje ruch north-south, czyli z zewnątrz do środka, a mesh koncentruje się na ruchu east-west, czyli między usługami. To rozróżnienie jest proste, ale bardzo pomaga przy projektowaniu całego ekosystemu. Jeśli pomylisz te poziomy, szybko zaczniesz rozwiązywać złe problemy w złym miejscu.
Ja zwykle patrzę jeszcze szerzej: jeśli reguła ma dotyczyć wszystkich połączeń między usługami, nie chcę jej duplikować w kodzie. Jeśli dotyczy wejścia z internetu, zaczynam od gateway. Ten porządek myślenia od razu upraszcza rozmowę o kolejnym kroku.
Kiedy taka architektura naprawdę ma sens
To rozwiązanie ma sens wtedy, gdy problem jest systemowy, a nie incydentalny. Innymi słowy, nie wdrażam go dlatego, że „brzmi nowocześnie”, tylko dlatego, że bez wspólnej warstwy ruch między usługami staje się trudny do opanowania.
- Masz wiele usług, a każda inaczej realizuje timeouty, retry i obsługę błędów.
- Potrzebujesz spójnego mTLS, czyli wzajemnego uwierzytelniania i szyfrowania połączeń między usługami.
- Obserwowalność jest rozproszona i trudno odpowiedzieć na proste pytanie, gdzie naprawdę ginie czas.
- Planujesz canary release, traffic mirroring albo stopniowe przełączanie ruchu na nową wersję.
- Pracuje nad systemem kilka zespołów i potrzebujesz wspólnych standardów platformowych.
Są też sytuacje, w których lepiej się zatrzymać. Mały system, kilka usług i mały zespół nie zawsze potrzebują dodatkowej warstwy, która doda kolejne elementy do utrzymania. Jeżeli największym problemem jest jeszcze domena, testy integracyjne albo jakość kontraktów API, to właśnie tam powinien pójść pierwszy wysiłek.
Najuczciwsza ocena jest taka: ta architektura ma sens dopiero wtedy, gdy koszty ręcznego ogarniania ruchu stają się większe niż koszt utrzymania dodatkowej warstwy. A skoro już wiadomo, kiedy jej potrzebujesz, warto zobaczyć, jakie realne zastosowania przynosi w backendzie i DevOps.
Najczęstsze zastosowania, które widać w produkcji
W środowiskach produkcyjnych najwięcej wartości dają trzy obszary: bezpieczeństwo, obserwowalność i sterowanie ruchem. To nie są marketingowe hasła, tylko zadania, które bez takiej warstwy zwykle kończą się duplikacją kodu albo ręcznym klikanem w kilku miejscach naraz.
Bezpieczeństwo bez przepisywania usług
Jeśli chcesz włączyć zero-trust, czyli założenie, że żadne połączenie nie jest z definicji zaufane, mTLS bardzo pomaga. Każda usługa może uwierzytelniać drugą stronę automatycznie, bez dokładania logiki kryptograficznej do logiki biznesowej. To szczególnie ważne tam, gdzie pojawiają się dane wrażliwe, rozliczenia albo wewnętrzne API wykorzystywane przez wiele zespołów.
Obserwowalność, która nie siedzi w aplikacji
Przepływ ruchu między usługami jest dużo łatwiejszy do zrozumienia, gdy metryki są zbierane w jednym miejscu. W praktyce chodzi o latency, liczbę błędów, sukcesy odpowiedzi i korelację śladów rozproszonych. Dzięki temu szybciej widzisz, czy problem leży w konkretnej usłudze, czy w łańcuchu wywołań.
To szczególnie przydatne, kiedy aplikacje piszesz w różnych językach. Niezależnie od tego, czy jedna usługa jest w Pythonie, druga w Go, a trzecia w Javie, warstwa sieciowa zbiera dane w podobny sposób. I właśnie ta niezależność od implementacji robi tu największą różnicę.
Przeczytaj również: Middleware - Jak porządkuje backend i DevOps? Poradnik
Sterowanie ruchem bez pełnego rollout-u
Wdrożenia canary to jeden z najbardziej praktycznych powodów, dla których zespoły sięgają po ten model. Możesz wysłać na nową wersję na przykład 5-10% ruchu, sprawdzić zachowanie, a dopiero potem zwiększać udział. To bezpieczniejsze niż jednorazowe przełączenie wszystkiego i liczenie, że testy wychwyciły każdy przypadek brzegowy.
Ten sam mechanizm przydaje się do mirrorowania ruchu, czyli wysyłania kopii żądań do nowej wersji bez wpływu na użytkownika końcowego. To dobry sposób na test produkcyjnych danych i zachowania systemu, o ile masz dobrze ustawione maskowanie danych wrażliwych oraz sensowne limity obciążenia.
Gdy te trzy obszary są już jasne, pozostaje pytanie praktyczne: które rozwiązanie wybrać, żeby nie kupić sobie zbyt dużej złożoności na start.
Jak wybrać model i narzędzie bez przepalania zespołu
Na rynku najczęściej rozważane są dwa kierunki: bardziej rozbudowany i bardziej minimalistyczny. W praktyce chodzi nie tylko o funkcje, ale też o to, jak dużo pracy operacyjnej zespół jest gotowy brać na siebie każdego dnia.
| Opcja | Kiedy pasuje | Co zyskujesz | Co płacisz w zamian |
|---|---|---|---|
| Istio | Duże klastry, rozbudowane polityki, wiele scenariuszy ruchu | Bardzo szerokie możliwości kontroli i integracji | Większą krzywą uczenia i więcej decyzji architektonicznych |
| Linkerd | Gdy zależy ci na prostszym wejściu i mniejszym narzucie operacyjnym | Przejrzystość, prostsze wdrożenie i skupienie na podstawowych potrzebach | Mniej rozbudowanych scenariuszy niż w bardziej złożonych platformach |
| Bez dodatkowej warstwy | Mały system albo etap, w którym priorytetem jest stabilizacja podstaw | Mniej komponentów do utrzymania | Więcej ręcznej pracy przy bezpieczeństwie, telemetry i ruchu |
Jeśli twoja infrastruktura już stoi na Kubernetes, wejście w ten obszar jest zwykle prostsze. Poza Kubernetesem trzeba bardzo dobrze policzyć koszt integracji, bo dodatkowa warstwa ma sens tylko wtedy, gdy rzeczywiście rozwiązuje realny problem. Dodatkowo w ekosystemie Istio warto rozróżniać klasyczne podejście sidecar od nowszych modeli bez sidecarów, bo to wpływa i na koszty, i na sposób operowania klastrami.
Ja zwykle wybieram prostszy wariant, jeśli zespół jeszcze nie ma dojrzałych procesów observability i zarządzania politykami. Rozbudowane narzędzie nie naprawi braku dyscypliny operacyjnej, tylko go uwidoczni.
Jak wdrażać to bez chaosu i typowych wpadek
Najlepsze wdrożenie zaczyna się od ograniczonego zakresu, a nie od próby objęcia wszystkim wszystkiego naraz. W praktyce najpierw uruchamiam obserwowalność, potem bezpieczeństwo, a dopiero później bardziej złożone reguły ruchu.
- Zacznij od jednego namespace albo jednej domeny ruchu, zamiast od całego klastra.
- Najpierw włącz metryki i śledzenie żądań, żeby zobaczyć, co się naprawdę dzieje.
- Dopiero później dodaj mTLS i polityki dostępu między usługami.
- Standaryzuj timeouty, retry i circuit breaking, czyli odcinanie nadmiernie przeciążonych ścieżek.
- Ustal właściciela konfiguracji, certyfikatów i aktualizacji komponentów proxy.
Najczęstszy błąd to włączenie retry bez limitu. W chwili awarii taki mechanizm potrafi tylko spotęgować ruch i pogorszyć sytuację. Drugi klasyczny problem to próba ukrycia słabych kontraktów między usługami za pomocą reguł sieciowych. To działa krótko, ale długofalowo spowalnia rozwój.
Warto też pilnować jednej rzeczy, o której często się zapomina: ta warstwa nie zastępuje testów integracyjnych ani sensownego versioningu API. Ona pomaga kontrolować komunikację, ale nie naprawia projektu, który od początku był źle podzielony.
Co zostaje po stronie zespołu, gdy sieć przestaje być problemem
Po wdrożeniu zyskujesz spójne reguły komunikacji, lepszą widoczność ruchu i większą kontrolę nad bezpieczeństwem. Ale odpowiedzialność zespołu nie znika, tylko przesuwa się w inne miejsce. Nadal trzeba pilnować kontraktów, testów, wersji i jakości samej domeny.
- Jeśli twoim największym bólem jest obserwowalność i bezpieczeństwo połączeń, taka warstwa ma sens.
- Jeśli największy koszt to już samo utrzymanie platformy, zacznij od prostszego modelu i wróć do tematu po ustabilizowaniu mikroserwisów.
- Jeśli potrzebujesz głównie punktu wejścia dla ruchu zewnętrznego, brama API zwykle wystarczy na początek.
Patrzę na to bardzo pragmatycznie: najlepszy wybór to nie ten z największą liczbą funkcji, tylko taki, który realnie upraszcza codzienną pracę zespołu i nie zasłania błędów aplikacyjnych. Jeśli infrastruktura ma pomóc w utrzymaniu porządku między usługami, musi robić to konsekwentnie, a nie tylko efektownie.