Chmura obliczeniowa zmieniła sposób, w jaki buduje się aplikacje, wdraża backend i zarządza infrastrukturą. Zamiast kupować własne serwery, można korzystać z mocy obliczeniowej, baz danych, pamięci masowej i usług sieciowych udostępnianych przez internet, a potem skalować je wraz z potrzebami projektu. W tym tekście wyjaśniam, jak to działa, czym różnią się modele usług i wdrożeń oraz na co zwrócić uwagę, jeśli pracujesz z backendem albo DevOps.
Najważniejsze informacje w skrócie
- Chmura to model korzystania z zasobów IT przez internet, bez konieczności utrzymywania całej infrastruktury samodzielnie.
- Najczęściej spotkasz trzy modele usług: IaaS, PaaS i SaaS, a w nowoczesnym backendzie bardzo często także serverless.
- Do wyboru są cztery główne modele wdrożenia: publiczny, prywatny, hybrydowy i community cloud.
- W chmurze obowiązuje model współdzielonej odpowiedzialności - dostawca nie bierze na siebie wszystkiego.
- Największe korzyści dla backendu i DevOps to skalowanie, szybsze wdrożenia, automatyzacja i usługi zarządzane.
- Najczęstsze pułapki to koszty transferu danych, brak kontroli nad rachunkiem, zbyt duża złożoność i mylenie wygody z pełnym bezpieczeństwem.
Na czym polega chmura obliczeniowa
W najprostszym ujęciu chmura obliczeniowa polega na tym, że korzystasz z cudzej infrastruktury tak, jakby była Twoja, ale bez konieczności kupowania i utrzymywania fizycznych serwerów. Dostawca udostępnia zasoby na żądanie, a Ty uruchamiasz na nich aplikacje, bazy danych, zadania wsadowe albo środowiska testowe.
Najważniejsza różnica względem klasycznego hostingu nie leży tylko w tym, że serwer stoi „gdzieś indziej”. Chodzi o elastyczność, rozliczanie za użycie i możliwość szybkiego zwiększania lub zmniejszania zasobów. To właśnie dlatego chmura tak mocno weszła do świata backendu i DevOps: upraszcza operacje, ale jednocześnie wymaga dobrego porządku w konfiguracji.
| Cecha | Co oznacza w praktyce |
|---|---|
| Na żądanie | Zasób uruchamiasz wtedy, kiedy go potrzebujesz, bez długiego zamawiania sprzętu. |
| Współdzielona pula zasobów | Wiele klientów korzysta z tej samej infrastruktury, ale ich środowiska są logicznie odseparowane. |
| Elastyczność | Możesz zwiększyć moc obliczeniową, gdy rośnie ruch, i zmniejszyć ją po szczycie. |
| Rozliczanie za zużycie | Płacisz za czas działania, pojemność, transfer lub wybrane metryki, a nie za sprzęt jako taki. |
| Minimalna obsługa po Twojej stronie | Część zadań infrastrukturalnych przejmuje dostawca, więc zespół może skupić się na aplikacji. |
To dobry punkt wyjścia, ale sama definicja niewiele mówi o tym, jak taka usługa jest zorganizowana pod spodem. Dlatego warto zejść poziom niżej i zobaczyć, jak chmura działa technicznie.
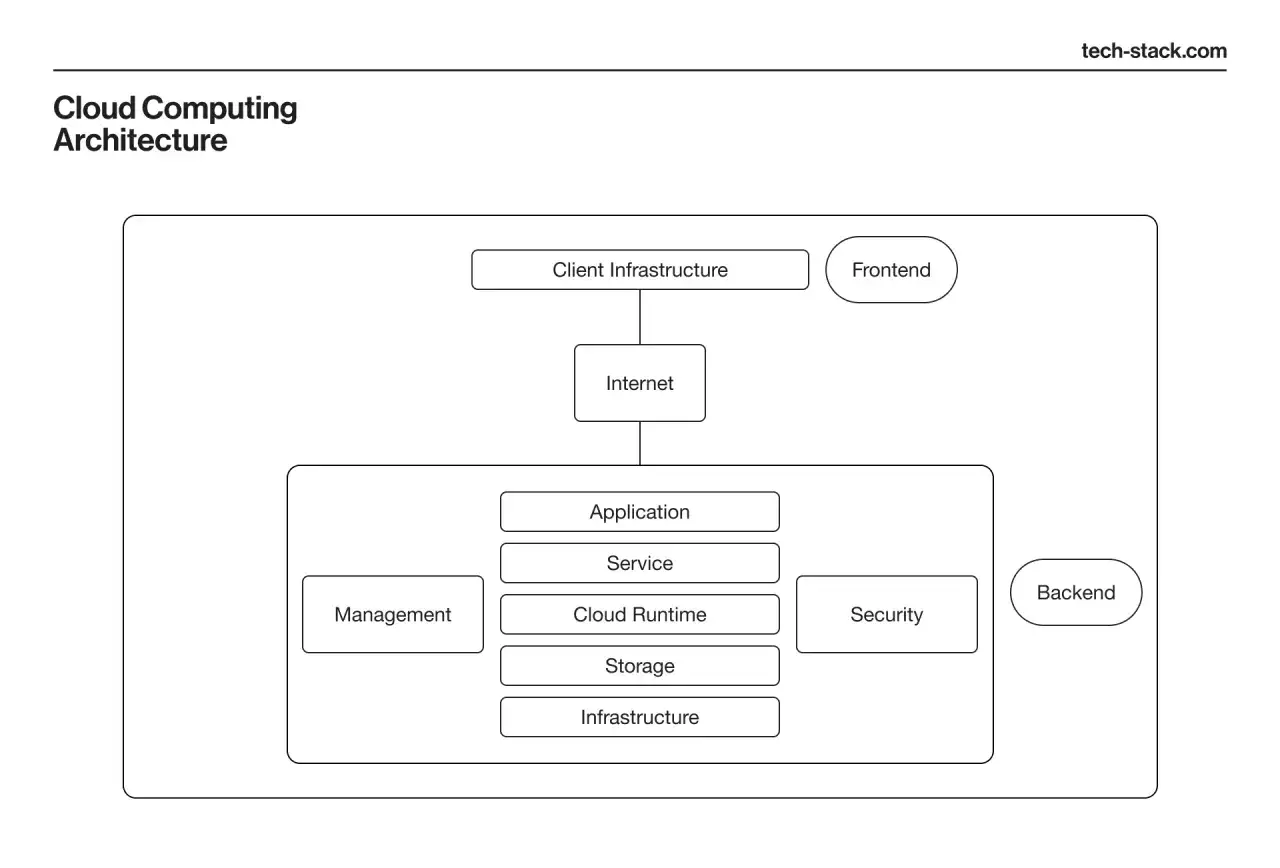
Jak działa chmura od środka
Za chmurą stoją zwykle duże centra danych, wirtualizacja, sieć i warstwa zarządzająca, do której logujesz się przez panel albo API. W praktyce wygląda to tak, że dostawca trzyma sprzęt, a Ty tworzysz zasoby logiczne: maszyny wirtualne, kontenery, bazy danych, sieci prywatne, kolejki wiadomości czy storage obiektowy.Ważne są tu trzy pojęcia. Region to obszar geograficzny, w którym działa dostawca. Strefa dostępności to osobny segment infrastruktury wewnątrz regionu, przydatny do podniesienia odporności na awarie. Autoscaling oznacza automatyczne zwiększanie lub zmniejszanie zasobów zależnie od obciążenia.
W backendzie i DevOps najczęściej spotykam taki przepływ: aplikacja trafia do repozytorium, pipeline buduje obraz lub artefakt, potem wdraża go do środowiska chmurowego, a monitoring i logi pokazują, czy wszystko działa poprawnie. To daje dużą szybkość, ale tylko wtedy, gdy zespół ma opanowane deploye, obserwowalność i podstawy sieci.Warto też odróżnić samą chmurę od kontenerów. Kontenery pomagają pakować aplikacje i przenosić je między środowiskami, ale nie są tym samym co cloud computing. Chmura jest szerszym modelem dostarczania usług, a kontenery to jedno z narzędzi, które często w tym modelu działają najlepiej.
Skoro już wiesz, jak działa mechanizm, przechodzę do najczęściej spotykanych modeli usług, bo to właśnie one najczęściej decydują o tym, ile odpowiedzialności bierze na siebie Twój zespół.
Modele usług, które najłatwiej pomylić
Najbardziej użyteczny podział to IaaS, PaaS i SaaS. W praktyce każdy z tych modeli oznacza inny poziom kontroli, inny zakres obowiązków i inny koszt operacyjny.
| Model | Co dostajesz | Co zwykle utrzymujesz sam | Kiedy ma sens |
|---|---|---|---|
| IaaS | Maszyny wirtualne, sieć, storage, podstawową infrastrukturę | System operacyjny, runtime, aplikację, konfigurację i dane | Gdy potrzebujesz dużej kontroli nad środowiskiem i kompatybilnością |
| PaaS | Platformę do uruchamiania aplikacji, często także zarządzane bazy i usługi pomocnicze | Kod aplikacji, dane, część konfiguracji i logikę biznesową | Gdy chcesz szybciej wdrażać i mniej zajmować się administrowaniem serwerami |
| SaaS | Gotową aplikację dostępną przez internet | Użytkowników, uprawnienia i zasady korzystania z danych | Gdy potrzebujesz po prostu narzędzia, a nie własnej platformy |
| FaaS / serverless | Środowisko uruchamiania funkcji wywoływanych zdarzeniami | Kod funkcji, logikę, integracje i dane | Gdy budujesz webhooki, zadania asynchroniczne, lekkie API lub automatyzacje |
Ja zwykle tłumaczę to tak: im wyżej w tabeli, tym więcej kontroli, ale też więcej obowiązków. Im niżej, tym mniej administracji, ale również mniej możliwości ręcznego sterowania każdym detalem. Dla wielu zespołów backendowych PaaS i serverless są po prostu rozsądniejszym początkiem niż pełne IaaS.
W praktyce najwięcej nieporozumień pojawia się wtedy, gdy ktoś zakłada, że „chmura” zawsze oznacza to samo. Nie oznacza. Sam model usługi mocno wpływa na koszty, bezpieczeństwo i sposób pracy zespołu.
Rodzaje wdrożenia i kiedy które ma sens
Drugie ważne rozróżnienie dotyczy sposobu wdrożenia. Tutaj klasycznie mówi się o czterech modelach: publicznym, prywatnym, hybrydowym i community cloud. To pomaga zrozumieć, gdzie fizycznie i organizacyjnie znajduje się infrastruktura.
| Model wdrożenia | Charakterystyka | Największa zaleta | Typowe ograniczenie |
|---|---|---|---|
| Public cloud | Zasoby są udostępniane przez zewnętrznego dostawcę wielu klientom | Szybki start i duża elastyczność | Mniej bezpośredniej kontroli nad infrastrukturą |
| Private cloud | Środowisko przeznaczone dla jednej organizacji | Większa kontrola, często łatwiejsze dopasowanie do polityk bezpieczeństwa | Wyższy koszt utrzymania i większa złożoność operacyjna |
| Hybrid cloud | Połączenie chmury publicznej i prywatnej | Elastyczność przy migracji i pracy z różnymi wymaganiami danych | Trudniejsze zarządzanie, integracja i obserwowalność |
| Community cloud | Infrastruktura współdzielona przez organizacje o podobnych wymaganiach | Lepsze dopasowanie do specyficznych regulacji lub misji | Rzadziej spotykany model, więc mniej standardowych wdrożeń |
W większości projektów zaczyna się od public cloud, bo daje najszybszy start i najmniej wymaga na początku. Hybryda pojawia się wtedy, gdy część danych musi zostać bliżej organizacji albo gdy migracja jest stopniowa. Private cloud ma sens tam, gdzie standardowy model publiczny nie spełnia wymagań prawnych, technicznych lub organizacyjnych.
Ten podział prowadzi prosto do pytania, które w praktyce jest ważniejsze niż sam wybór platformy: kto za co odpowiada po przeniesieniu systemu do chmury?
Kto za co odpowiada po migracji
Jedna z najczęstszych pomyłek brzmi: „skoro korzystam z chmury, to bezpieczeństwo i utrzymanie są po stronie dostawcy”. To nieprawda. Wchodzi tu w grę model współdzielonej odpowiedzialności, czyli podział obowiązków między dostawcę a Twój zespół.
| Obszar | W IaaS | W PaaS | W SaaS |
|---|---|---|---|
| Sprzęt, zasilanie, chłodzenie, centrum danych | Po stronie dostawcy | Po stronie dostawcy | Po stronie dostawcy |
| Hypervisor i warstwa wirtualizacji | Po stronie dostawcy | Po stronie dostawcy | Po stronie dostawcy |
| System operacyjny i runtime | Po Twojej stronie | Po stronie dostawcy | Po stronie dostawcy |
| Kod aplikacji i logika biznesowa | Po Twojej stronie | Po Twojej stronie | Ograniczone do konfiguracji i użycia aplikacji |
| Dane, dostęp i uprawnienia | Po Twojej stronie | Po Twojej stronie | Częściowo po Twojej stronie |
| Backupy, polityki dostępu i konfiguracja bezpieczeństwa | Najczęściej po Twojej stronie | Najczęściej po Twojej stronie | Zależy od aplikacji i zakresu funkcji |
Ta tabela jest ważniejsza, niż się wydaje, bo pokazuje realny zakres odpowiedzialności. W wielu firmach problemem nie jest sama chmura, tylko błędne założenie, że ktoś z zewnątrz zrobi za zespół porządek w IAM, politykach backupu, rotacji sekretów i kontroli kosztów.
W praktyce najlepsze efekty dają zespoły, które traktują chmurę jak środowisko wymagające inżynierii, a nie jak magiczny hosting. To naturalnie prowadzi do korzyści, które najbardziej interesują backend i DevOps.Dlaczego backend i DevOps tak często wybierają chmurę
Patrzę na chmurę przede wszystkim jak na narzędzie operacyjne. Dla backendu i DevOps liczy się to, czy system można postawić szybciej, bezpieczniej i z mniejszym nakładem pracy na utrzymanie. Właśnie tu chmura najczęściej wygrywa.
- Szybsze wdrożenia - środowisko testowe, staging i produkcję da się uruchomić dużo szybciej niż przy zakupie własnego sprzętu.
- Skalowanie ruchu - gdy API zaczyna obsługiwać więcej użytkowników, można zwiększyć zasoby bez przebudowy całej infrastruktury.
- Lepsza automatyzacja - chmura dobrze łączy się z pipeline’ami CI/CD, IaC i automatycznym provisioningiem.
- Usługi zarządzane - baza danych, kolejka, cache, storage czy monitoring mogą być obsługiwane przez dostawcę, co ogranicza ręczną administrację.
- Łatwiejsze środowiska tymczasowe - można szybko tworzyć osobne instancje pod testy funkcjonalne, demo lub review aplikacji.
- Większa odporność na awarie - sensownie zaprojektowany system może korzystać z wielu stref i mechanizmów redundancji.
W projektach Pythonowych widać to szczególnie dobrze: backend REST API, worker do kolejek, baza zarządzana, obiektowy storage na pliki i osobna warstwa obserwowalności potrafią dać bardzo dobry stos techniczny bez budowania wszystkiego od zera. To przyspiesza development, ale też zmusza do myślenia o architekturze, a nie tylko o uruchomieniu serwera.
Jednocześnie nie idealizuję tego modelu. Chmura świetnie przyspiesza start, ale źle zaprojektowana potrafi generować chaos kosztowy, nadmiar usług i trudny do utrzymania vendor lock-in. Dlatego następna sekcja jest równie ważna jak lista zalet.
Gdzie chmura pomaga, a gdzie zaczyna kosztować więcej niż zakładasz
Najczęściej problemem nie jest sama technologia, tylko założenie, że skoro coś jest „w chmurze”, to automatycznie będzie tańsze i prostsze. W praktyce bywa odwrotnie, jeśli nikt nie pilnuje metryk, transferu danych i użycia zasobów.
- Transfer wychodzący - ruch danych poza chmurę potrafi być jednym z najdroższych elementów rachunku, szczególnie przy systemach mediowych lub analitycznych.
- Przewymiarowane zasoby - instancje działające 24/7, mimo że obciążenie jest niskie, szybko podbijają koszty.
- Logi i monitoring - przy dużej liczbie zdarzeń storage logów i metryki potrafią stać się znaczącą pozycją kosztową.
- Zbyt wiele usług naraz - każda dodatkowa usługa upraszcza jeden problem, ale często dokłada kolejny w utrzymaniu.
- Silne zależności od jednego dostawcy - im mocniej korzystasz z własnościowych usług, tym trudniej później zmienić platformę.
Jest jeszcze jeden praktyczny problem: bezpieczeństwo danych. Chmura nie zwalnia z szyfrowania, kontroli uprawnień, segmentacji sieci ani planu odzyskiwania po awarii. Dostawca daje narzędzia, ale to zespół musi je dobrze skonfigurować. Właśnie dlatego doświadczenie DevOps jest tu tak cenne - pozwala łączyć automatyzację z dyscypliną operacyjną.
Jeżeli projekt ma bardzo przewidywalne obciążenie, mały ruch i nie wymaga szybkiego skalowania, klasyczna infrastruktura może być prostsza i tańsza. Chmura nie jest automatycznie lepsza od wszystkiego, tylko lepsza wtedy, gdy pasuje do profilu systemu.
Trzy pytania, które porządkują decyzję o chmurze
Gdy oceniam, czy dany system rzeczywiście powinien trafić do chmury, wracam do trzech prostych pytań. One zwykle szybciej odsiewają marketingowe założenia niż rozbudowane prezentacje dostawców.
- Czy ruch jest zmienny? Jeśli tak, elastyczne skalowanie ma duży sens. Jeśli nie, trzeba policzyć, czy chmura naprawdę się opłaca.
- Czy chcę oddać część utrzymania platformy? Jeśli zespół ma mało czasu na administrację, model zarządzany zwykle daje więcej korzyści niż pełne IaaS.
- Czy policzyłem wszystko, a nie tylko cenę serwera? Do rachunku trzeba doliczyć transfer danych, logi, kopie zapasowe, monitoring, środowiska testowe i czas ludzi.
Jeśli odpowiedzi są dobrze przemyślane, decyzja staje się dużo prostsza. Chmura nie jest celem samym w sobie. Jest sposobem na budowę systemu, który szybciej reaguje na zmiany, łatwiej się rozwija i lepiej wspiera pracę backendu oraz DevOps. Jeśli dobrze ją zaplanujesz, pomaga skupić się na produkcie. Jeśli nie, dokłada tylko kolejną warstwę złożoności.