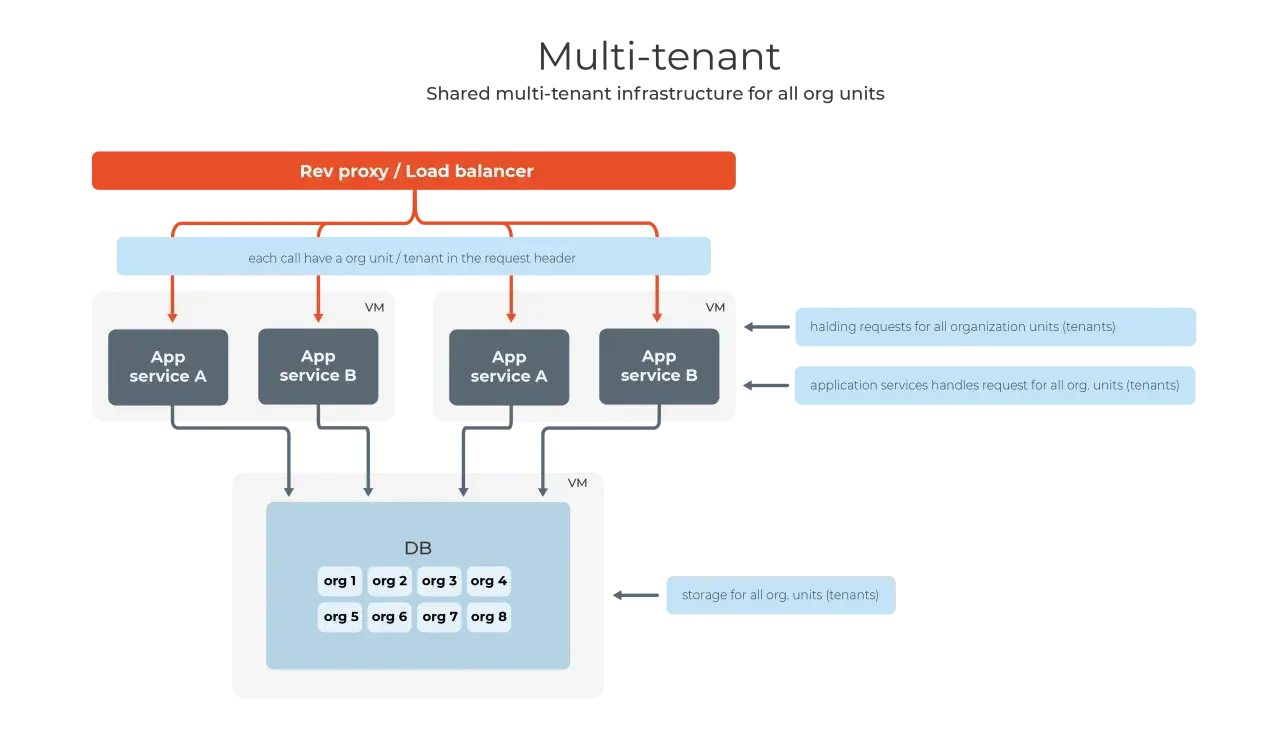
Architektura multi tenant jest sensowna wtedy, gdy chcesz obsłużyć wielu klientów jednym systemem, ale nie możesz pozwolić sobie na mieszanie ich danych, uprawnień ani konfiguracji. W praktyce najwięcej problemów nie sprawia sama definicja, tylko decyzje wokół bazy danych, monitoringu, wdrożeń i bezpieczeństwa. W tym tekście pokazuję, jak ten model działa od strony backendu i DevOps, kiedy naprawdę się opłaca oraz gdzie zwykle zaczynają się schody.
Najważniejsze fakty, które warto zapamiętać
- Wielodzierżawność oznacza współdzielenie aplikacji i infrastruktury przy zachowaniu izolacji danych, konfiguracji i uprawnień.
- Najczęściej spotyka się trzy modele izolacji: osobna baza na klienta, osobny schemat albo współdzielone tabele z kontrolą na poziomie wiersza.
- Największe ryzyko to wyciek danych między tenantami, a tuż za nim chaos operacyjny przy migracjach, backupach i alertach.
- Dobry backend musi zawsze znać kontekst tenanta, a nie tylko zalogowanego użytkownika.
- W DevOps kluczowe są automatyzacja onboardingu, wersjonowane migracje, obserwowalność z identyfikatorem tenanta i sensowne limity obciążenia.
- Model współdzielony zwykle wygrywa kosztem i prostotą, ale przy dużych klientach często kończy się architekturą hybrydową.
Na czym polega architektura wielodzierżawna
Najprościej mówiąc, w tym modelu jeden system obsługuje wielu klientów, ale każdy z nich widzi tylko swój fragment danych i konfiguracji. W praktyce multi tenant nie oznacza, że wszystko musi być wspólne. Zwykle współdzielisz kod, część infrastruktury i procesy wdrożeniowe, a izolujesz to, co wrażliwe: rekordy, pliki, limity, klucze i uprawnienia.
Ja patrzę na ten model przez pryzmat trzech pytań: co jest współdzielone, co jest odseparowane i gdzie kończy się odpowiedzialność aplikacji, a zaczyna odpowiedzialność bazy lub platformy. To ważne rozróżnienie, bo wiele osób myli wielodzierżawność z po prostu jednym loginem i wspólną tabelą. To za mało. Prawdziwa wartość pojawia się dopiero wtedy, gdy system potrafi bezbłędnie przypisać każdą operację do właściwego klienta i utrzymać ten kontekst przez cały przepływ żądania.
Ten model pojawia się nie tylko w SaaS. Działa też w dużych organizacjach, gdzie kilka działów korzysta z jednej platformy, ale potrzebuje oddzielnych widoków, polityk i raportów. To prowadzi bezpośrednio do najważniejszego tematu: jaką izolację wybrać, żeby nie przepalić budżetu ani nie otworzyć sobie furtki do awarii.
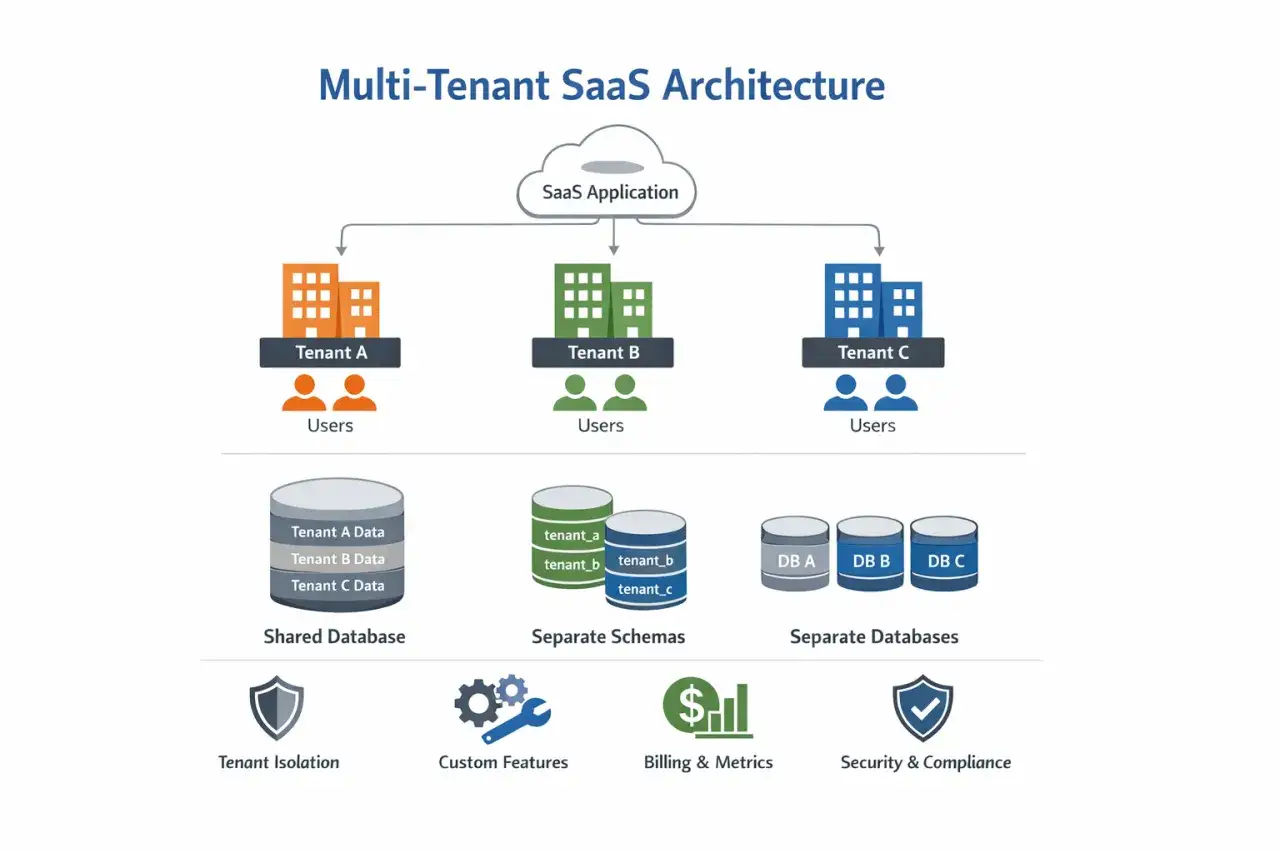
Trzy modele izolacji, które naprawdę mają znaczenie
W praktyce nie wybierasz „czy” izolować, tylko jak mocno i na jakim poziomie. Najczęściej spotyka się trzy podejścia, które różnią się kosztem, złożonością i ryzykiem operacyjnym. Dobre decyzje w tym miejscu oszczędzają miesiące późniejszych poprawek.
| Model | Jak działa | Plusy | Minusy | Kiedy ma sens |
|---|---|---|---|---|
| Silo | Osobna instancja aplikacji i osobna baza dla każdego klienta | Najmocniejsza izolacja, prostsze rozliczanie ryzyka, łatwiejsze dedykowane SLA | Najwyższy koszt, więcej wdrożeń, więcej utrzymania | Dla dużych klientów, branż regulowanych i niestandardowych wymagań |
| Bridge | Wspólna aplikacja, ale osobny schemat lub logiczny obszar danych | Dobry kompromis między kosztem a separacją, łatwiejsze migracje niż przy pełnym współdzieleniu | Wciąż trzeba dobrze ogarniać migracje i uprawnienia | Gdy klientów jest dużo, ale potrzebujesz sensownej izolacji bez pełnej dedykacji |
| Pool | Wspólna aplikacja i wspólna baza, a izolacja dzieje się na poziomie wiersza | Najniższy koszt, największa gęstość wykorzystania zasobów | Największe wymagania wobec kodu, testów i kontroli dostępu | Gdy masz dużo podobnych tenantów i zależy Ci na skali |
To nie jest wybór „lepszy versus gorszy”, tylko „bezpieczny dla mojego biznesu versus zbyt drogi”. W dokumentacji największych dostawców chmury ten sam wniosek wraca regularnie: im mocniejsza izolacja, tym większy koszt i złożoność, ale też mniejsze ryzyko współdzielenia. W praktyce najczęściej wygrywa model hybrydowy, czyli wspólna platforma dla większości klientów i wydzielone zasoby dla tych największych albo najbardziej wymagających.
Jeśli masz już obraz poziomu izolacji, następny krok jest bardziej przyziemny: trzeba sprawić, żeby backend zawsze wiedział, do którego klienta należy konkretne żądanie i dane.
Jak projektuję backend, żeby tenant nie mieszał się z tenantem
Największy błąd na tym etapie to założenie, że wystarczy dodać kolumnę `tenant_id` i sprawa jest zamknięta. Nie jest. Identyfikacja klienta musi przechodzić przez cały system, od warstwy HTTP po repozytorium i zadania w tle. Jeśli gdziekolwiek ten kontekst zniknie, prędzej czy później pojawi się wyciek danych albo błędny wynik raportu.Identyfikacja tenanta musi być jednoznaczna
W praktyce tenant powinien być rozpoznawany w sposób, który trudno podrobić i łatwo audytować. Najczęściej spotykam subdomeny, osobne domeny, identyfikator w tokenie albo jawne mapowanie z konta użytkownika do organizacji. W Pythonie zwykle zamykam to w middleware i dopiero potem przekazuję kontekst dalej, do warstwy serwisów i zapytań.
Najważniejsze jest jedno: nie ufaj samemu nagłówkowi ani parametrowi z URL bez walidacji. Identyfikator tenanta musi być powiązany z tożsamością użytkownika i z jego zakresem uprawnień. Inaczej masz tylko dekorację, a nie izolację.
Dostęp do danych powinien być wymuszany technicznie
Jeżeli aplikacja korzysta ze współdzielonej bazy, kontrola dostępu musi działać także na poziomie danych. To może być wymuszanie `tenant_id` w każdym zapytaniu, osobne schematy, widoki, polityki bezpieczeństwa na poziomie wiersza albo osobne bazy. Ja preferuję rozwiązanie, w którym aplikacja i baza wzajemnie się kontrolują, a nie polegają wyłącznie na dyscyplinie programisty.
Tu dobrze sprawdzają się mechanizmy typu row-level security, bo przenoszą część odpowiedzialności do bazy. To nie zwalnia aplikacji z myślenia, ale ogranicza skutki błędu. Jeśli jeden serwis zrobi zły join albo źle skonstruuje filtr, baza nadal może zatrzymać nieuprawniony odczyt.
Konfiguracja, limity i funkcje też są częścią izolacji
Wielodzierżawność nie kończy się na tabelach. Każdy klient zwykle ma inne limity, plan abonamentowy, zestaw funkcji, integracje i reguły biznesowe. Dlatego obok `tenant_id` trzymam też warstwę konfiguracji per tenant: feature flags, limity API, progi throttlingu, ustawienia retencji i polityki eksportu danych.
To właśnie tutaj backend zaczyna przypominać produkt, a nie tylko API. System musi umieć odpowiedzieć nie tylko „kto to jest”, ale też „co temu klientowi wolno” i „jakie ma zasady działania”. Gdy ten kontekst jest spójny, o wiele łatwiej przejść do DevOps, bo wdrożenia i migracje nie muszą być ręczne dla każdego klienta osobno.
DevOps, które robi różnicę przy wdrożeniach
W projektach wielodzierżawnych DevOps nie jest dodatkiem. To część architektury. Jeśli nie masz automatyzacji, onboarding nowego klienta zamienia się w serię ręcznych kroków, a przy większej liczbie tenantów zaczyna to być po prostu niewydolne. Mówiąc wprost: to, co da się zrobić ręcznie dla pięciu klientów, zwykle rozsypuje się przy pięćdziesięciu.
Onboarding powinien być kodem, nie checklistą w notatniku
Nowy tenant powinien powstawać przez jeden powtarzalny proces: utworzenie wpisu w systemie, przydzielenie zasobów, zapis konfiguracji, ustawienie kluczy, przygotowanie schematu lub bazy i włączenie monitoringu. Najlepiej, gdy cały ten proces jest opisany w IaC i uruchamiany przez pipeline albo automatyczny workflow. Dzięki temu nie masz „specjalnych przypadków” dla każdego klienta, tylko jeden kontrolowany proces.
To samo dotyczy offboardingu. Usunięcie lub archiwizacja klienta musi czyścić dane, zasoby, integracje i dostęp w sposób odtwarzalny. Jeżeli tego nie automatyzujesz, zostaną Ci osierocone rekordy, martwe klucze i rachunki za zasoby, których nikt nie pamięta.
Migracje muszą być zgodne wstecznie
Przy wielu klientach migracja nie może zakładać jednorazowego przestoju całej platformy. Zwykle stosuję zasadę: najpierw wdrażasz zmianę zgodną wstecznie, potem migrujesz dane, a dopiero na końcu przełączasz logikę aplikacji. To minimalizuje ryzyko, że nowa wersja backendu przestanie rozumieć stary układ danych albo że część tenantów zostanie w połowie procesu.
Jeśli baza jest współdzielona, migracje trzeba projektować szczególnie ostrożnie. Jedna zła operacja na dużej tabeli potrafi wpłynąć na wszystkich klientów naraz. Dlatego dobrze działają małe kroki, batch processing i możliwość wstrzymania migracji dla wybranego tenanty, gdy jego dane są nietypowe lub bardzo duże.
Wdrożenia progresywne ograniczają promień awarii
W tym modelu lubię rollout typu canary albo progressive delivery, bo pozwala sprawdzić nową wersję na małej grupie tenantów, zanim trafi do całej populacji. To szczególnie ważne, gdy różni klienci mają różne wolumeny ruchu. Cichy tenant może nie ujawnić problemu, który wyjdzie dopiero przy dużym obciążeniu albo przy nietypowym zestawie danych.
W praktyce najlepszy efekt daje architektura hybrydowa: większość klientów działa wspólnie, a klienci strategiczni trafiają do wydzielonych „komórek” albo osobnych segmentów infrastruktury. To nie jest nadmiarowość dla samej nadmiarowości. To sposób na ograniczenie kosztu awarii i uproszczenie biznesowej rozmowy o SLA. Następny krok to obserwowanie tego wszystkiego w sposób, który nie gubi kontekstu klienta.
Obserwowalność i bezpieczeństwo w praktyce
Jeżeli nie widzisz, co dzieje się per tenant, to nie zarządzasz platformą, tylko zgadujesz. W systemie wielodzierżawnym jedna metryka „średni czas odpowiedzi” niewiele mówi, bo może maskować problem jednego dużego klienta albo ciche przeciekanie zasobów przez innego. Dlatego obserwowalność musi być zaprojektowana z myślą o tenancie od początku.
Logi, metryki i trace’y muszą nieść identyfikator klienta
W każdej sensownej implementacji dokładam `tenant_id` do logów, metryk i śledzenia żądań. To daje możliwość filtrowania problemów, liczenia zużycia i budowania alertów dla konkretnych klientów lub grup klientów. Bez tego debugging zamienia się w ręczne przekopywanie logów i zgadywanie, kto faktycznie zgłosił awarię.
Warto też rozdzielić widok operacyjny od widoku biznesowego. Zespół supportu potrzebuje prostych sygnałów, czy dany klient ma problem. Zespół platformowy potrzebuje głębszych danych o kolejkach, bazie, cache'u i saturacji CPU. Jedno nie zastępuje drugiego.
Limity i izolacja przeciążenia chronią sąsiadów
Wielodzierżawność bez limitów kończy się scenariuszem, w którym jeden aktywny klient zjada zasoby reszty. Dlatego kontroluję przepływ przez rate limiting, quotas, osobne pule zasobów albo priorytetyzację ruchu. Jeśli klient A ma burst kampaniowy, nie powinien automatycznie spowalniać klienta B, który właśnie obsługuje swoje normalne operacje.
To miejsce, w którym bezpieczeństwo łączy się z wydajnością. Ochrona przed nadużyciem nie służy tylko atakom z zewnątrz. Chroni też zwykłych klientów przed efektem domina, kiedy ktoś inny generuje nadmierny ruch, ciężkie raporty albo nieprzewidziane piki obciążenia.
Przeczytaj również: Amazon SNS - Kiedy i jak używać? Przewodnik po pub/sub
Izolacja to nie to samo co logowanie
Wiele systemów ma poprawną autoryzację, ale słabą izolację. To dwa różne problemy. Użytkownik może być uwierzytelniony poprawnie, a mimo to aplikacja może zwrócić mu dane spoza jego tenanta, jeśli warstwa dostępu do danych jest źle napisana. Ja traktuję autoryzację jako pierwszy filtr, a izolację jako drugą, twardszą barierę.
To podejście minimalizuje skutki błędu w aplikacji, błędu w integracji albo błędnie napisanej migracji. A ponieważ większość awarii w tym modelu nie polega na tym, że „system nie działa”, tylko na tym, że „działa dla złego klienta”, ta warstwa jest krytyczna. Właśnie stąd biorą się najczęstsze wpadki, które zwykle wychodzą dopiero po wdrożeniu.
Najczęstsze błędy, które wychodzą dopiero po starcie
Najbardziej kosztowne błędy w takich systemach nie są spektakularne. Zwykle wyglądają jak drobiazg, który przez kilka sprintów nie przeszkadza nikomu, a potem nagle tworzy incydent produkcyjny. Z mojej perspektywy powtarzają się te same problemy.
- Brak tenant context w cache'u - jeden wspólny klucz cache bez prefiksu klienta kończy się mieszaniem danych albo trudnym do wykrycia „losowym” zachowaniem.
- Jedna migracja dla wszystkich bez planu przejściowego - jeśli coś pójdzie źle, problem dotyczy całej bazy, a nie jednego klienta.
- Wspólne kolejki bez kontekstu tenanta - zadania mogą się blokować nawzajem, a priorytety biznesowe przestają działać.
- Backup tylko na poziomie całej platformy - przy odtworzeniu jednego klienta chcesz mieć możliwość przywrócenia jego danych bez grzebania w reszcie.
- Raporty i eksporty bez twardych filtrów - to najprostsza droga do naruszenia izolacji danych.
- Brak limitów na głośnych klientów - jeden tenant potrafi zrujnować doświadczenie wszystkich pozostałych.
Najgorsze jest to, że każdy z tych błędów da się długo ukrywać. Testy jednostkowe nie zawsze je wyłapują, bo problem nie leży w pojedynczej funkcji, tylko w przepływie danych przez wiele warstw systemu. Dlatego przed decyzją o architekturze warto uczciwie odpowiedzieć sobie na pytanie, dla kogo ten model w ogóle ma sens.
Kiedy ten model wygrywa, a kiedy lepiej go nie forsować
Ja wybieram architekturę wielodzierżawną wtedy, gdy biznes potrzebuje szybkiego onboardingu, powtarzalnej obsługi i rozsądnego kosztu jednostkowego. Jeśli klientom oferujesz podobny zestaw funkcji, a różnice dotyczą głównie konfiguracji, limitów i danych, ten model zwykle daje bardzo dobry stosunek kosztu do skalowalności.
| Sytuacja | Wielodzierżawność zwykle ma sens | Lepiej rozważyć izolację dedykowaną |
|---|---|---|
| Duża liczba podobnych klientów | Tak | Tylko dla wyjątków |
| Silne wymagania regulacyjne lub kontraktowe | Czasem | Najczęściej tak |
| Klienci wymagają własnych wdrożeń i własnego SLA | Rzadziej | Tak |
| Produkt ma szybciej rosnąć niż zespół operacyjny | Tak | Nie jako domyślny wybór |
| Każdy klient potrzebuje mocno innego modelu danych | Trudno utrzymać | Tak |
Jeśli masz kilku dużych klientów i setki mniejszych, hybryda jest często najlepsza. Część rynku obsługujesz wspólnie, a kluczowych klientów wyciągasz do osobnych segmentów. To nie jest kompromis „na pół gwizdka”, tylko świadome zarządzanie ryzykiem i kosztami. Z takiej perspektywy łatwo przejść do ostatniego kroku: co sprawdzić zanim wypchniesz to wszystko na produkcję.
Co sprawdziłbym przed produkcyjnym wdrożeniem
Przed startem produkcyjnym robię krótką, ale konkretną listę kontrolną. Nie chodzi o formalność, tylko o to, żeby nie odkryć po wdrożeniu rzeczy oczywistych z perspektywy audytu, supportu albo bezpieczeństwa.
- Każde żądanie ma jednoznaczny kontekst tenanta od wejścia do bazy.
- Filtry dostępu działają w aplikacji i, jeśli to możliwe, również na poziomie bazy.
- Logi, metryki i trace’y zawierają identyfikator klienta.
- Migracje są zgodne wstecznie i da się je zatrzymać bez wywracania całej platformy.
- Onboarding i offboarding są zautomatyzowane.
- Backup i restore można wykonać dla pojedynczego klienta, a nie tylko dla całej instancji.
- Limity, throttling i priorytety ruchu chronią sąsiadów przed przeciążeniem.
- Support ma prosty sposób odpowiedzi na pytanie, który tenant ma problem i na jakim etapie.
Gdybym miał sprowadzić cały temat do jednej praktycznej reguły, powiedziałbym tak: współdziel to, co daje skalę, ale izoluj to, czego nie wolno mieszać. W dobrze zaprojektowanym modelu wielodzierżawnym najważniejsze nie jest samo oszczędzanie zasobów, tylko to, że system pozostaje przewidywalny, bezpieczny i możliwy do utrzymania, kiedy liczba klientów zaczyna rosnąć szybciej niż zespół.