Modernizacja starego backendu rzadko wygrywa z podejściem typu big-bang rewrite. Bezpieczniej działa model, w którym nowa funkcjonalność powstaje obok starej i stopniowo przejmuje ruch, aż legacy można wyłączyć bez zatrzymywania biznesu. Taki jest sens wzorca znanego jako strangler fig pattern, a w tym artykule pokazuję, jak rozumieć go praktycznie, kiedy ma sens i jak przeprowadzić migrację od strony backendu oraz DevOps.
Najważniejsze rzeczy, które warto zapamiętać z migracji bez wielkiego cut-overu
- Największa zaleta tego podejścia to redukcja ryzyka, bo stary system działa cały czas.
- Pierwszy krok to warstwa routingu lub fasada, która kieruje część ruchu do nowej implementacji.
- Najlepsze efekty daje dzielenie migracji na małe, dobrze mierzalne wycinki, a nie na jeden ogromny projekt.
- Backend i DevOps muszą tu współpracować: routing, testy kontraktowe, observability i rollback są krytyczne.
- Najczęstszy błąd to zbudowanie dwóch systemów naraz bez jasnych granic, metryk i terminu wyłączenia legacy.
Na czym polega ten wzorzec w praktyce
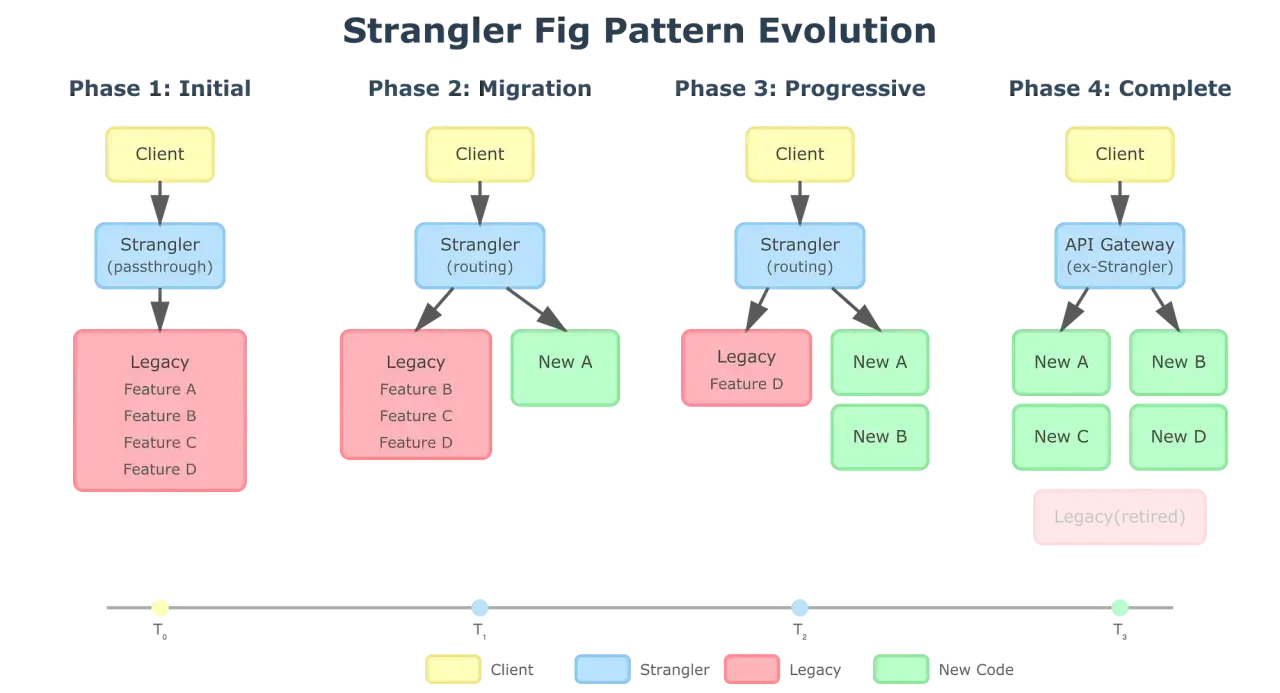
Martin Fowler opisał to podejście jako sposób na stopniowe zastępowanie starego systemu nowym, zamiast ryzykownego wielkiego przełączenia. W praktyce chodzi o to, że przed legacy stawiasz warstwę routingu albo fasadę, a potem kolejne funkcje przenosisz do nowej implementacji. Stara i nowa wersja żyją równolegle tylko tak długo, jak to potrzebne, więc zespół nie przegrywa projektu na etapie cut-overu.
Najważniejsza różnica względem przepisywania całej aplikacji polega na tym, że tutaj nie czekasz na „gotowy dzień zero”. Zamiast tego dostarczasz małe, mierzalne kawałki wartości: jeden endpoint, jedną ścieżkę obsługi zamówienia, jeden proces raportowy. Dzięki temu możesz obserwować zachowanie systemu na produkcji i szybko reagować, jeśli coś zaczyna się rozjeżdżać.
Ja traktuję ten wzorzec nie jako elegancką metaforę, ale jako bardzo praktyczny mechanizm zarządzania ryzykiem. Jeśli zespół ma do czynienia z krytycznym backendem, to nie chodzi o to, by „przepisać wszystko lepiej”, tylko by odcinać zależność od starego kodu małymi krokami i nie psuć przy tym procesu biznesowego.
Kiedy ma sens, a kiedy lepiej wybrać inną drogę
Ten model działa najlepiej wtedy, gdy system ma wyraźne granice domenowe i da się oddzielić jeden fragment ruchu od reszty. Jeśli potrafisz wskazać konkretne wejście, które można przechwycić na poziomie API, gatewaya, reverse proxy albo nawet warstwy aplikacyjnej, to masz realny kandydat do migracji. Jeśli nie masz takiego punktu zaczepienia, najpierw trzeba go stworzyć.
| Sygnał | Co to oznacza | Moja ocena |
|---|---|---|
| Masz jedno lub kilka czytelnych wejść do systemu | Ruch da się przekierować do nowej ścieżki bez przebudowy całej aplikacji | Dobry kandydat |
| Legacy ma stabilne, znane zachowanie | Da się je opisać testami, monitorować i porównywać z nową wersją | Dobry kandydat |
| Możesz utrzymać dwie implementacje równolegle | Zespół ma czas, ludzi i narzędzia do kontrolowanego przejścia | Dobry kandydat |
| Wszystko jest sklejone jedną bazą i jedną logiką | Rozdzielenie funkcji będzie kosztowne, a błędy spójności będą częste | Słaby kandydat |
| Nie masz testów, monitoringu ani rollbacku | Nie zobaczysz od razu, co się psuje i trudno będzie cofnąć zmianę | Najpierw popraw fundamenty |
Jeśli miałbym sprowadzić decyzję do jednego pytania, zadałbym je tak: czy jesteś w stanie bezpiecznie przełączyć mały wycinek ruchu i wrócić do starej ścieżki w kilka minut? Jeśli odpowiedź brzmi „tak”, jesteś blisko dobrego zastosowania tego wzorca. Jeśli brzmi „nie”, to problemem nie jest jeszcze migracja, tylko brak infrastruktury do jej obsłużenia.
Jak wygląda migracja krok po kroku
Nie zaczynam od przepisywania najtrudniejszego modułu. Zaczynam od wycinka, który ma sens biznesowy, jest dobrze rozpoznany i da się go zweryfikować bez długiej dyskusji. W backendzie często bywa to read-heavy endpoint, prosty proces statusowy albo fragment, który najmniej zależy od reszty systemu.
- Mapuję funkcje i granice domenowe. Rozpisuję, które części systemu da się wydzielić bez naruszania innych procesów. Tu przydaje się spojrzenie przez bounded contexts, nawet jeśli nie wdrażam pełnego DDD.
- Wybieram pierwszy mały wycinek. Szukam elementu, który jest ważny, ale nie krytyczny dla całej firmy. Dobrze, gdy da się go mierzyć osobno i łatwo porównać starą i nową wersję.
- Stawiam warstwę pośrednią. To może być reverse proxy, API gateway, router w aplikacji albo fasada. Jej zadaniem jest przechwycenie ruchu i decyzja, gdzie ma trafić dalej.
- Buduję nową implementację równolegle. Stara wersja dalej obsługuje produkcję, a nowa dostaje własne testy, własne metryki i własny cykl wdrożeniowy.
- Porównuję zachowanie obu ścieżek. Dla krytycznych operacji uruchamiam testy kontraktowe, shadow traffic albo kontrolne porównania wyników. Chodzi o to, by wyłapać różnice zanim zobaczy je klient.
- Przełączam ruch stopniowo. Najpierw 1%, potem 5%, następnie 25%, 50% i dopiero pełne 100%, jeśli metryki są stabilne. To klasyczny canary release, czyli kontrolowane podnoszenie ekspozycji nowej wersji.
- Wyłączam stary tor dopiero na końcu. Kiedy nowa ścieżka pracuje stabilnie, usuwam starą implementację, ale dopiero po potwierdzeniu, że nie ma już zależności operacyjnych ani biznesowych.
Ta kolejność ma znaczenie. Jeśli najpierw przeniesiesz dane, a dopiero potem ruch, możesz wpaść w bardzo kosztowny chaos. Jeśli najpierw przepniesz ruch, a dopiero potem zaczniesz uzupełniać brakujące testy, to ryzykujesz twardy rollback w najmniej wygodnym momencie. Najbezpieczniej działa podejście, w którym każda zmiana ma swoją hipotezę, swój pomiar i prostą drogę odwrotu.
Co musi zagrać w backendzie i DevOps
W tym wzorcu technologia operacyjna jest równie ważna jak kod. Sama implementacja nowej funkcji niczego nie załatwia, jeśli nie umiesz bezpiecznie nią sterować. AWS zwraca uwagę, że w czasie przejścia między starą i nową częścią bardzo przydaje się anti-corruption layer, czyli warstwa tłumacząca dane i kontrakty między systemami. To nie jest ozdobnik architektoniczny, tylko bariera przed rozlaniem się starego modelu na nowy.| Obszar | Po co jest potrzebny | Co najczęściej się psuje |
|---|---|---|
| Routing i fasada | Kieruje część ruchu do nowej implementacji | Brak prostego rollbacku i zbyt skomplikowane reguły przekierowań |
| Feature flags | Pozwalają włączać i wyłączać funkcje bez nowego wdrożenia | Flagi zostają na zawsze i zamieniają kod w labirynt |
| Observability | Daje logi, metryki i trace’y potrzebne do porównania zachowania | Zespół widzi awarię dopiero po skardze użytkowników |
| CI/CD | Umożliwia częste, małe wdrożenia z kontrolą jakości | Wdrożenia są rzadkie, duże i trudne do odwrócenia |
| Warstwa danych | Chroni spójność modelu i pozwala migrować stan bez chaosu | Dual-write bez planu spójności i rozjazd danych między systemami |
Najbardziej praktyczna zasada, którą stosuję, brzmi tak: nie buduj migracji na nadziei, że „baza jakoś się sama dopasuje”. Jeśli nowa usługa potrzebuje danych ze starego systemu, zaplanuj sposób synchronizacji. Czasem wystarczy zdarzenie domenowe lub outbox, czasem change data capture, a czasem trzeba na chwilę utrzymać warstwę tłumaczącą. Bywa też tak, że prosty dual-write jest najgorszą możliwą opcją, bo wydaje się wygodny, ale bardzo trudno go potem debugować.
W DevOps ważne są jeszcze dwie rzeczy: możliwość szybkiego przełączenia ruchu oraz czytelny obraz stanu produkcji. Blue-green deployment daje dwie kompletne ścieżki środowiskowe, a canary pozwala wypuścić nową wersję do małej części użytkowników. Do tego dochodzi monitoring złotych sygnałów: opóźnienia, błędy, ruch i nasycenie zasobów. Bez tego migracja zaczyna przypominać lot bez instrumentów.Najczęstsze błędy, które psują cały plan
Najwięcej projektów nie przegrywa na poziomie technologii, tylko na poziomie decyzji o zakresie. Zbyt duży pierwszy wycinek, brak planu wycofania ruchu albo wymiana całej domeny naraz zwykle kończą się tym, że zespół pracuje miesiącami, a biznes nie widzi wartości. Wtedy rośnie presja, a presja jest złym doradcą przy migracji krytycznego systemu.
- Za duży pierwszy krok. Jeśli pierwszy fragment jest zbyt złożony, nie zobaczysz szybko błędów ani nie zdobędziesz zaufania interesariuszy.
- Brak jasnych granic domenowych. Gdy nowa usługa kopiuje logikę starej bez izolacji, kończysz z dwoma wersjami tego samego chaosu.
- Współdzielona baza jako „skrót”. To potrafi działać chwilę, ale później utrudnia testy, rollback i niezależne wdrażanie.
- Brak metryk porównawczych. Jeśli nie mierzysz różnic, nie wiesz, czy migracja poprawia system, czy tylko go rozszczepia.
- Próba przepisania wszystkiego jednocześnie. To wraca do problemu big-bang rewrite, tylko pod inną nazwą.
- Wiecznie tymczasowe rozwiązanie. Jeśli nie ma daty i kryteriów wyłączenia legacy, tymczasowość łatwo zamienia się w nowy stan stały.
Moim zdaniem najbardziej zdradliwy jest ostatni punkt. Zdarza się, że nowa ścieżka działa już dobrze, ale stara zostaje „na wszelki wypadek” i nikt nie bierze odpowiedzialności za jej odłączenie. Wtedy zespół utrzymuje podwójny koszt, podwójne ryzyko i podwójny dług techniczny. To nie jest sukces migracji, tylko jej przeciągnięcie.
Jak oceniam, że stary system można już wyłączyć
Najgorszy moment w takich projektach to ten, w którym nowa ścieżka działa, ale nikt nie ma odwagi odciąć starej. Ja zwykle patrzę na trzy warunki: zero ruchu na starych trasach przez 30-90 dni, brak rozjazdów danych w porównaniach kontrolnych i brak incydentów, które wymuszają rollback do legacy. To nie jest reguła z podręcznika, raczej praktyczny próg bezpieczeństwa, który pozwala uniknąć „wiecznie tymczasowego” rozwiązania.
- Ruch na starym torze spadł do zera i nie wraca po kolejnych wdrożeniach.
- Porównania biznesowe się zgadzają, np. liczba zamówień, statusy płatności albo sumy rozrachunkowe.
- Support i operacje pracują już na nowym procesie, więc wyłączenie legacy nie obniży jakości obsługi incydentów.
- Dokumentacja i monitoring są przeniesione, a stare alerty nie są już jedynym źródłem prawdy.
W praktyce wyłączenie starego systemu jest ostatnim krokiem, ale nie powinno być improwizacją. Jeśli wycinek został dobrze zmigrowany, to decyzja o odcięciu legacy powinna być niemal nudna: metryki są stabilne, użytkownicy nie widzą różnicy, a zespół wie, co zrobi w razie problemu. I właśnie o to chodzi w całym podejściu - nie o efektowną przebudowę, tylko o spokojne przejęcie odpowiedzialności przez nową architekturę.