W systemach backendowych najwięcej problemów zwykle nie wynika z samej logiki biznesowej, tylko z jej zbyt mocnego związania z bazą danych, frameworkiem, kolejką albo zewnętrznym API. Właśnie dlatego warto dobrze rozumieć, jak działa architektura heksagonalna: pomaga oddzielić reguły domenowe od technologii, uprościć testy i bezpieczniej rozwijać system, gdy zmienia się sposób komunikacji z otoczeniem. W tym tekście pokazuję, jak ten wzorzec wygląda w praktyce, kiedy naprawdę daje przewagę i jak zastosować go sensownie w projektach backendowych oraz DevOps.
Najważniejsze rzeczy do zapamiętania przed wdrożeniem tego podejścia
- Rdzeń aplikacji powinien znać reguły biznesowe, ale nie powinien znać technologii, przez które te reguły są uruchamiane.
- Porty definiują, czego aplikacja potrzebuje lub co oferuje, a adaptery tłumaczą konkretne technologie na ten kontrakt.
- Największy zysk pojawia się tam, gdzie system ma kilka wejść, kilka wyjść albo częste zmiany infrastruktury.
- W małym CRUD-zie z jedną bazą i jednym API ten wzorzec bywa po prostu zbyt ciężki.
- W Pythonie dobrze sprawdzają się czyste use case'y, interfejsy typu `Protocol` lub `ABC` oraz osobne adaptery dla HTTP, bazy i integracji zewnętrznych.
- W testach i CI najwięcej daje możliwość uruchamiania logiki domenowej bez bazy, sieci i frameworka webowego.
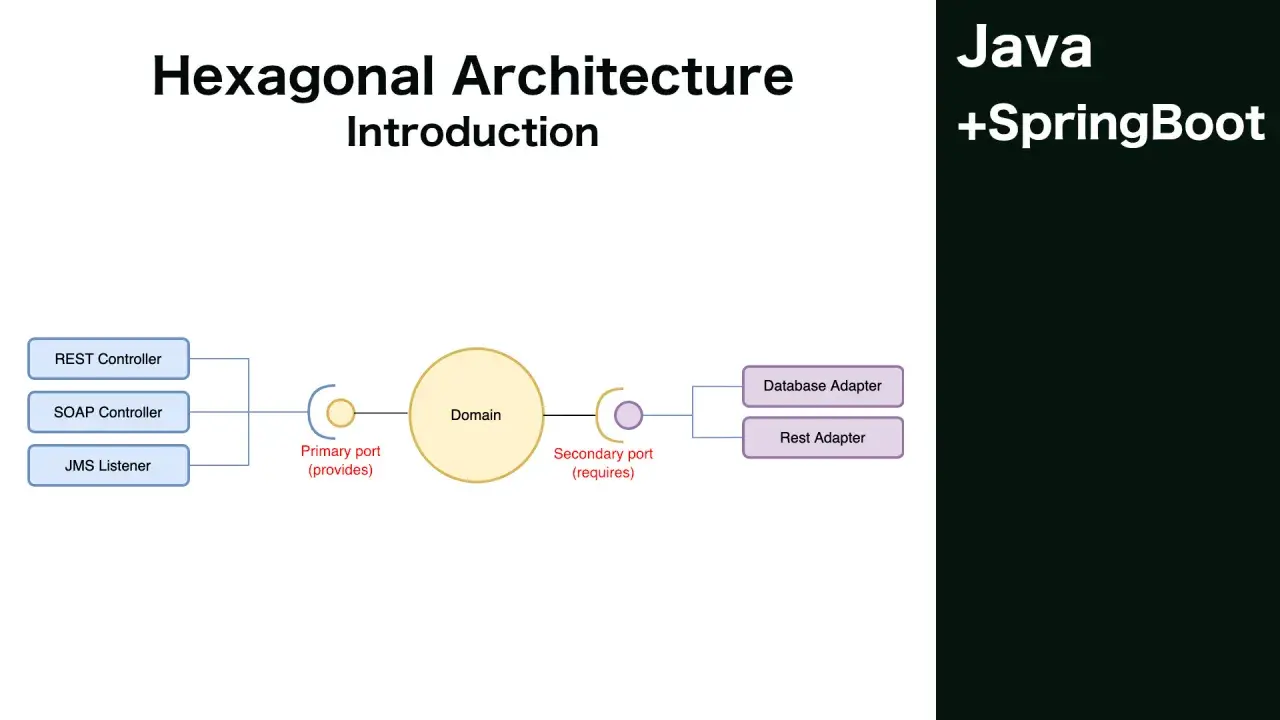
Na czym polega podejście portów i adapterów
Najkrócej mówiąc, chodzi o rozdzielenie tego, co aplikacja robi, od tego, jak komunikuje się ze światem zewnętrznym. W środku zostaje logika biznesowa, czyli reguły zamówień, płatności, rezerwacji, rozliczeń czy walidacji. Na zewnątrz lądują wszystkie zależności techniczne: HTTP, ORM, baza danych, broker wiadomości, SMTP, zewnętrzne API, a nawet konkretne narzędzia testowe.
W praktyce port to kontrakt, a adapter to implementacja tego kontraktu dla konkretnej technologii. Port mówi: „potrzebuję pobrać klienta”, „muszę zapisać zamówienie” albo „chcę uruchomić ten przypadek użycia”. Adapter odpowiada: „zrobię to przez PostgreSQL”, „wyślę to przez REST” albo „obsłużę to przez kolejkę RabbitMQ”. Dzięki temu sam rdzeń aplikacji nie musi wiedzieć, czy dziś rozmawia z bazą lokalną, a jutro z usługą w chmurze.
Ja lubię patrzeć na ten wzorzec nie jak na kolejny modny diagram, ale jak na sposób ograniczania sprzężenia. To szczególnie ważne wtedy, gdy system ma żyć dłużej niż jeden sprint i nie ma być przywiązany do jednego frameworka lub jednej bazy na zawsze. Gdy ta zasada jest już jasna, można zejść poziom niżej i zobaczyć, jak rozkłada się to w realnej aplikacji.
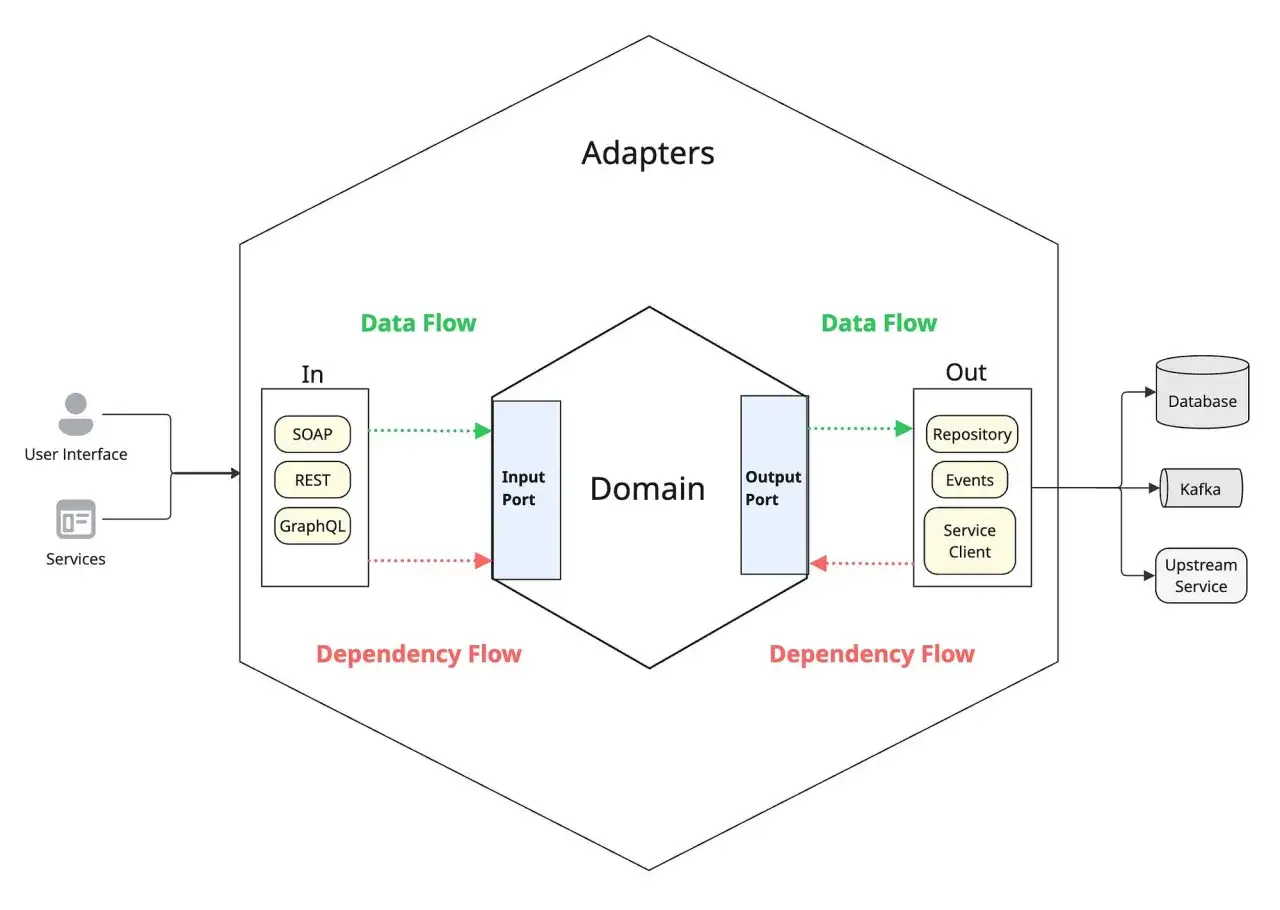
Jak wygląda podział aplikacji w praktyce
Najlepiej widać to na prostym przykładzie backendu do obsługi zamówień. Na wejściu możesz mieć kilka adapterów: endpoint REST, zadanie z kolejki, panel administracyjny albo skrypt CLI. Każdy z nich wywołuje ten sam port wejściowy, czyli przypadek użycia, na przykład „utwórz zamówienie”.
W środku aplikacji znajduje się warstwa use case'ów, która orkiestruje działanie. To ona sprawdza reguły biznesowe, decyduje o przebiegu procesu i korzysta z portów wyjściowych, takich jak repozytorium zamówień, bramka płatności albo serwis powiadomień. Sama nie wie, czy zapis nastąpi do PostgreSQL, SQLite, pamięci, czy przez zewnętrzny ORM. I właśnie o to chodzi.
W praktyce można to rozpisać tak:
- Adapter wejściowy - odbiera żądanie z HTTP, kolejki, CLI albo zadania cyklicznego.
- Port wejściowy - definiuje operację biznesową, np. „zarejestruj użytkownika” albo „zatwierdź płatność”.
- Use case - wykonuje logikę procesu i decyduje, co ma się wydarzyć dalej.
- Port wyjściowy - opisuje zależność potrzebną do realizacji procesu, np. zapis danych, wysyłkę maila, publikację zdarzenia.
- Adapter wyjściowy - konkretnie implementuje port przez bazę danych, API lub brokera wiadomości.
Taki podział jest szczególnie czytelny, gdy system ma kilka kanałów wejścia i kilka miejsc wyjścia. Wtedy zamiast mieszać wszystko w jednym kontrolerze albo serwisie, dostajesz strukturę, którą da się rozwijać etapami. Następny krok to odpowiedź na pytanie, kiedy ten koszt organizacyjny się opłaca.
Kiedy ten wzorzec ma sens, a kiedy tylko komplikuje kod
Nie każdy projekt potrzebuje takiej dyscypliny architektonicznej. Jeśli budujesz niewielkie API CRUD z jedną bazą, jednym kanałem wejścia i minimalną logiką domenową, dodatkowe porty i adaptery mogą być po prostu nadmiarem. Wtedy klasyczna warstwa serwisów i repozytoriów często wystarczy, pod warunkiem że nie rozlewa się po całym projekcie.
Ten wzorzec zaczyna błyszczeć, gdy pojawiają się przynajmniej trzy warunki naraz: kilka sposobów uruchamiania logiki, kilka integracji zewnętrznych i realna szansa zmiany technologii w czasie. Dla mnie to zwykle oznacza systemy z dłuższym życiem, rozbudowaną domeną albo wieloma klientami korzystającymi z tego samego rdzenia biznesowego. W takich projektach izolacja domeny szybko zwraca się w testach, refaktorach i migracjach.
Warto też pamiętać o kompromisie. Każdy adapter to dodatkowy kod do utrzymania, a każdy port to kontrakt, który trzeba rozumieć i testować. Jeśli więc logika biznesowa jest banalna, a infrastruktura nie zmieni się przez lata, lepiej zachować prostotę. Dobrze dobrany wzorzec upraszcza decyzje, ale źle dobrany tylko zwiększa liczbę plików. Z tego miejsca naturalnie przechodzimy do pytania, jak przełożyć to na Python i typowy backend API.
Jak to ułożyć w Pythonie i typowym API
W Pythonie najwygodniej myśleć o tym w kategoriach czystych klas lub funkcji na poziomie domeny oraz cienkich adapterów na brzegu systemu. Framework webowy, taki jak `FastAPI` lub `Flask`, powinien siedzieć przy krawędzi jako adapter wejściowy. ORM, klient poczty, integracja z płatnościami czy publikacja zdarzeń to adaptery wyjściowe.
W samym rdzeniu dobrze sprawdzają się abstrakcje opisane przez `Protocol`, `ABC` albo proste interfejsy domenowe. To nie jest sztuka dla sztuki. Chodzi o to, żeby use case widział tylko kontrakt, na przykład „repozytorium zamówień”, a nie szczegóły implementacji `SQLAlchemy`. Dzięki temu zmiana sposobu zapisu danych nie wymusza przepisywania logiki biznesowej.
Przydatny układ wygląda zwykle tak:
| Element | Rola | Przykład w Pythonie |
|---|---|---|
| Use case | Orkiestruje proces biznesowy | `CreateOrder`, `RegisterUser` |
| Port wejściowy | Definiuje, co można zrobić w aplikacji | Interfejs komendy lub serwisu aplikacyjnego |
| Port wyjściowy | Definiuje zależność potrzebną do wykonania procesu | `OrderRepository`, `PaymentGateway` |
| Adapter wejściowy | Przekłada HTTP, CLI lub kolejkę na wywołanie use case | Router `FastAPI`, consumer wiadomości |
| Adapter wyjściowy | Realizuje port na konkretnej technologii | Repozytorium SQL, klient SMTP, integracja z API |
Jeśli chcesz zachować porządek od pierwszego dnia, trzymaj DTO osobno od modeli domenowych i nie wciskaj encji ORM do środka aplikacji. To jeden z najczęstszych błędów, który po kilku miesiącach zamienia kod w mieszankę frameworka, SQL i logiki biznesowej. Gdy ten podział już działa, największą korzyść odczuwa nie tylko backend, ale też testy i proces wdrożeniowy.
Co zyskuje zespół DevOps, testy i wdrożenia
Z perspektywy DevOps największa zaleta jest prosta: rdzeń biznesowy można testować bez uruchamiania bazy, brokera, zewnętrznego API czy pełnego stosu webowego. To skraca feedback loop i zmniejsza liczbę testów, które trzeba odpalać przy każdej drobnej zmianie. W praktyce oznacza to, że większość logiki możesz sprawdzać jako szybkie testy jednostkowe, a adaptery zostawić dla testów integracyjnych i kontraktowych.
To samo pomaga w pipeline'ach CI/CD. Jeśli use case jest odcięty od infrastruktury, to zmiana adaptera nie powinna wymagać przebudowy całego systemu testów. Łatwiej też prowadzić migracje etapami: najpierw nowy adapter, potem przełączenie ruchu, później wyłączenie starego rozwiązania. Takie podejście zmniejsza ryzyko przy przejściu z jednej bazy, brokera albo dostawcy API na inny.
W praktyce zyskujesz jeszcze trzy rzeczy:
- Lepszą obserwowalność - logowanie, metryki i tracing możesz trzymać na brzegu, bez zaśmiecania domeny szczegółami infrastruktury.
- Łatwiejsze środowiska lokalne - core da się odpalić z adapterami in-memory lub testowymi, bez ciężkiego stacku.
- Mniejsze ryzyko regresji - refaktor interfejsu HTTP nie powinien psuć reguł biznesowych, jeśli granice są dobrze ustawione.
To wszystko działa najlepiej wtedy, gdy naprawdę traktujesz adaptery jako wymienne. Jeśli natomiast wszystko i tak wisi na jednym kontrolerze i jednej klasie repozytorium, efekt będzie dużo słabszy. Właśnie tam zaczynają się najczęstsze błędy wdrożeniowe.
Najczęstsze błędy przy wdrażaniu tego podejścia
Najbardziej typowy błąd to potraktowanie wzorca jak zbioru folderów zamiast zasad zależności. Samo rozdzielenie katalogów nic nie daje, jeśli use case i tak zależy od `FastAPI`, ORM albo konkretnego klienta HTTP. Wtedy na diagramie wszystko wygląda elegancko, ale w kodzie granice są fikcyjne.
Drugi problem to nadmierna abstrakcja. Zdarza się, że zespół tworzy port dla każdej drobnej operacji, potem osobny adapter do wszystkiego i finalnie dostaje system trudniejszy do zrozumienia niż klasyczna warstwa serwisów. Ja wolę mniej kontraktów, ale dobrze nazwanych i sensownie ustawionych. Port ma reprezentować realną potrzebę biznesową, a nie techniczny kaprys.
Trzeci błąd jest bardziej podstępny: logika biznesowa zaczyna wyciekać do adapterów. Kontroler sprawdza reguły, repozytorium liczy rabaty, a integracja zewnętrzna decyduje o przebiegu procesu. To właśnie ten moment, w którym wzorzec przestaje działać, bo rdzeń nie jest już naprawdę niezależny. Warto pilnować, żeby adapter tylko tłumaczył i przekazywał dane, a decyzje zostawały w środku.
Jeśli chcesz uniknąć tych problemów, zacznij od prostego pytania: które elementy systemu naprawdę mogą się zmienić bez naruszania logiki biznesowej? Odpowiedź na nie zwykle podpowiada, gdzie postawić granice. A kiedy te granice już widać, dobrze jest porównać ten model z innymi popularnymi stylami.
Jak wypada na tle klasycznych warstw i clean architecture
Te podejścia są do siebie podobne, ale nie identyczne. Klasyczne warstwy koncentrują się często na przepływie technologicznym, a podejście portów i adapterów bardziej na granicy między wnętrzem aplikacji a otoczeniem. Clean architecture idzie w zbliżonym kierunku, choć mocniej eksponuje regułę zależności i centralność domeny. W praktyce to nie są rywalizujące religie, tylko blisko spokrewnione sposoby myślenia.
| Kryterium | Klasyczne warstwy | Podejście portów i adapterów | Clean architecture |
|---|---|---|---|
| Główna idea | Podział techniczny na warstwy | Oddzielenie wnętrza od otoczenia | Reguła zależności i centrum biznesowe |
| Największa siła | Prostota i czytelność | Wymienność adapterów i testowalność | Ścisła izolacja domeny |
| Typowe ryzyko | Przeciekanie logiki do warstw technicznych | Przerost abstrakcji | Zbyt duża ceremonialność |
| Najlepsze zastosowanie | Małe i średnie aplikacje | Systemy z wieloma integracjami lub zmianami infrastruktury | Złożone domeny i dłuższe życie produktu |
Jeśli mam wybrać praktycznie, to dla prostych projektów stawiam na minimalizm, a dla aplikacji, które mają rosnąć i zmieniać kanały wejścia lub wyjścia, wybieram model heksagonalny. Najważniejsze nie jest to, jak nazwiesz katalogi, tylko czy potrafisz bez bólu podmienić technologię zewnętrzną bez ruszania logiki biznesowej. Z takiego podejścia naturalnie wynika ostatni krok: co warto wdrożyć od razu, nawet jeśli nie chcesz przebudowywać całego systemu.
Co zabrać do projektu już na starcie
Jeśli budujesz nowy backend, nie zaczynaj od wielkiej architektonicznej ceremonii. Wystarczy kilka rozsądnych decyzji, które od razu ustawiają granice:
- wydziel 2-4 kluczowe use case'y zamiast zaczynać od katalogu pełnego ogólnych serwisów;
- zdefiniuj porty wejściowe i wyjściowe na poziomie znaczenia biznesowego, a nie tabeli w bazie;
- trzymaj domenę w czystym Pythonie, bez zależności od frameworka webowego;
- obuduj adaptery testami integracyjnymi, a rdzeń testuj jednostkowo bez infrastruktury;
- nie przenoś reguł biznesowych do kontrolerów, repozytoriów ani klientów API;
- jeśli system jest mały, zacznij od prostoty i dopiero potem dodawaj kolejne granice, gdy naprawdę pojawi się potrzeba.
To podejście działa najlepiej wtedy, gdy jest konsekwentne, ale nie przesadzone. Dobrze użyty model heksagonalny nie robi wrażenia na diagramie, tylko w codziennej pracy: łatwiej zmieniać bazę, prostsze są testy, a zespół nie musi za każdym razem dotykać całego systemu, żeby zmienić jeden adapter. Jeśli o to właśnie chodzi w Twoim backendzie, ten wzorzec daje bardzo konkretną przewagę.