
Architektura zorientowana na usługi porządkuje backend wtedy, gdy aplikacja przestaje być jednym prostym bytem, a zaczyna obsługiwać kilka domen, zespołów i kanałów integracji. W praktyce chodzi o to, by wydzielić odpowiedzialności, jasno opisać kontrakty i ograniczyć liczbę miejsc, w których zmiana jednej funkcji psuje cały system. W tym artykule pokazuję, jak to działa od strony kodu i operacji, kiedy taki model daje realną korzyść oraz gdzie łatwo wpaść w kosztowną przesadę.
Co naprawdę daje model usługowy w backendzie
- Usługa powinna odpowiadać za konkretną zdolność biznesową, a nie tylko być osobnym folderem w repozytorium.
- Największą wartość daje tam, gdzie trzeba łączyć kilka systemów, a logika biznesowa zmienia się często.
- W backendzie liczą się kontrakty, wersjonowanie, własność danych i odporność na awarie między usługami.
- W DevOps kluczowe są automatyzacja wdrożeń, testy kontraktowe, obserwowalność i sensowne zarządzanie sekretem.
- SOA nie jest automatycznie lepsza od monolitu ani mikroserwisów. Wybór zależy od skali, granic domen i dojrzałości zespołu.
Czym jest architektura zorientowana na usługi i kiedy ma sens
W tym podejściu pojedyncza usługa odpowiada za jasno opisany fragment biznesu: płatności, katalog, użytkowników, fakturowanie albo rezerwacje. To nie jest po prostu osobny moduł techniczny, tylko komponent z własnym kontraktem, granicą odpowiedzialności i sposobem wdrażania. Najlepiej sprawdza się tam, gdzie kilka systemów musi współpracować, a procesy biznesowe zmieniają się częściej niż infrastruktura wokół nich.
Ja patrzę na ten model przez pryzmat ponownego użycia i integracji. Jeśli jedna funkcja ma obsługiwać wiele kanałów, partnerów albo aplikacji wewnętrznych, usługi dają porządek, którego monolit zwykle nie zapewnia. Cena jest oczywista: trzeba pilnować kontraktów, wersji i odpowiedzialności za dane, więc przy prostej aplikacji ten układ bywa zwyczajnie zbyt ciężki.
To dlatego architektura usługowa ma sens przede wszystkim wtedy, gdy problemem nie jest samo napisanie kodu, tylko utrzymanie wspólnego procesu biznesowego między wieloma elementami systemu. Z tego miejsca naturalnie przechodzę do pytania, jak taka usługa wygląda od strony backendu.
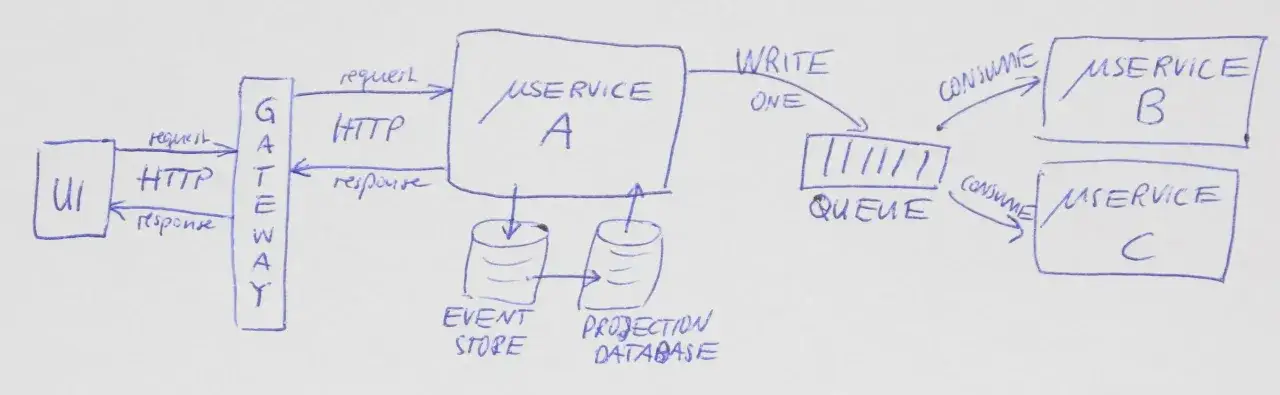
Jak wygląda usługa od strony backendu
Od strony backendu usługa powinna być możliwie samowystarczalna. Ma własną logikę domenową, jasno opisane wejścia i wyjścia oraz sposób komunikacji z innymi elementami systemu. W praktyce oznacza to nie tylko kod, ale też kontrakt, dane i zasady obsługi błędów.
Kontrakt jest ważniejszy niż implementacja
Najpierw definiuję interfejs, dopiero potem implementację. Dla API synchronicznych zwykle oznacza to OpenAPI, a dla komunikacji zdarzeniowej opis przepływu wiadomości. Dzięki temu inne zespoły mogą korzystać z usługi bez zaglądania do środka, a zmiana wewnętrzna nie rozbija wszystkiego po drodze.
Komunikacja może być synchroniczna albo zdarzeniowa
Nie ma jednego poprawnego sposobu. Wywołania synchroniczne są prostsze, gdy potrzebujesz natychmiastowej odpowiedzi, na przykład sprawdzenia stanu zamówienia. Z kolei komunikacja asynchroniczna sprawdza się lepiej przy procesach, które mogą działać etapami, jak wysyłka powiadomień, rozliczenia albo synchronizacja danych między systemami. W dobrze zaprojektowanym środowisku oba style mogą współistnieć.
Dane powinny mieć właściciela
To jedna z zasad, którą najczęściej widzę łamaną. Jeśli kilka usług zaczyna zapisywać do tej samej bazy, szybko pojawia się chaos, a granice odpowiedzialności znikają. Bezpieczniejszy wariant to model, w którym jedna usługa posiada swój fragment danych, a pozostałe korzystają z niej przez API albo zdarzenia. Gdy trzeba zsynchronizować większy proces, przydają się wzorce takie jak saga albo outbox, czyli mechanizmy pomagające spiąć kroki rozproszonego procesu bez udawania jednej wielkiej transakcji.
Orkiestracja i choreografia rozwiązują różne problemy
Orkiestracja oznacza, że jeden element steruje całym przebiegiem procesu. Choreografia polega na tym, że usługi reagują na zdarzenia i same decydują, co dalej. Pierwsze podejście jest lepsze tam, gdzie biznes chce mieć jeden punkt kontroli; drugie sprawdza się, gdy system ma być luźniej powiązany i bardziej odporny na zmiany.
W praktyce backend w takim modelu jest mniej „jedną aplikacją”, a bardziej siecią uzgodnionych zachowań. To prowadzi do porównania, które zwykle interesuje najbardziej: co odróżnia ten model od monolitu i mikroserwisów.
SOA, mikroserwisy i monolit w jednym obrazie
Największe nieporozumienie polega na tym, że wiele osób traktuje SOA i mikroserwisy jak synonimy. Wspólny jest nacisk na usługę i kontrakt, ale różni się skala, granice odpowiedzialności i koszt operacyjny. Monolit z kolei daje najniższy próg wejścia, ale najmniej elastyczności przy rozwoju wielu domen naraz.
| Cecha | Monolit | SOA | Mikroserwisy |
|---|---|---|---|
| Granice odpowiedzialności | Jedna aplikacja i wspólna baza logiki | Wydzielone usługi wokół większych zdolności biznesowych | Małe usługi wokół wąskich fragmentów domeny |
| Wdrożenia | Zwykle jedno, wspólne | Często koordynowane między usługami | Najczęściej niezależne |
| Koszt operacyjny | Niski na starcie | Średni | Najwyższy |
| Komunikacja | Wywołania wewnętrzne | REST, messaging, czasem starsze integracje z ESB | REST, eventy, broker zdarzeń, lekkie integracje |
| Kiedy ma sens | Prosty produkt, MVP, mały zespół | Integracja wielu systemów i większe procesy biznesowe | Dużo autonomicznych zespołów i wysoka częstotliwość zmian |
Z mojego doświadczenia wynika, że największy błąd polega nie na wyborze samego modelu, tylko na złym dopasowaniu go do skali problemu. Jeśli ktoś rozbija prostą aplikację na dziesiątki drobnych usług bez dojrzałego DevOps, kończy z większym bałaganem niż przed podziałem. Jeśli jednak system naprawdę składa się z wielu zależnych domen, podejście usługowe potrafi dać porządek, którego monolit już nie utrzyma.
Ta różnica szczególnie mocno wychodzi w codziennej pracy zespołów operacyjnych i deweloperskich, więc kolejnym naturalnym krokiem jest DevOps.
Co zmienia się w DevOps, gdy wchodzą usługi
W modelu usługowym DevOps nie jest dodatkiem do backendu. Jest warunkiem, żeby całość dało się bezpiecznie rozwijać. Im więcej usług, tym ważniejsze stają się automatyzacja wdrożeń, wersjonowanie kontraktów, obserwowalność i plan na awarie między komponentami.
CI/CD musi pilnować kontraktów
Testy jednostkowe nadal są potrzebne, ale nie wystarczą. Przy usługach dochodzą testy integracyjne i testy kontraktowe, czyli sprawdzanie, czy jedna usługa wciąż mówi językiem, którego oczekuje druga strona. W praktyce to właśnie one najczęściej ratują przed cichym zepsuciem integracji po wdrożeniu nowej wersji.
Obserwowalność jest częścią produktu
Logi, metryki i trace’y nie są już dodatkiem „dla administratora”. Przy architekturze usługowej to podstawowe narzędzie diagnozy. Gdy coś zwalnia albo znika po drodze, muszę wiedzieć, która usługa przyjęła żądanie, gdzie je zatrzymała i na którym etapie powstał błąd. Dlatego bardzo dobrze sprawdza się podejście oparte o jednolity tracing, na przykład z użyciem OpenTelemetry.
Przeczytaj również: Amazon SNS - Kiedy i jak używać? Przewodnik po pub/sub
Bezpieczeństwo i odporność trzeba projektować od początku
Każda usługa staje się osobnym punktem wejścia, więc rośnie znaczenie uwierzytelniania, autoryzacji, zarządzania sekretami i limityzacji ruchu. Do tego dochodzi odporność na błędy po stronie innych usług: timeouty, retry z backoffem, circuit breaker i zasada idempotencji, czyli możliwość bezpiecznego powtórzenia operacji bez podwójnego efektu. W kontenerach i na platformach orkiestracyjnych łatwiej to spiąć, ale platforma nie naprawi złej architektury za zespół.
Gdy DevOps jest dobrze ustawiony, usługi można wdrażać spokojnie i przewidywalnie. Gdy nie jest, całość zaczyna się chwiać już przy pierwszej większej zmianie. Stąd już tylko krok do typowych błędów, które widuję najczęściej.
Najczęstsze błędy, które psują taki projekt
Najwięcej problemów nie wynika z samej idei usług, tylko z tego, jak ludzie ją wdrażają. Najbardziej szkodliwe błędy są zwykle dość proste i przez to łatwo je zlekceważyć na początku.
- Zbyt wczesne dzielenie systemu - mały produkt nie potrzebuje jeszcze pełnej architektury usługowej, a rozbicie go na osobne komponenty tylko podnosi koszt utrzymania.
- Wspólna baza danych - jeśli kilka usług zapisuje do jednego miejsca, granice odpowiedzialności stają się iluzją, a wdrożenia zaczynają się wzajemnie blokować.
- Centralny ESB jako wąskie gardło - ciężka warstwa integracyjna potrafi uprościć początek, ale później staje się jednym punktem przeciążenia i trudnym miejscem zmian.
- Brak właściciela usługi - usługa bez zespołu odpowiedzialnego za jej kod, dane i monitoring szybko zamienia się w osierocony fragment systemu.
- Brak wersjonowania kontraktów - jeśli zmieniasz API bez planu migracji, każda kolejna integracja staje się ryzykiem produkcyjnym.
Ja zwykle szukam jednego prostego testu: czy zespół potrafi powiedzieć, kto odpowiada za daną usługę, jak ją monitoruje i co się stanie, gdy jej zależność przestanie odpowiadać. Jeśli odpowiedź jest mętna, projekt jeszcze nie jest gotowy na większą decentralizację.
To prowadzi do ostatniego pytania, które naprawdę warto sobie zadać przed podjęciem decyzji architektonicznej.
Zanim rozbijesz system na usługi, sprawdź te warunki
Przed startem patrzę na pięć rzeczy:
- czy masz wyraźne granice domen, które da się opisać biznesowo, a nie tylko technicznie;
- czy zmiany pojawiają się równolegle w kilku obszarach systemu;
- czy zespół ma narzędzia do testów kontraktowych, monitoringu i szybkiej diagnostyki;
- czy jesteś gotów zapłacić za większy koszt operacyjny w zamian za lepszą izolację odpowiedzialności;
- czy problemem jest integracja wielu systemów, czy po prostu chcesz szybciej rozwijać jedną aplikację.
Jeśli na większość z tych pytań odpowiedź brzmi „nie”, prostszy monolit albo modularny monolit zwykle będzie rozsądniejszy. Jeśli jednak system rośnie, domeny zaczynają żyć własnym życiem, a zespół ma dojrzałość operacyjną, model usługowy daje porządek, skalowalność i dużo lepszą kontrolę nad zmianą.