Amazon SNS to jedna z tych usług, które porządkują architekturę dopiero wtedy, gdy system zaczyna rosnąć i trzeba szybko rozsyłać zdarzenia do wielu odbiorców naraz. W praktyce sprawdza się przy alertach, eventach backendowych, powiadomieniach dla zespołu i integracjach, w których jeden producent ma uruchomić kilka niezależnych reakcji. W tym artykule pokazuję, jak działa ten mechanizm, kiedy wybrać wariant standardowy albo FIFO i gdzie SNS ma przewagę nad kolejką czy event bussem.
Amazon SNS porządkuje rozsyłanie zdarzeń do wielu odbiorców
- Amazon SNS działa w modelu pub/sub, czyli jeden nadawca może uruchomić wiele reakcji po stronie odbiorców.
- Standard pasuje do prostego fanoutu i dużego tempa, a FIFO do scenariuszy, w których liczy się kolejność i deduplikacja.
- Usługa wspiera m.in. Lambda, SQS, HTTP/S, e-mail, SMS, mobile push i Kinesis Data Firehose.
- Jedna wiadomość może mieć maksymalnie 256 KB, a w batchu wyślesz do 10 komunikatów.
- W produkcji bardzo pomagają filtry subskrypcji, DLQ, retry i szyfrowanie KMS.
- W backendzie i DevOpsie SNS zwykle działa najlepiej jako warstwa dystrybucji zdarzeń, a nie jako magazyn danych.
Jak działa Amazon SNS i kiedy ma sens
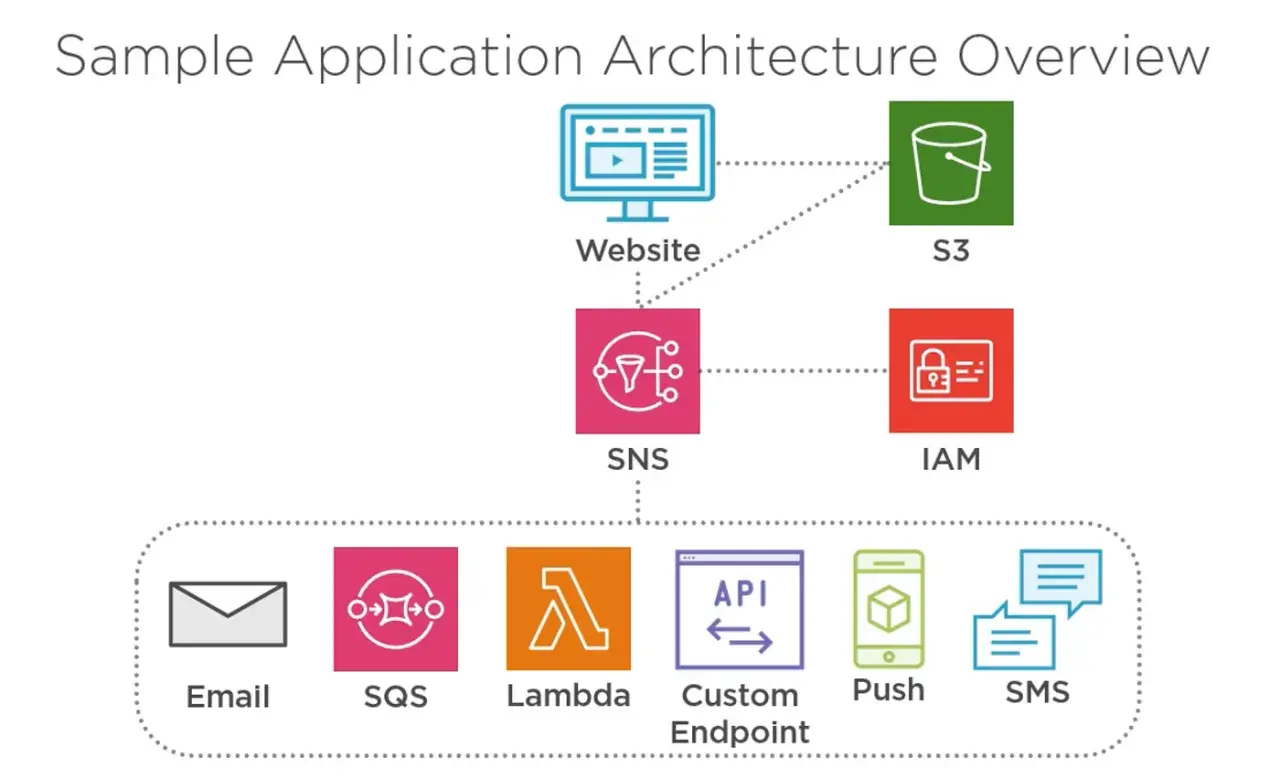
Patrzę na SNS przede wszystkim jak na usługę pub/sub, czyli publish-subscribe: publikujesz komunikat do tematu, a subskrybenci dostają go wtedy, gdy ich reguły na to pozwalają. To nie jest klasyczna kolejka, która ma trzymać zadania do późniejszego odczytu. SNS sam z siebie służy do szybkiej dystrybucji, dlatego tak dobrze pasuje do sytuacji, w których jedno zdarzenie ma uruchomić kilka niezależnych reakcji, na przykład zapis do analityki, wysłanie alertu i wywołanie funkcji Lambda.
Najlepiej myśleć o nim jak o rozdzielaczu sygnałów w systemie. Producent nie musi wiedzieć, kto finalnie odbierze wiadomość, a nowy odbiorca może dołączyć bez zmiany kodu nadawcy. To bardzo wygodne w backendzie, ale od razu rodzi kolejne pytanie: czy wystarczy prosty temat standardowy, czy lepiej sięgnąć po FIFO?
Standard i FIFO, czyli kiedy wybrać który tryb
W codziennej pracy różnica między tymi trybami jest większa, niż wygląda na papierze. Standard daje większą swobodę i prostsze zastosowanie, ale trzeba zaakceptować możliwe duplikaty oraz kolejność typu best effort, czyli bez gwarancji ścisłego porządku. FIFO jest bardziej wymagający, ale pilnuje sekwencji i pomaga tam, gdzie kolejność zdarzeń ma znaczenie biznesowe.
| Kryterium | Standard | FIFO |
|---|---|---|
| Kolejność | Brak gwarancji ścisłego porządku | Kolejność jest zachowana |
| Deduplikacja | Nie jest celem trybu standardowego | Obsługuje deduplikację przy odpowiednich identyfikatorach wiadomości |
| Zakres użycia | Alerty, fanout, ogólne eventy i duży throughput | Transakcje, stany zamówień, inventory, sekwencyjne przetwarzanie |
| Bezpośrednie kanały | Szerokie wsparcie: SQS, Lambda, HTTP/S, e-mail, SMS, mobile push, Firehose | Przede wszystkim kolejki SQS; inne kanały wymagają dodatkowej warstwy |
| Złożoność wdrożenia | Niższa | Wyższa, bo trzeba pilnować grup wiadomości i deduplikacji |
Najważniejsza praktyczna różnica jest taka, że FIFO przydaje się wtedy, gdy kolejność naprawdę zmienia wynik biznesowy. Jeśli zlecenie, płatność albo zmiana stanu muszą przejść w określonej sekwencji, ten tryb ma sens. Jeśli chodzi tylko o szybkie powiadomienie kilku systemów, standard zwykle wystarcza i jest po prostu prostszy. Warto też pamiętać, że FIFO nie jest uniwersalnym zamiennikiem wszystkich kanałów, bo nie obsługuje bezpośrednio e-maila, SMS-a czy HTTP/S w taki sam sposób jak standard.
Po stronie wdrożenia ważniejsze jest już to, gdzie taki temat realnie podłączyć w systemie. I właśnie tu SNS pokazuje swoją największą wartość.
Gdzie SNS naprawdę pomaga w backendzie i DevOpsie
Najczęściej używam SNS w czterech sytuacjach. Po pierwsze, gdy trzeba natychmiast rozesłać alert z CloudWatch do zespołu albo do systemu on-call. Po drugie, gdy jedno zdarzenie w mikroserwisach ma trafić do kilku niezależnych konsumentów, bo billing, shipping i analytics nie powinny być ze sobą sprzęgnięte. Po trzecie, gdy potrzebuję prostego kanału do e-maila, SMS-a albo pusha w aplikacji mobilnej. Po czwarte, gdy chcę odpalić webhook albo Lambdę po konkretnym zdarzeniu.
- Alerty operacyjne - dobre wtedy, gdy czas reakcji jest ważniejszy niż rozbudowana logika routingu.
- Fanout w backendzie - jeden producer publikuje zdarzenie, a kilka usług reaguje niezależnie.
- Powiadomienia z procesu DevOps - wdrożenie, nieudany pipeline, przekroczony próg metryki, nowy artefakt.
- Komunikacja z użytkownikiem - SMS, e-mail i push, ale tu trzeba świadomie ocenić koszty i deliverability.
Jeśli potrzebujesz tylko buforu dla jednego konsumenta, SNS zwykle jest zbyt szerokie. Jeśli jednak chcesz rozdzielić reakcje na jedno zdarzenie bez pisania własnej warstwy rozsyłania, ten model naprawdę upraszcza architekturę. Z praktycznego punktu widzenia najwięcej zyskujesz wtedy, gdy przechodzisz od pojedynczego alertu do całego łańcucha automatyzacji.
Jak wdrożyć to bez typowych potknięć
Żeby wdrożenie nie zamieniło się w serię trudnych do diagnozy problemów, zaczynam od kilku prostych decyzji architektonicznych.
- Zdefiniuj zdarzenie - nie wysyłaj przypadkowego tekstu, tylko komunikat z jasnymi polami, na przykład typ, środowisko, priorytet i identyfikator obiektu.
- Wybierz typ topicu - standard, jeśli liczy się prostota i throughput; FIFO, jeśli kolejność i deduplikacja są biznesowo ważne.
- Dodaj subskrypcje i filtry - dzięki filtrom jeden topic może obsługiwać kilka zespołów albo kilku odbiorców bez zalewania ich wszystkimi wiadomościami.
- Ustaw DLQ - dead-letter queue, czyli kolejkę na wiadomości, których nie udało się dostarczyć po retry, to moja podstawowa siatka bezpieczeństwa.
- Włącz szyfrowanie i uprawnienia minimalne - topic z szyfrowaniem SSE korzysta z KMS, a publikowanie do takiego tematu wymaga HTTPS i Signature Version 4.
- Przetestuj ścieżki awaryjne - sprawdź duplikaty, opóźnienia, błędne filtry i zachowanie odbiorcy przy ponownej próbie.
W praktyce często dokładam też bardzo prosty test publikacji z Pythona, żeby szybko sprawdzić, czy topic, uprawnienia i subskrypcja naprawdę działają razem.
import boto3
sns = boto3.client("sns", region_name="eu-central-1")
response = sns.publish(
TopicArn="arn:aws:sns:eu-central-1:123456789012:deployments",
Message="Nowy build przeszedł testy i czeka na wdrożenie",
Subject="CI/CD"
)
print(response["MessageId"])Najważniejsza rzecz, o której łatwo zapomnieć: zmiany w filtrach subskrypcji mogą dochodzić nawet kilkanaście minut, więc jeśli coś nie przechodzi od razu, nie zawsze oznacza to błąd w kodzie. Często to po prostu opóźnienie propagacji ustawień, a nie problem z samą usługą. Z tego miejsca naturalnie przechodzimy do porównania SNS z usługami, które najczęściej konkurują o to samo miejsce w architekturze.
Jak SNS wypada na tle SQS i EventBridge
To porównanie jest ważne, bo w praktyce wiele zespołów myli te trzy usługi i zaczyna używać ich zamiennie. Ja patrzę na nie przez pryzmat roli: SNS rozsyła, SQS buforuje, a EventBridge routuje zdarzenia według reguł. Dopiero to rozróżnienie pozwala uniknąć architektury, która wygląda nowocześnie, ale działa ciężko i nieprzewidywalnie.
| Cecha | Amazon SNS | Amazon SQS | Amazon EventBridge |
|---|---|---|---|
| Model komunikacji | Push do subskrybentów | Pull z kolejki | Routowanie po regułach |
| Trwałość wiadomości | Brak trwałego magazynu po stronie topicu | Wiadomości czekają, aż zostaną odebrane | Zdarzenia są przetwarzane na bieżąco |
| Najlepsze zastosowanie | Fanout, powiadomienia, alerty, integracje do wielu odbiorców | Buforowanie pracy i izolowanie konsumenta od producenta | Routowanie zdarzeń między systemami i usługami na podstawie reguł |
| Główna zaleta | Szybkie rozsyłanie do wielu kanałów | Stabilna kolejka robocza | Elastyczne reguły i integracje |
| Na co uważać | Duplikaty, brak magazynu, ograniczenia FIFO | Jedna wiadomość trafia do jednego konsumenta | Brak kolejności i inny model myślenia niż w klasycznym pub/sub |
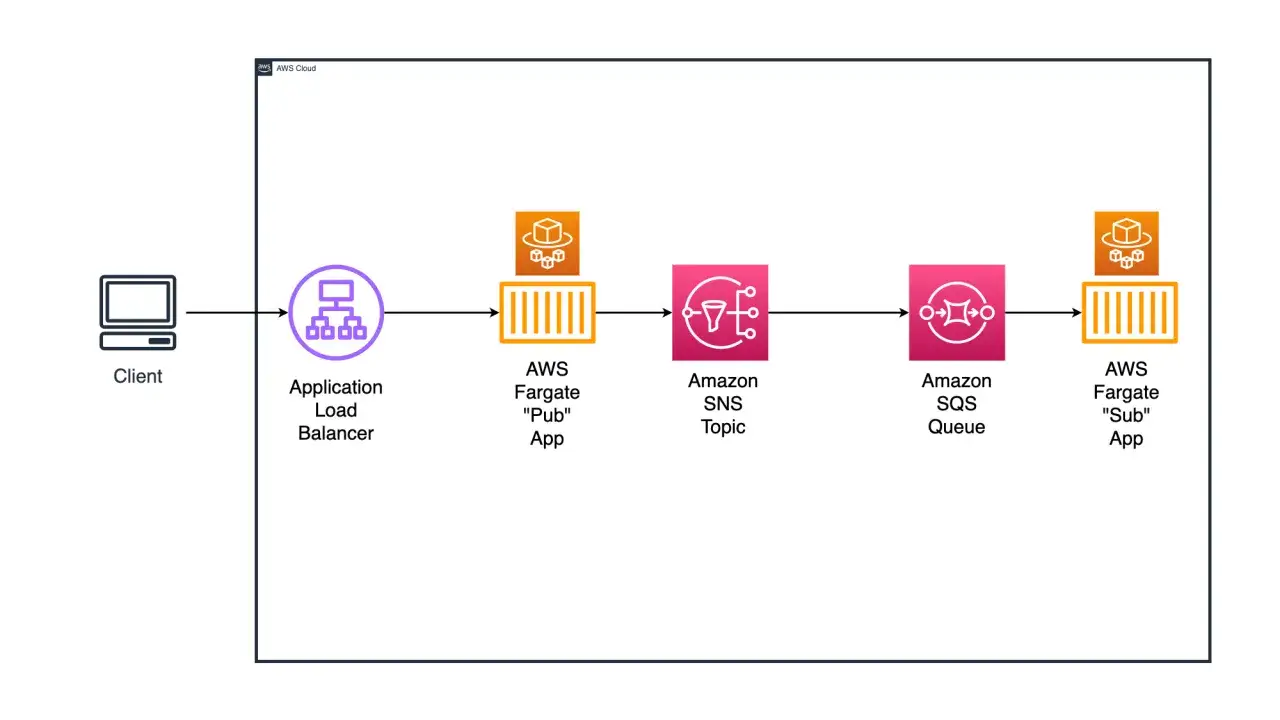
Moja praktyczna reguła jest prosta: SNS sprawdza się wtedy, gdy jedno zdarzenie ma trafić do wielu miejsc naraz, SQS wtedy, gdy chcesz bezpiecznie odłożyć pracę do przetworzenia, a EventBridge wtedy, gdy potrzebujesz bogatszego routingu i pracy na regułach. W wielu systemach najlepszy efekt daje duet SNS + SQS, bo producent publikuje raz, a każda usługa odbiera własną kopię bez sprzęgania się z innymi odbiorcami.
Jeśli chcesz wykrywać zdarzenia z wielu źródeł, korzystać z dopasowania po wzorcach i podpinać coraz więcej targetów bez modyfikowania producentów, EventBridge bywa wygodniejszy. Gdy potrzebujesz tylko trwałej kolejki roboczej dla jednego konsumenta, SQS jest prostsze. A gdy celem jest szybkie rozsyłanie komunikatów do wielu miejsc naraz, SNS pozostaje bardzo trafnym wyborem. Po tym porównaniu warto jeszcze uczciwie spojrzeć na ograniczenia, bo to one najczęściej wpływają na jakość wdrożenia.
Ograniczenia, które w praktyce robią największą różnicę
SNS jest bardzo użyteczne, ale nie jest bezwarunkowo wygodne. W architekturze produkcyjnej kilka drobiazgów robi tu realną różnicę i właśnie one zwykle wychodzą dopiero po pierwszym poważniejszym wdrożeniu.
- Limit rozmiaru wiadomości - jedna wiadomość ma maksymalnie 256 KB. Większe payloady obsługuje się zwykle przez wzorzec z S3 i referencją do obiektu.
- Batching - w jednym wywołaniu PublishBatch wyślesz do 10 wiadomości, więc przy dużym wolumenie liczy się też sposób wysyłki.
- Kolejność i duplikaty - standard może dostarczać wiadomości poza kolejnością i więcej niż raz, więc konsumenci powinni być idempotentni, czyli bezpieczni przy ponownym przetworzeniu.
- Filtry i propagacja - zmiany reguł filtrujących nie są natychmiastowe; w praktyce warto uwzględnić nawet kilkanaście minut na pełne wejście w życie.
- Retry i awarie endpointów - dla HTTP/S można sterować polityką dostarczania, a dla SMTP, SMS i mobile push AWS stosuje wewnętrzne ponawianie przez 50 prób w około 6 godzin.
- DLQ jest per subskrypcja - to ważne, bo awaria jednego odbiorcy nie powinna zatruwać całego topicu.
- Kanały A2P - SMS, push i e-mail wymagają osobnej oceny kosztów i dostarczalności; nie traktowałbym ich jako darmowego dodatku do komunikacji między usługami.
Te ograniczenia nie dyskwalifikują SNS. One po prostu podpowiadają, że usługa działa najlepiej wtedy, gdy projektujesz ją świadomie, z myślą o semantyce wiadomości, a nie tylko o samym przesłaniu tekstu. To prowadzi do ostatniej rzeczy, którą zwykle sprawdzam przed uznaniem wdrożenia za gotowe.
Co zwykle decyduje o dobrze działającym wdrożeniu SNS
Najlepsze wdrożenia SNS mają wspólny wzorzec: pojedynczy, dobrze opisany temat zdarzeń, kilka jasno nazwanych subskrypcji, filtry po metadanych, DLQ dla wyjątków i konsumenci odporni na duplikaty. To brzmi banalnie, ale właśnie ta prostota najczęściej odróżnia architekturę, która skaluje się spokojnie, od tej, która po kilku miesiącach zamienia się w trudną do utrzymania sieć połączeń.
W backendzie i DevOpsie patrzę na SNS jak na warstwę dystrybucji, która pomaga uwolnić producenta od wiedzy o odbiorcach. Jeśli potrzebujesz bufora, idziesz w SQS. Jeśli potrzebujesz reguł routingu i wielu źródeł zdarzeń, rozważasz EventBridge. Jeśli natomiast chcesz szybko rozsyłać komunikaty do wielu konsumentów i kanałów, to właśnie tutaj SNS pokazuje pełnię swoich możliwości.