Jeśli budujesz API, panel administracyjny albo klasyczną aplikację webową, ta usługa daje sensowny kompromis między wygodą a kontrolą. Poniżej rozkładam ją na czynniki pierwsze: co robi za ciebie, jak wygląda wdrożenie, gdzie są ograniczenia i kiedy lepiej wybrać inne podejście.
Najkrócej, co trzeba wiedzieć przed startem
- Nie płacisz za samą usługę, tylko za zasoby AWS, które ona tworzy i utrzymuje po twojej stronie.
- Najlepiej sprawdza się przy web appkach, API i prostych systemach backendowych, zwłaszcza gdy chcesz szybciej wejść na produkcję.
- Dostajesz provisioning infrastruktury, autoskalowanie, load balancing, health checki i sensowne opcje wdrożeń bez ręcznej orkiestracji wszystkiego od zera.
- W Pythonie usługa jest nadal aktualna: w dokumentacji AWS widać aktywnie rozwijane platformy oparte na Amazon Linux 2023.
- To dobre narzędzie dla zespołów, które chcą mniej utrzymania, ale nie chcą oddawać wszystkiego w ręce „czarnej skrzynki”.
- Jeśli potrzebujesz bardzo niestandardowej architektury albo pełnej kontroli nad warstwą infrastruktury, szybciej dojdziesz do celu na EC2, ECS albo EKS.
Co robi Elastic Beanstalk i dlaczego oszczędza czas zespołu
Najprościej: to warstwa, która bierze na siebie uruchomienie aplikacji webowej na AWS i spina potrzebne klocki w jedno środowisko. Ja traktuję ją jako praktyczne odciążenie zadań operacyjnych, nie jako „hostowanie” w klasycznym sensie. Usługa tworzy i łączy za ciebie typowe elementy produkcyjne, takie jak instancje obliczeniowe, load balancer, grupę Auto Scaling oraz podstawowe mechanizmy monitoringu.
To ważne, bo w wielu projektach największym kosztem nie jest sam kod, tylko wszystko wokół niego: konfiguracja środowisk, restartowanie usług, aktualizacje platformy, logi, health checki i skalowanie przy wzroście ruchu. W Elastic Beanstalk można to uruchomić szybciej, ale nadal zachować wpływ na konfigurację, zmienne środowiskowe i sposób wdrażania nowych wersji.
W praktyce oznacza to mniej ręcznego klikania w konsoli i mniej ryzyka, że zespół zapomni o którejś z warstw po drodze. To nie usuwa z DevOps całej pracy, ale usuwa sporą część powtarzalnej roboty. I właśnie dlatego ta usługa bywa atrakcyjna na etapie budowy backendu, zanim architektura urośnie na tyle, że potrzebujesz cięższego rozwiązania. Następny krok to sprawdzenie, gdzie daje największy zwrot, szczególnie w projektach opartych na Pythonie.
Dlaczego dobrze pasuje do backendu w Pythonie
W projektach backendowych najbardziej cenię to, że mogę skupić się na aplikacji, a nie na każdym elemencie infrastruktury osobno. Elastic Beanstalk wspiera aplikacje webowe pisane w kilku popularnych technologiach, a w Pythonie daje sensowną ścieżkę dla typowych serwisów HTTP, API i aplikacji opartych o frameworki webowe. W praktyce dobrze czuje się tu klasyczny backend, czyli coś, co wystawia endpointy, obsługuje zapytania i komunikuje się z bazą danych.
Warstwa web server i worker
Najbardziej oczywisty scenariusz to web server environment, czyli środowisko dla aplikacji, która odpowiada na żądania HTTP. To dobry wybór dla REST API, paneli administracyjnych i aplikacji webowych. Jeśli masz zadania w tle, integracje asynchroniczne albo procesy, które lepiej wykonywać poza głównym requestem, przydaje się worker environment, czyli warstwa obsługująca pracę z kolejką zadań.
To rozróżnienie jest bardzo praktyczne, bo pozwala nie wciskać wszystkiego do jednego procesu. W backendzie często największy problem robią nie same endpointy, tylko zadania poboczne: wysyłka maili, przetwarzanie plików, synchronizacja danych czy dłuższe operacje na bazie. Gdy rozdzielisz je na właściwe role, łatwiej utrzymać stabilność i przewidywalność całego systemu.
Przeczytaj również: GNU w Backendzie i DevOps - Czym jest i dlaczego ma znaczenie?
Dlaczego Python nadal ma tu sens
W dokumentacji AWS na 2026 rok widać aktywnie utrzymywane platformy Python oparte na Amazon Linux 2023, więc to nie jest usługa „z minionej epoki”. To ważna informacja, bo przy wyborze platformy backendowej liczy się nie tylko wygoda dziś, ale też tempo aktualizacji i zgodność z nowszymi wersjami Pythona, bibliotek oraz zależności systemowych. Dla mnie to sygnał, że można ją brać pod uwagę nie tylko do prostych prototypów, ale także do regularnie utrzymywanego środowiska produkcyjnego.
W praktyce najczęściej dobrze współpracuje z aplikacjami, które da się spakować w sposób przewidywalny, z jasnym entrypointem i kontrolą zależności. Jeśli projekt jest mocno niestandardowy, nadal da się go uruchomić, ale wtedy zaczynasz więcej zyskiwać na Dockera albo na pełnej kontroli w EC2. To prowadzi do pytania, jak wygląda pierwsze wdrożenie krok po kroku i co warto ustawić od razu.
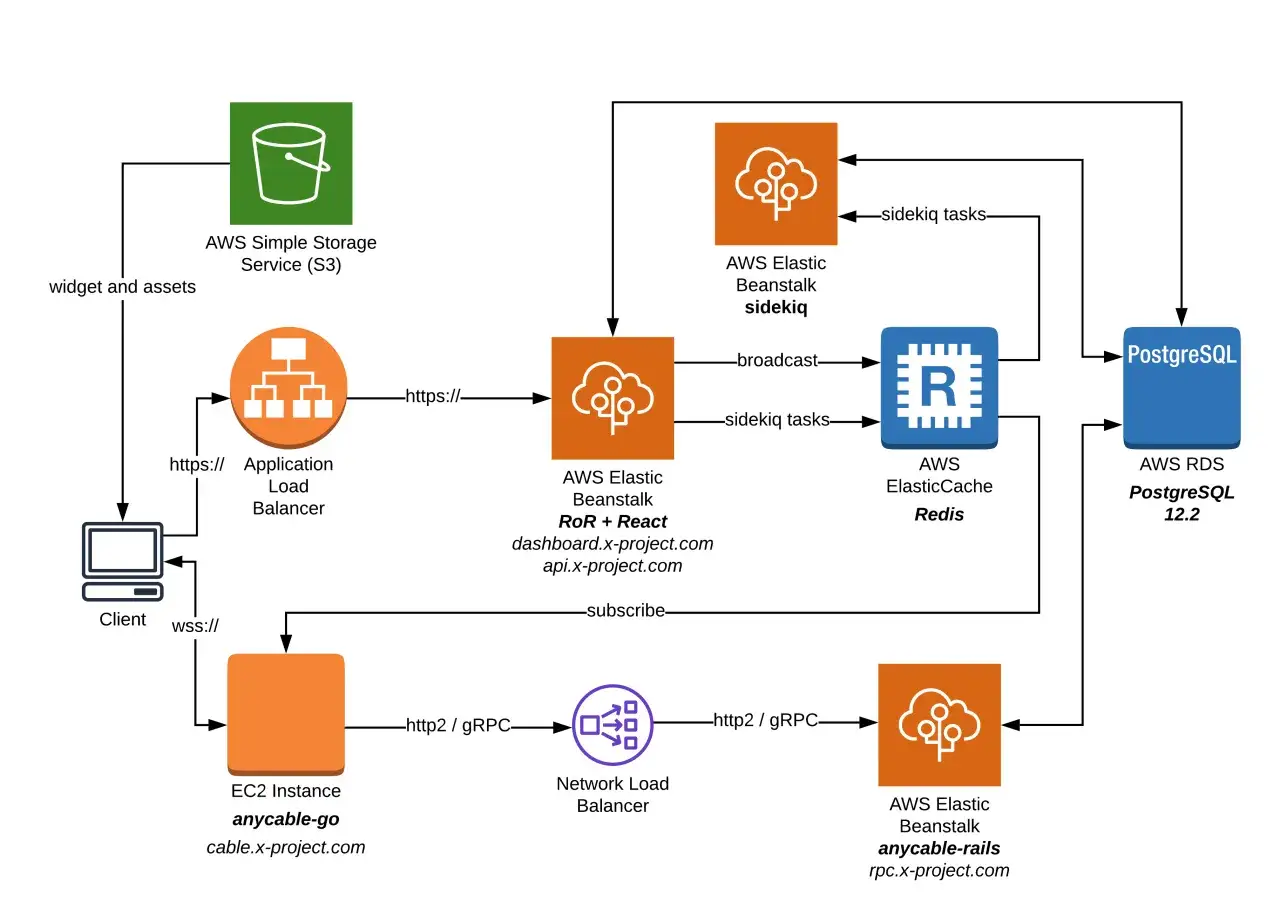
Jak wygląda wdrożenie krok po kroku
Pierwsze uruchomienie środowiska jest prostsze, niż wielu osobom się wydaje, ale kilka decyzji warto podjąć od razu świadomie. Najbardziej praktyczny schemat, którego zwykle się trzymam, wygląda tak:
- Przygotuj aplikację w formie źródła lub obrazu kontenerowego, zgodnie z platformą, którą wybierasz.
- Wybierz środowisko: web server dla aplikacji HTTP lub worker dla zadań pobieranych z kolejki.
- Ustal zmienne środowiskowe i ustawienia aplikacji przez konfigurację środowiska albo pliki konfiguracyjne.
- Dodaj role IAM: osobno dla usługi i osobno dla instancji EC2.
- Uruchom środowisko, poczekaj aż health status przejdzie na zielony i sprawdź URL aplikacji.
- Po starcie dopracuj skalowanie, logowanie i politykę wdrożeń, zamiast zostawiać wszystko na domyślnych ustawieniach.
Na etapie tworzenia środowiska warto pamiętać o jednej rzeczy: nie wszystko da się potem zmienić bez kosztu czasowego. Niektóre ustawienia, takie jak typ instancji, root volume, klucz, rola IAM czy VPC, mogą wymagać ponownego provisioningu lub dłuższej propagacji. Z punktu widzenia DevOps to nie jest wada sama w sobie, ale trzeba to uwzględnić w planie prac, zwłaszcza gdy środowisko ma być produkcyjne.
Do nauki albo wczesnego prototypowania sensownie jest zacząć od Single instance, bo AWS oznacza ten wariant jako kwalifikujący się do free tier. W produkcji zwykle lepszy będzie wariant wysokiej dostępności z load balancerem i Auto Scalingiem. Gdy to już stoi, największą różnicę zaczynają robić wdrożenia, skalowanie i obserwowalność systemu.
Jak działa wdrażanie, skalowanie i monitoring w praktyce
Tu właśnie widać największą wartość tej usługi. Elastic Beanstalk nie tylko uruchamia aplikację, ale też daje kilka sensownych strategii wdrożeń i narzędzi do utrzymania jej w dobrej kondycji. Domyślnie środowisko używa wdrożenia all at once, ale dla środowisk skalowalnych możesz przejść na tryby bardziej ostrożne.
| Tryb wdrożenia | Jak działa | Kiedy ma sens |
|---|---|---|
| All at once | Nowa wersja trafia na wszystkie instancje naraz. | Gdy liczy się szybkość, a chwilowa przerwa jest akceptowalna. |
| Rolling | Aktualizacja idzie partiami, więc część ruchu nadal obsługuje stara wersja. | Gdy chcesz ograniczyć ryzyko i nie wyłączać całego środowiska. |
| Rolling with additional batch | Najpierw dochodzi dodatkowa partia instancji, potem aktualizacja przebiega etapami. | Gdy nie chcesz tracić pojemności w trakcie wdrożenia. |
| Immutable | Powstaje nowy komplet instancji, a stary zostaje nietknięty do czasu pozytywnej weryfikacji. | Gdy zależy ci na bezpieczniejszym rolloutcie i prostszym rollbacku. |
| Traffic splitting | Ruch jest na chwilę dzielony między starą i nową wersję, co przypomina canary release. | Gdy chcesz sprawdzić nową wersję na części ruchu przed pełnym przełączeniem. |
W praktyce najbardziej lubię dwa scenariusze: rolling dla mniej krytycznych zmian i traffic splitting dla wdrożeń, które chcę bezpiecznie przetestować na niewielkim procencie ruchu. To drugie wymaga Application Load Balancera, ale daje lepszą kontrolę nad ryzykiem. Jeśli wdrożenie się nie powiedzie, usługa potrafi wycofać ruch z powrotem na starą wersję, co w realnym zespole oszczędza wiele nerwów.
Do tego dochodzi monitoring. Elastic Beanstalk ma enhanced health, czyli rozszerzone raportowanie stanu środowiska, a logi można wysyłać do Amazon S3 albo strumieniować do CloudWatch Logs. Dla mnie to ważne, bo bez logów i metryk nawet najwygodniejsza warstwa wdrożeniowa szybko robi się zgadywanką. Usługa potrafi też korzystać z managed platform updates, czyli planowanych aktualizacji platformy w oknie serwisowym, a przy włączonej wymianie instancji może stosować bardziej bezpieczne podejście do odświeżania środowiska.
Jeśli mam wskazać jedną rzecz, która najczęściej robi największą różnicę, to jest nią właśnie świadomy wybór strategii wdrożenia i sensownie włączone logowanie. To prowadzi do uczciwszego pytania: kiedy ta wygoda przestaje wystarczać i zaczynają się ograniczenia.
Gdzie zaczynają się ograniczenia i typowe błędy
Elastic Beanstalk upraszcza operacje, ale nie zamienia AWS w bezobsługową platformę magiczną. To nadal środowisko oparte o EC2, load balancing, Auto Scaling i role IAM, więc jeśli źle skonfigurujesz sieć, zależności albo politykę aktualizacji, problem nie zniknie sam. Najczęstszy błąd, jaki widzę, to założenie, że „skoro to managed service, to nie trzeba już o niczym myśleć”. Trzeba, tylko o innym poziomie szczegółów.
- Nie zostawiaj domyślnej strategii wdrożenia bez świadomej decyzji, zwłaszcza w produkcji.
- Nie ignoruj logów i health checków, bo wtedy diagnoza awarii będzie dłuższa niż samo wdrożenie.
- Nie zakładaj, że każde ustawienie da się zmienić bez kosztu, bo część zmian wymaga przebudowy zasobów.
- Nie traktuj jednej instancji produkcyjnej jak docelowego rozwiązania, jeśli aplikacja ma rosnąć lub wymaga wysokiej dostępności.
- Nie mieszaj zbyt wielu zależności systemowych w środowisku bez sprawdzenia, czy wybrana platforma je wspiera.
Jest też druga grupa ograniczeń: moment, w którym zaczynasz potrzebować bardziej zaawansowanej sieci, niestandardowej orkiestracji kontenerów albo mocniejszej separacji odpowiedzialności. Wtedy Elastic Beanstalk staje się etapem przejściowym albo wygodnym narzędziem do prostszych usług, a nie centralną platformą całej firmy. I właśnie wtedy warto uczciwie porównać go z innymi usługami AWS, zamiast trzymać się go z przyzwyczajenia.
Kiedy wybrać Elastic Beanstalk, a kiedy EC2, ECS albo EKS
Jeśli patrzę na to pragmatycznie, Elastic Beanstalk wygrywa wtedy, gdy chcesz szybko uruchomić aplikację webową i nie budować wszystkiego samodzielnie. EC2 daje największą kontrolę, ECS i Fargate lepiej pasują do podejścia kontenerowego, a EKS ma sens wtedy, gdy Kubernetes jest u ciebie świadomym standardem, a nie tylko modnym skrótem w prezentacji.
| Usługa | Poziom kontroli | Nakład operacyjny | Najlepszy scenariusz |
|---|---|---|---|
| Elastic Beanstalk | Średni | Niski do średniego | Klasyczne aplikacje webowe i API, gdy chcesz przyspieszyć wdrożenie |
| EC2 | Wysoki | Wysoki | Nietypowe wymagania, pełna kontrola nad systemem i siecią |
| ECS lub Fargate | Średni do wysokiego | Niski do średniego | Aplikacje kontenerowe, które chcesz uruchamiać bardziej „platformowo” |
| EKS | Bardzo wysoki | Wysoki | Zespoły z realnym doświadczeniem Kubernetes i potrzebą standaryzacji na klastrach |
Jak podaje przewodnik decyzyjny AWS, jeśli przyszłe wdrożenie wymaga zaawansowanego networkingu albo mocniejszej integracji z usługami takimi jak RDS, DynamoDB czy Lambda, warto mocniej rozważyć EC2. Ja dodałbym do tego jeszcze jedną rzecz: jeśli twoja organizacja już ma standard kontenerowy, to nie warto na siłę wciskać wszystkiego w Beanstalk tylko dlatego, że wygląda prościej na slajdzie. Prościej ma sens tylko wtedy, gdy nie obniża jakości utrzymania i nie blokuje kolejnych etapów rozwoju.
Dobrym pytaniem nie jest więc „czy da się to uruchomić?”, tylko „czy ten model będzie dalej wygodny za sześć miesięcy, kiedy aplikacja urośnie i dojdą nowe wymagania?”. To prowadzi do ostatniego, praktycznego kroku: co sprawdzić, zanim wrzucisz środowisko na produkcję.
Co sprawdzić przed wrzuceniem aplikacji na produkcję
Na tym etapie zwykle robię krótką listę kontrolną i nie idę dalej, dopóki nie mam pewności, że środowisko jest stabilne. W praktyce oszczędza to więcej czasu niż późniejsze poprawki „na gorąco”.
- Sprawdź, czy wybrana platforma Pythona i system bazowy nadal są wspierane.
- Ustal rolę IAM dla usługi i instancji, zamiast zostawiać domyślne uprawnienia bez przeglądu.
- Włącz logi do CloudWatch albo S3, żeby nie polegać tylko na konsoli.
- Wybierz politykę wdrożeń, która pasuje do ryzyka biznesowego aplikacji.
- Ustaw health check tak, żeby odzwierciedlał realny stan aplikacji, a nie tylko odpowiedź „200 OK” z przypadkowego endpointu.
- Zaplanowane aktualizacje platformy włącz dopiero wtedy, gdy masz sensowny maintenance window i przetestowany rollback.
- Oddziel bazę danych od środowiska aplikacyjnego, jeśli aplikacja ma żyć dłużej niż jeden eksperyment.
Jeżeli miałbym zostawić jedną praktyczną radę, to byłaby taka: nie używaj Elastic Beanstalk wyłącznie jako „szybkiego startu”, jeśli wiesz, że środowisko ma wejść na produkcję i zostać tam dłużej. Ustaw go od razu tak, jak chcesz go utrzymywać później, bo wtedy naprawdę pokazuje swoją wartość. A jeśli po tej analizie widzisz, że potrzebujesz mniejszej złożoności niż EC2, ale większej przewidywalności niż ręczne składanie wszystkiego samodzielnie, to właśnie tutaj ta usługa zwykle trafia w punkt.