
Amazon SNS to jedna z tych usług, które mocno upraszczają architekturę event-driven. Gdy ktoś pyta o sns co to, najkrótsza odpowiedź brzmi: zarządzany mechanizm pub/sub w AWS, w którym publikujesz zdarzenie raz, a usługa rozsyła je do wielu odbiorców. Dla backendu i DevOps to praktyczny sposób na alerty, integrację mikroserwisów i automatyzację reakcji na zdarzenia.
Amazon SNS rozsyła jedno zdarzenie do wielu odbiorców bez spinania usług na sztywno
- SNS działa w modelu publish/subscribe, więc jeden publisher może uruchomić wiele niezależnych reakcji.
- Najczęściej używa się go do fanout, alertów, webhooków, integracji mikroserwisów i notyfikacji użytkownika.
- To nie jest kolejka ani magazyn wiadomości, więc przy potrzebie buforowania lepsze będzie SQS.
- W praktyce liczą się filtrowanie wiadomości, idempotencja po stronie odbiorców i rozsądne limity payloadu.
- W środowisku Pythonowym SNS zwykle łączy się z `boto3`, Lambda, SQS i CloudWatch.
Czym jest Amazon SNS i po co się go używa
Według dokumentacji AWS Amazon Simple Notification Service jest w pełni zarządzaną usługą, która przekazuje wiadomości od publisherów do subscriberów w sposób asynchroniczny. W praktyce oznacza to, że jedna aplikacja nie musi znać wszystkich odbiorców ani wysyłać do nich komunikatów osobno. Wysyła zdarzenie do topicu, a SNS zajmuje się dalszą dystrybucją.
Ja traktuję SNS jako warstwę rozgłaszania zdarzeń, a nie jako miejsce na logikę biznesową. To dobre rozwiązanie, gdy jedna zmiana ma uruchomić kilka niezależnych działań: zapis do analityki, wysłanie maila, odpalenie Lambdy, zaktualizowanie stanu w innej usłudze albo powiadomienie zespołu operacyjnego.
Warto też odróżnić dwa scenariusze, które AWS opisuje wprost: A2A i A2P. A2A to komunikacja aplikacja do aplikacji, a A2P to komunikacja aplikacja do osoby, na przykład przez e-mail, SMS albo push mobile. To właśnie ta elastyczność sprawia, że SNS tak często pojawia się w backendzie i DevOpsie. Żeby dobrze go używać, trzeba jednak zobaczyć, jak dokładnie przebiega publikacja i dostarczenie wiadomości.
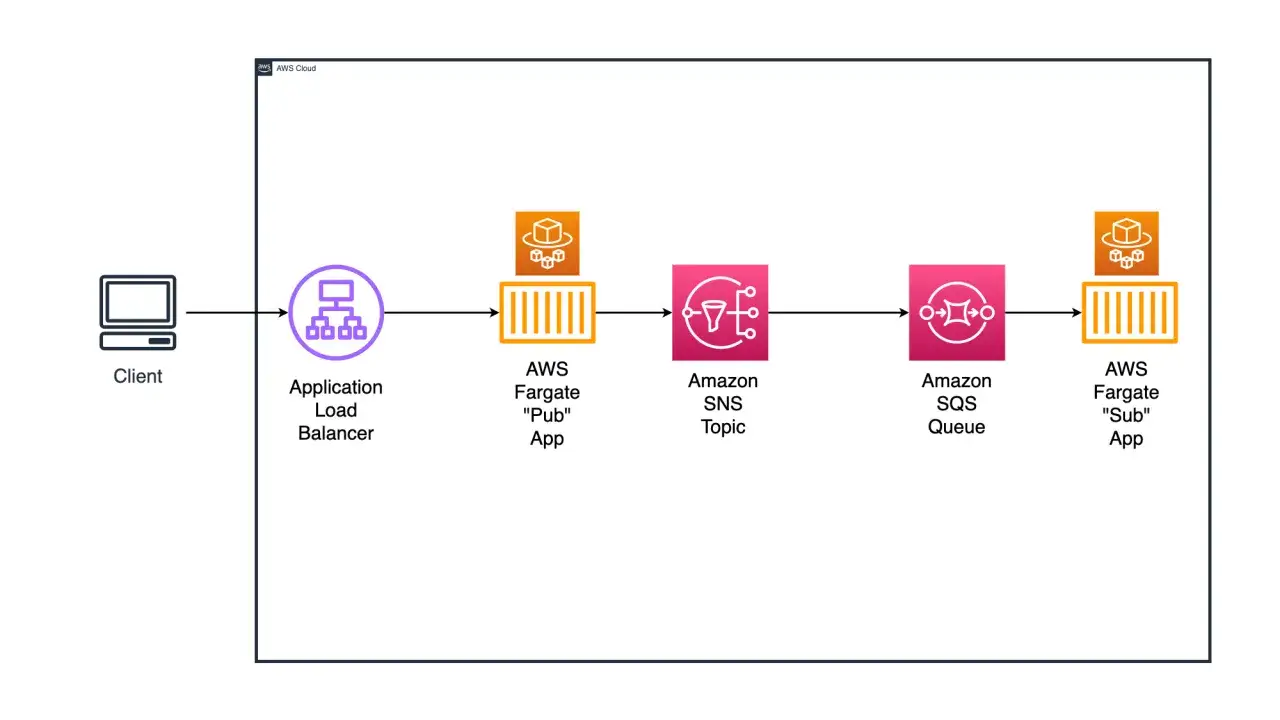
Jak działa SNS w praktyce
Od publikacji do dostarczenia
- Tworzysz topic, czyli logiczny kanał komunikacji.
- Podpinasz do niego subskrypcje, na przykład SQS, Lambda, webhook HTTP(S), e-mail, SMS albo inny endpoint.
- Publisher wysyła wiadomość do topicu, zwykle przez SDK, CLI albo API.
- SNS rozsyła komunikat do wszystkich pasujących subskrybentów, często równolegle i bez blokowania źródła.
Najważniejszy detal jest taki, że SNS nie wymaga, by publisher znał konkretnych odbiorców. To topic jest punktem wejścia, a nie pojedyncza usługa. Dzięki temu łatwiej rozwijać system bez ciągłego przepinania integracji.
Filtrowanie bez dodatkowego kodu
Domyślnie subskrybent dostaje każdą wiadomość opublikowaną w topicu. Jeśli to za dużo, można dodać subscription filter policy i ograniczyć ruch do wybranych zdarzeń. AWS pozwala filtrować po atrybutach wiadomości albo po treści wiadomości, przy czym filtrowanie po body zakłada poprawny JSON.
To ma praktyczny efekt: zamiast rozbudowywać logikę w publisherze, ustawiasz reguły przy subskrypcji. Ja zwykle wykorzystuję to do rozdzielania zdarzeń domenowych, na przykład `order.created`, `order.paid` i `order.cancelled`, tak aby billing, shipping i analityka nie dostawały wszystkiego.
Gdy rozumiesz ten przepływ, łatwiej ocenić, czy SNS faktycznie rozwiązuje twój problem, czy tylko wygląda podobnie do innych usług. I właśnie tu zaczyna się najciekawsza część decyzji architektonicznej.
Kiedy SNS rozwiązuje problem, a kiedy lepiej wybrać coś innego
Ja najczęściej polecam SNS wtedy, gdy jedno zdarzenie ma uruchomić kilka niezależnych reakcji. To klasyczny fanout: jedna publikacja, wiele odbiorców, szybka dystrybucja i brak sztywnego sprzężenia między usługami. W backendzie to bardzo wygodne, bo nie musisz dopisywać kolejnych wywołań w kodzie źródłowym każdej nowej integracji.
Dobre dopasowanie
- Powiadomienia o zdarzeniach biznesowych, na przykład zamówienie, płatność albo rejestracja użytkownika.
- Alerty z CloudWatch, CI/CD lub systemów monitoringu, które mają trafić do kilku kanałów naraz.
- Rozsyłanie tego samego eventu do analityki, cache invalidation i przetwarzania asynchronicznego.
- Webhook fanout, gdy wiele zewnętrznych systemów ma dostać identyczny komunikat.
Przeczytaj również: Elastic Beanstalk - Szybki Python na AWS? Sprawdź, czy warto!
Sygnały ostrzegawcze
- Potrzebujesz buforowania pracy i odczytu we własnym tempie.
- Chcesz, żeby wiadomość czekała, aż konsument ją pobierze i potwierdzi.
- Masz bardzo rozbudowane reguły routingu oparte na wielu źródłach eventów.
- Zależy ci bardziej na kolejce niż na rozgłaszaniu zdarzeń.
Jeśli czytasz to i myślisz, że SNS „prawie pasuje”, to zwykle znak, że warto porównać go z SQS albo EventBridge. To nie są usługi zamienne 1:1, a różnice w modelu pracy są ważniejsze niż same nazwy.
SNS, SQS i EventBridge nie są tym samym
Najkrócej ujmując: SQS buforuje, SNS rozsyła, a EventBridge routuje zdarzenia według reguł. AWS sam pokazuje te usługi jako trzy różne odpowiedzi na trzy różne problemy, choć na pierwszy rzut oka wszystkie wyglądają podobnie. To właśnie dlatego tak łatwo je pomylić w projektach backendowych.
| Cecha | SNS | SQS | EventBridge |
|---|---|---|---|
| Model komunikacji | Push, pub/sub | Pull, kolejka | Event bus z regułami |
| Trwałość wiadomości | Wiadomości nie są przechowywane jako magazyn | Wiadomości pozostają do odebrania lub wygaśnięcia | Zdarzenia są przetwarzane w czasie rzeczywistym |
| Kolejność | Brak gwarancji w standardowych topicach, FIFO daje porządek | FIFO daje ścisły porządek | Brak gwarancji kolejności |
| Filtrowanie | Subscription filter policies | Filtrowanie po stronie konsumenta, bez pub/sub routingu | Zaawansowane reguły i dopasowanie treści |
| Typowe zastosowanie | Fanout, notyfikacje, mobile push, integracje A2A i A2P | Buforowanie zadań, decoupling, przetwarzanie asynchroniczne | Architektury event-driven, routing między źródłami |
Jeśli mam uprościć wybór do jednego zdania, powiedziałbym tak: gdy chcesz rozdzielić jedno zdarzenie na wiele ścieżek, bierz SNS; gdy chcesz kolejkę z zaleganiem pracy, bierz SQS; gdy chcesz reguł i routingu między wieloma źródłami, patrz na EventBridge. Po wyborze narzędzia i tak zostaje jeszcze temat kosztów oraz ograniczeń, a to właśnie tam często wychodzą błędy projektowe.
Koszty i ograniczenia, które warto policzyć przed wdrożeniem
AWS nie pobiera opłat wstępnych ani minimalnych zobowiązań, ale koszt SNS rośnie wraz z liczbą publikacji, liczbą odbiorców i transferem danych. W praktyce najbardziej „zdradliwe” są fanout i większe payloady, bo jedna wiadomość może zamienić się w wiele dostarczeń. Dlatego warto policzyć architekturę przed wejściem na produkcję, a nie dopiero po pierwszym miesiącu faktury.
- Standard topics są rozliczane za API requests i deliveries. Każde 64 KB opublikowanych danych liczy się jako 1 request, więc wiadomość 256 KB to 4 requesty.
- FIFO topics są liczone inaczej: wiadomość od 1 KB do 256 KB to 1 wiadomość, a wszystko poniżej 1 KB jest zaokrąglane do 1 KB.
- PublishBatch przyjmuje maksymalnie 10 wiadomości w jednym żądaniu.
- Limity publikacji zależą od regionu. W regionie Europe (Ireland) domyślny limit wynosi 9 000 wiadomości na sekundę na konto, a w innych regionach spotkasz też poziomy 30 000, 1 500 albo 300 wiadomości na sekundę.
- Attribute-based filtering jest bezpłatne, a filtrowanie po treści wiadomości rozlicza skanowanie payloadu, minimum od 1 KB.
Warto też pamiętać o transferze danych. Gdy SNS wysyła dane do SQS albo Lambda, rozliczenie transferu nie jest zerowe, a między SNS i EC2 w tym samym regionie transfer jest bezpłatny. Jeśli potrzebujesz archiwizacji i odtwarzania wiadomości, ta funkcja dotyczy FIFO topics i pozwala przechowywać zdarzenia nawet do 365 dni. W praktyce największe oszczędności daje mały payload, sensowne filtrowanie i przekazywanie identyfikatora zamiast całego obiektu.
Na produkcji to zwykle wystarcza, żeby uniknąć dwóch klasycznych problemów: zbędnych kosztów i niepotrzebnego szumu po stronie odbiorców. Kolejny krok to zobaczenie, jak taki przepływ wygląda w realnym backendzie Python.
Jak wygląda typowy przepływ w backendzie Python
W Pythonie najczęściej wystarcza `boto3`, czyli standardowy AWS SDK. Publisher publikuje event do topicu, a po drugiej stronie masz na przykład Lambdę, kolejkę SQS albo webhook. Ja zwykle trzymam treść zdarzenia możliwie małą, a atrybuty wiadomości wykorzystuję do filtrowania i routingu.
import json
import boto3
sns = boto3.client("sns", region_name="eu-central-1")
response = sns.publish(
TopicArn="arn:aws:sns:eu-central-1:123456789012:order-events",
Message=json.dumps(
{
"event": "order.created",
"order_id": "A-1024",
"amount": 149.90,
}
),
MessageAttributes={
"event_type": {
"DataType": "String",
"StringValue": "order.created",
},
"environment": {
"DataType": "String",
"StringValue": "prod",
},
},
)
print(response["MessageId"])W tym układzie Message niesie treść domenową, a MessageAttributes pozwalają subskrybentom odfiltrować tylko interesujące ich eventy. To jest mały detal, ale w większym systemie robi dużą różnicę, bo pozwala ograniczyć szum bez dokładania logiki do każdej usługi.
Po stronie wdrożeniowej zwracam jeszcze uwagę na uprawnienia IAM, idempotencję konsumentów i sensowne monitorowanie błędów. SNS nie powinien być miejscem, w którym liczysz na „magiczne” naprawianie wszystkiego po drodze.
Zanim podłączysz SNS do produkcji
- Zaprojektuj konsumentów jako idempotentnych, bo duplikaty są możliwe i w architekturze zdarzeniowej trzeba je po prostu przewidzieć.
- Oddziel środowiska `dev`, `stage` i `prod`, zamiast wrzucać wszystko do jednego topicu „na chwilę”.
- Nie wysyłaj ciężkich payloadów przez SNS, jeśli wystarczy identyfikator albo link do danych w S3.
- Włącz metryki i alarmy w CloudWatch oraz sprawdzaj błędy dostarczenia, zanim problem urośnie do incydentu.
- Jeśli potrzebujesz kolejki z zaleganiem pracy, dołóż SQS zamiast próbować zrobić z SNS magazyn wiadomości.
Jeżeli traktujesz SNS jako warstwę rozgłaszania zdarzeń, a nie jako bazę ani kolejkę, dostajesz prosty i bardzo użyteczny klocek do architektury backendowej. W praktyce to jedna z tych usług AWS, które najlepiej pokazują swój sens wtedy, gdy system zaczyna rosnąć i kolejne integracje przestają mieścić się w prostych wywołaniach między usługami.