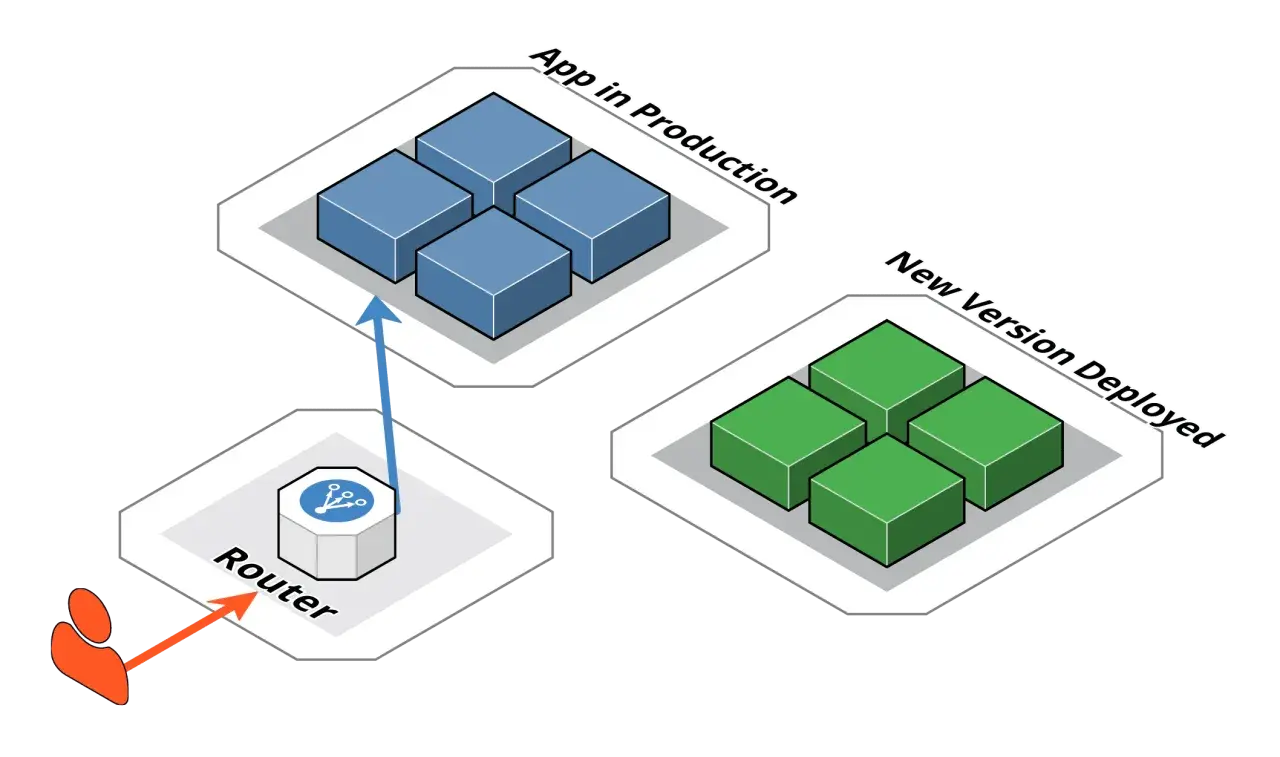
Najważniejsze elementy tej strategii to przygotowanie, testy i bezpieczny powrót do poprzedniej wersji
- Ruch produkcyjny trafia tylko do jednego aktywnego środowiska, a drugie pozostaje gotowe do przełączenia.
- Największy problem zwykle nie leży w samym kodzie aplikacji, lecz w bazie danych, sesjach i cache’u.
- Rollback jest szybki tylko wtedy, gdy nowa wersja jest wstecznie kompatybilna i ma poprawne health checki.
- Pełna redundancja podnosi koszt infrastruktury, ale znacząco zmniejsza ryzyko przestoju.
- To rozwiązanie działa najlepiej tam, gdzie routing, monitoring i automatyzacja są już uporządkowane.
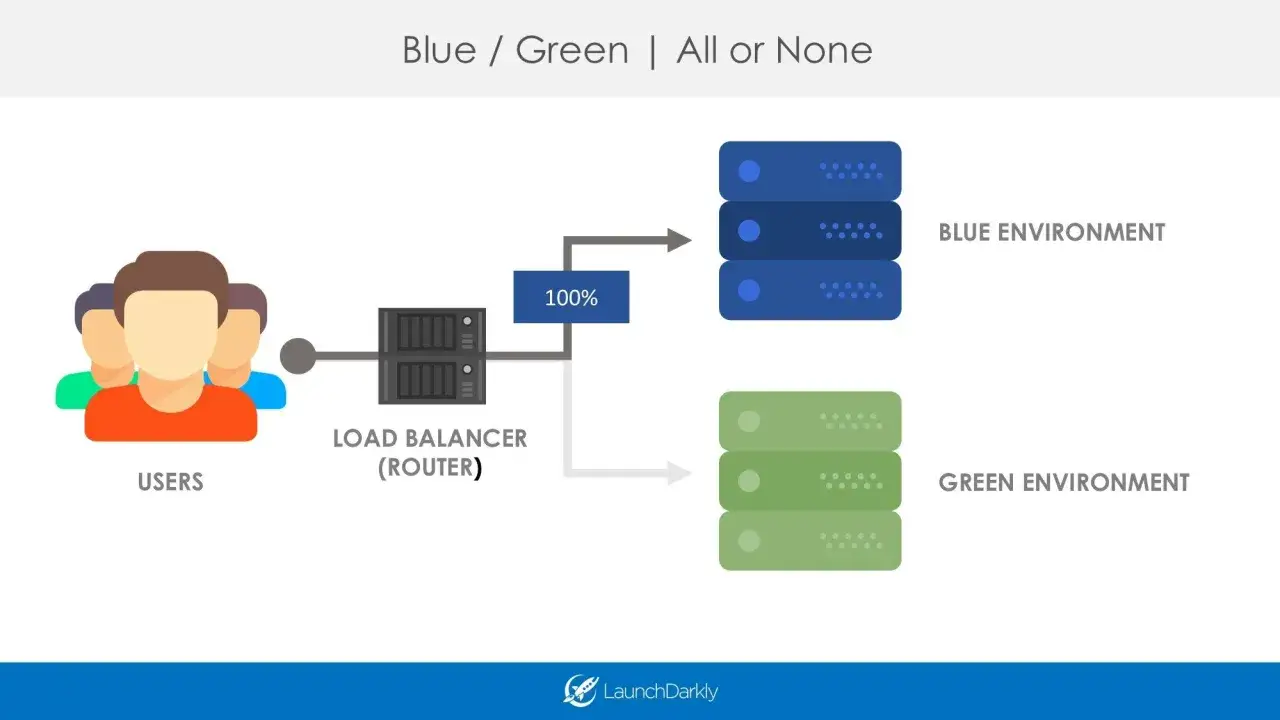
Na czym polega blue-green deployment w praktyce
W tej strategii utrzymujesz dwa kompletne środowiska produkcyjne. Jedno obsługuje realny ruch, drugie jest gotowe na nową wersję aplikacji, testy końcowe i szybkie przełączenie. Jak opisuje dokumentacja AWS, to podejście daje blisko zerowy przestój i bardzo szybki powrót do poprzedniej wersji, bo wycofanie zmian sprowadza się do ponownego skierowania ruchu.
Ja traktuję tę metodę nie jako trik wdrożeniowy, tylko jako sposób na oddzielenie publikacji od ekspozycji na ruch. Dzięki temu możesz sprawdzić nową wersję zanim zobaczą ją użytkownicy, a nie dopiero wtedy, gdy produkcja zacznie się sypać. W praktyce najważniejsze są trzy rzeczy: identyczna konfiguracja obu środowisk, kontrolowane przełączenie ruchu i możliwość natychmiastowego cofnięcia zmian.
To brzmi prosto, ale właśnie prostota bywa myląca. Sama zamiana adresu czy przełączenie reguły w load balancerze nie wystarcza, jeśli aplikacja niesie stan w pamięci, ma niekompatybilny schemat bazy albo opiera się na sesjach lokalnych. Dlatego dalej rozbieram tę strategię na proces, decyzje i typowe błędy, które w realnym backendzie robią największą różnicę.
Jak wygląda przełączenie ruchu krok po kroku
Najbardziej praktycznie myślę o tym jak o sekwencji, a nie o pojedynczym przycisku. Zielone środowisko nie powinno być tylko kopią infrastruktury, ale pełną ścieżką uruchomieniową nowej wersji. Dopiero gdy przejdziesz przez cały cykl, strategia niebiesko-zielona zaczyna działać tak, jak obiecuje marketing chmur.
- Tworzysz drugie środowisko z tą samą konfiguracją sieci, sekretów, zmiennych środowiskowych i zależności.
- Wdrażasz nową wersję aplikacji, a jeśli trzeba, przygotowujesz też migracje bazy w trybie zgodnym wstecz.
- Uruchamiasz testy smoke, health checki i krótką walidację biznesową, na przykład logowanie, płatność testową albo zapis formularza.
- Porównujesz metryki: błędy 4xx i 5xx, opóźnienia, zużycie CPU, kolejki zadań i sygnały z logów aplikacyjnych.
- Przełączasz ruch na zielone środowisko na poziomie load balancera, ingressu albo mechanizmu routingu w platformie.
- Trzymasz stare środowisko jeszcze przez okres obserwacji, zwykle od kilkunastu minut do dłużej, jeśli system jest krytyczny.
- Jeśli coś się psuje, wracasz do poprzedniego środowiska bez ponownego wdrażania całej aplikacji.
W systemach opartych na DNS da się to zrobić także przez zmianę rekordów, ale ja traktuję to jako mniej precyzyjne rozwiązanie. Czas propagacji i cache po stronie resolverów potrafią rozciągnąć przełączenie na minuty, więc jeśli masz do dyspozycji warstwę ruchu albo gateway, zwykle wygrywa ona z DNS-em. To prowadzi do ważniejszego pytania: kiedy taka strategia jest naprawdę lepsza od innych modeli release’u?
Kiedy wybrać ją zamiast rolling deployment lub canary
Nie wybieram tej strategii dlatego, że brzmi dojrzalej od innych. Wybieram ją wtedy, gdy rollback musi być błyskawiczny, a koszt podwójnej infrastruktury jest akceptowalny. W praktyce liczą się trzy rzeczy: tolerancja na ryzyko, budżet na równoległe środowiska i to, czy chcesz wypuścić wszystko naraz, czy tylko część użytkowników.
| Strategia | Kiedy ma sens | Największa zaleta | Największy minus |
|---|---|---|---|
| Niebiesko-zielona | Gdy rollback ma być natychmiastowy, a system jest krytyczny dla biznesu | Bardzo szybkie cofnięcie zmian i prosty moment przełączenia | Wyższy koszt utrzymania dwóch środowisk |
| Rolling | Gdy chcesz ograniczyć koszty i akceptujesz mieszane wersje w czasie wdrożenia | Niższe zużycie zasobów | Rollback jest wolniejszy i trudniej utrzymać pełną spójność |
| Canary | Gdy chcesz najpierw wystawić zmianę małej grupie użytkowników | Najmniejszy blast radius przy błędzie | Bardziej złożona analiza i bardziej rozbudowany routing |
Microsoft Learn pokazuje podobny model w Azure Container Apps, oparty o rewizje i wagi ruchu, ale sens wyboru pozostaje ten sam: szybki pełny switch albo stopniowa ekspozycja. Ja zwykle wybieram niebiesko-zielone wdrożenie dla API, systemów transakcyjnych i usług, w których koszt błędu jest większy niż koszt dodatkowej infrastruktury. Jeśli masz dużo ruchu eksperymentalnego albo chcesz bardzo precyzyjnie mierzyć wpływ zmian, canary bywa po prostu rozsądniejsze. A skoro wybór strategii zależy od ryzyka, trzeba też uczciwie powiedzieć, co najczęściej psuje cały proces.
Najczęstsze pułapki, które psują bezprzestojowy release
Widziałem wdrożenia, które technicznie były poprawne, a mimo to użytkownicy tracili sesje albo dostawali błędy, bo jedna zależność została pominięta. Najczęściej nie zawodzi sam przełącznik ruchu. Zawodzi wszystko, co było ukryte pod spodem: schema, cache, kolejki, sesje i zbyt optymistyczne założenie, że nowa wersja „na pewno jakoś sobie poradzi”.
| Pułapka | Co się dzieje po przełączeniu | Jak się przed tym bronić |
|---|---|---|
| Niekompatybilny schemat bazy | Stara wersja nie rozumie nowych danych albo nowa wersja nie czyta starego formatu | Stosuj podejście expand/contract i migracje zgodne wstecz |
| Sesje trzymane lokalnie | Użytkownicy są wylogowywani albo widzą losowe zachowanie po switchu | Przenieś sesje do wspólnego magazynu, na przykład Redis, albo oprzyj się na stateless auth |
| Cache bez strategii odświeżania | Nowa wersja pokazuje stare dane albo zaczyna mieszać formaty odpowiedzi | Ustal wersjonowanie kluczy, krótsze TTL i kontrolowane purge |
| Zadania asynchroniczne bez idempotencji | Ten sam job wykona się dwa razy albo zablokuje kolejkę | Dodaj deduplikację, identyfikatory żądań i odporność na ponowienia |
| Zbyt płytkie health checki | Deploy przechodzi, ale realny ruch wywołuje ukryty błąd | Sprawdzaj nie tylko endpoint „żyje”, ale też kluczowy przepływ biznesowy |
Największa lekcja jest prosta: przełączenie środowisk nie naprawia złego modelu danych ani źle zaprojektowanego stanu aplikacji. Jeśli chcesz mieć szybki rollback, musisz z góry założyć, że nowa wersja i poprzednia będą przez chwilę żyły obok siebie. To prowadzi bezpośrednio do przygotowania backendu i infrastruktury, bo bez tego strategia robi się tylko kosztowną dekoracją.
Jak przygotować backend i infrastrukturę do takiego release’u
Ja zwykle zaczynam od pięciu obszarów, bo one decydują o tym, czy proces będzie powtarzalny, czy tylko „uda się raz”. Jeśli którykolwiek z nich jest niedopracowany, niebiesko-zielone wdrożenie nie przyspiesza pracy zespołu, tylko przesuwa problem z momentu wdrożenia na moment przełączenia.
| Obszar | Co musi być gotowe | Dlaczego to ważne |
|---|---|---|
| Aplikacja | Możliwość pracy bez stanu lokalnego i bez zależności od pojedynczej instancji | Ułatwia przełączenie ruchu bez utraty sesji i danych |
| Baza danych | Zmiany schematu w trybie zgodnym wstecz | Stara i nowa wersja mogą działać równolegle podczas migracji |
| Routing | Precyzyjne sterowanie ruchem na poziomie LB, ingressu albo platformy | Przełączenie jest szybkie i odwracalne |
| Monitoring | Metryki techniczne i biznesowe, a nie tylko „podniósł się proces” | Pozwala ocenić, czy nowa wersja naprawdę działa |
| Automatyzacja | Jednoznaczny proces deployu, testów i rollbacku | Redukuje ryzyko błędu ludzkiego w krytycznym momencie |
| Koszt | Akceptacja równoległej pojemności przez cały czas lub przynajmniej w oknie release’u | Bez tego strategia nie ma ekonomicznego uzasadnienia |
W praktyce najbardziej niedoceniane są migracje bazy i obserwowalność. Możesz mieć perfekcyjny routing, a i tak polec na schemacie, który nie wspiera dwóch wersji aplikacji naraz. Możesz też mieć poprawne wdrożenie, ale bez dobrych metryk nie zauważysz regresji, zanim zobaczą ją użytkownicy. Dlatego przed pierwszym przełączeniem warto zrobić jeszcze jeden, bardzo konkretny przegląd.
Co sprawdzić przed pierwszym przełączeniem, żeby nie zgadywać w produkcji
Przed pierwszym realnym switchem sprawdzam rzeczy, które zwykle wychodzą dopiero w stresie. To nie jest lista „miło by było”, tylko zestaw warunków, które oddzielają bezpieczne wdrożenie od improwizacji.
- Czy rollback działa w obu kierunkach i czy zespół potrafi go wykonać bez zaglądania do dokumentacji?
- Czy zielone środowisko ma te same sekrety, zmienne i uprawnienia co środowisko aktywne?
- Czy kluczowe przepływy biznesowe przeszły testy na danych podobnych do produkcyjnych?
- Czy kolejki, joby cykliczne i webhooks są odporne na ponowne wykonanie?
- Czy ustalono próg, po którym przełączasz z powrotem, zamiast „jeszcze chwilę obserwować”?
- Czy stare środowisko zostaje utrzymane wystarczająco długo po switchu, by złapać opóźnione błędy?
Jeśli miałbym zostawić jedną praktyczną zasadę, byłaby taka: ta strategia działa najlepiej tam, gdzie aplikacja jest przygotowana na współistnienie dwóch wersji przez krótki czas. Gdy backend, baza i routing są dojrzałe, dostajesz szybki release i prosty rollback. Gdy nie są, technika tylko ujawnia słabości wcześniej, niż byś chciał. I właśnie dlatego w zespole backend i DevOps warto traktować ją nie jako efektowny pattern, lecz jako test dojrzałości całego procesu dostarczania zmian.