Warstwa pośrednia między aplikacją a usługami domenowymi potrafi mocno uprościć życie, ale tylko wtedy, gdy jest dobrze dobrana do produktu. W tym artykule pokazuję, czym jest wzorzec backend for frontend, kiedy faktycznie rozwiązuje problem, czym różni się od API gateway i jak podejść do wdrożenia w Pythonie oraz w praktyce DevOps. Skupiam się na tym, co pomaga zespołowi dostarczać szybsze i stabilniejsze frontendy, a nie na teoretycznej elegancji architektury.
W skrócie, chodzi o backend dopasowany do jednego konkretnego interfejsu
- Każdy klient dostaje własną warstwę, która agreguje i przekształca dane pod jego potrzeby.
- Najwięcej zysku widać wtedy, gdy web, mobile i panel administracyjny nie potrzebują identycznych odpowiedzi.
- To nie jest miejsce na reguły biznesowe core, tylko na logikę adaptacyjną, autoryzację i kompozycję odpowiedzi.
- W Pythonie dobrze sprawdzają się rozwiązania lekkie i czytelne, szczególnie gdy BFF ma sporo wywołań do usług downstream.
- W DevOps największą różnicę robią testy kontraktowe, obserwowalność i niezależny pipeline wdrożeniowy.
Czym jest warstwa BFF i dlaczego w ogóle powstała
Backend for frontend to wzorzec architektoniczny, w którym jeden, wyspecjalizowany backend obsługuje konkretny interfejs użytkownika, na przykład aplikację webową, mobilną albo panel administracyjny. Zamiast jednego uniwersalnego API, które ma zadowolić wszystkich, dostajesz warstwę dopasowaną do jednego kontekstu użycia.
To rozwiązuje kilka bardzo konkretnych problemów. Po pierwsze, ogranicza overfetching, czyli pobieranie większej ilości danych, niż klient naprawdę potrzebuje. Po drugie, zmniejsza underfetching, kiedy frontend musi dopytywać o kolejne fragmenty informacji, bo pojedyncza odpowiedź jest zbyt uboga. Po trzecie, pozwala ukryć przed UI złożoność kilku usług backendowych, które same w sobie nie muszą znać wymagań konkretnego ekranu.
W praktyce ten wzorzec jest najczęściej mały, wyspecjalizowany i mocno sprzężony z jednym doświadczeniem użytkownika. I właśnie to sprzężenie jest jego siłą, bo ułatwia zmiany w UI bez rozrywania wspólnego kontraktu dla wszystkich klientów. Jeśli jednak aplikacja ma tylko jeden kanał i prosty model danych, zysk bywa niewielki. Dalej pokazuję, jak wygląda taki przepływ od środka.
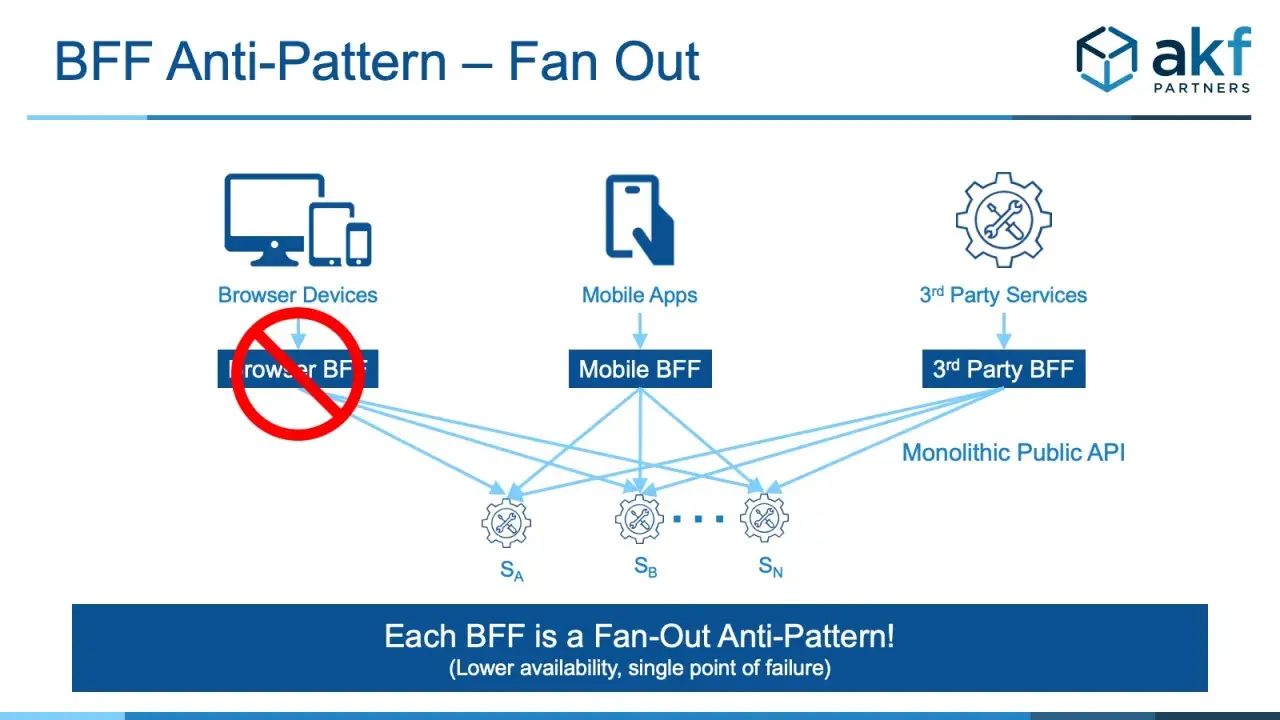
Jak działa to rozwiązanie w typowym systemie
Najprostszy scenariusz wygląda tak: frontend wysyła jedno żądanie do warstwy BFF, a ta robi resztę pracy za niego. Z punktu widzenia klienta wszystko nadal wygląda jak zwykłe API, ale po drodze dzieje się więcej niż w klasycznym modelu REST.
- Frontend prosi o dane dla konkretnego widoku, na przykład ekranu zamówienia lub dashboardu.
- BFF weryfikuje sesję, token lub inny mechanizm dostępu.
- Warstwa pośrednia wywołuje zwykle 2 do 5 usług downstream, czasem więcej, jeśli widok jest rozbudowany.
- Odpowiedzi są łączone, filtrowane i przekształcane do formatu wygodnego dla UI.
- Jeśli to potrzebne, BFF dokłada cache, retry albo prostą politykę fallbacku.
Najważniejsze jest to, że BFF nie tylko przekazuje dane. On je orkiestruje, czyli steruje kolejnością wywołań, kompozycją odpowiedzi i dopasowaniem formatu. To dlatego ta warstwa często kończy się tam, gdzie kończy się odpowiedzialność frontendowca, a zaczyna komfort pracy użytkownika. Właśnie ten punkt przejścia decyduje, czy BFF ma sens biznesowy, czy jest tylko kolejną warstwą do utrzymania.
Kiedy ten wzorzec daje największą wartość
Nie budowałbym BFF dla samej idei. Najwięcej sensu ma wtedy, gdy różne interfejsy naprawdę mają różne potrzeby, a wspólny backend zaczyna działać jak hamulec. Poniżej zestawiam sygnały, które w praktyce najczęściej mnie do tego prowadzą.
| Sygnał | Co to znaczy w praktyce | Dlaczego BFF pomaga |
|---|---|---|
| Web i mobile potrzebują innych danych | Ten sam zasób ma inny kształt, wagę i rytm odświeżania | Warstwa pośrednia może zwracać różne odpowiedzi bez duplikowania logiki w kliencie |
| Jeden ekran składa się z kilku usług | Frontend musiałby wykonywać kilka osobnych wywołań | BFF zbiera dane po stronie serwera i upraszcza kod UI |
| Zespół frontowy blokuje się na backendzie | Zmiana w UI wymaga negocjacji wspólnego kontraktu z wieloma zespołami | Frontend dostaje własny punkt integracji i większą autonomię |
| Masz różne wymagania bezpieczeństwa | Inaczej obsługujesz przeglądarkę, inaczej aplikację mobilną, inaczej panel admina | BFF może trzymać tokeny, sesję lub logikę autoryzacji bliżej serwera |
| Różne kanały mają różną wydajność | Mobile potrzebuje krótszych odpowiedzi i mniejszych payloadów | Możesz odchudzić odpowiedzi bez psucia API dla innych klientów |
Jeśli masz jeden frontend, prosty CRUD i niewiele zależności, taka warstwa zwykle nie daje zwrotu. Wtedy lepiej pozostać przy prostym API i nie mnożyć odpowiedzialności. Gdy jednak kanałów jest kilka i każdy ma własną logikę interakcji, BFF zaczyna oszczędzać czas od pierwszego większego releasu. Następny krok to porównanie go z rozwiązaniami, które najłatwiej pomylić z tym wzorcem.
BFF kontra API gateway i wspólne REST API
Te trzy podejścia często pojawiają się w tej samej rozmowie, ale rozwiązują inne problemy. Dla porządku rozkładam je na proste różnice, bo w projektach produktowych właśnie tu najłatwiej o niepotrzebny chaos.
| Rozwiązanie | Najlepiej działa, gdy | Mocne strony | Ograniczenia |
|---|---|---|---|
| BFF | Każdy frontend ma własne potrzeby i własny rytm zmian | Dopasowanie odpowiedzi, mniejsza złożoność po stronie UI, lepsza autonomia zespołów | Dodatkowa usługa do utrzymania, ryzyko rozrostu odpowiedzialności |
| API gateway | Chcesz jeden punkt wejścia, routing, rate limiting i wspólne zasady bezpieczeństwa | Centralizacja, prostsze egzekwowanie polityk, dobra kontrola ruchu | Zwykle nie rozwiązuje problemu dopasowania danych do konkretnego UI |
| Wspólne REST API | Masz prosty system i niewiele typów klientów | Mniej warstw, niższy koszt operacyjny, prostsza obsługa | Słabo skaluje się tam, gdzie fronty mają różne potrzeby i tempo zmian |
W praktyce te podejścia mogą współistnieć. Gateway stoi na brzegu systemu, pilnuje ruchu i reguł dostępu, a BFF siedzi bliżej konkretnego klienta i dopasowuje odpowiedzi. To ważne rozróżnienie, bo mieszanie tych ról prowadzi do architektury, w której nikt nie wie, gdzie kończy się routing, a zaczyna logika produktu. Gdy to już jest jasne, można przejść do implementacji, szczególnie w środowisku Pythonowym.
Jak podejść do implementacji w Pythonie i DevOps
Gdy projektuję taką warstwę, zaczynam od zasady, że BFF ma być cienki, a nie sprytny. Ma łączyć, transformować i chronić klienta przed złożonością backendu, ale nie powinien przejmować reguł domenowych, które należą do usług core.
Wybierz narzędzie, które nie zrobi z BFF kolejnego monolitu
W ekosystemie Pythona najczęściej widzę dwa sensowne kierunki. FastAPI dobrze sprawdza się tam, gdzie BFF ma być lekki, szybki i mocno oparty na typach oraz walidacji. To dobry wybór, jeśli warstwa głównie agreguje dane, a zespół chce czytelnych kontraktów i asynchronicznych wywołań do innych usług.
Django REST Framework bywa lepszy, gdy ekipa już żyje w ekosystemie Django, potrzebuje wbudowanej administracji, prostego modelu uprawnień i szybkiego wykorzystania istniejącego ORM. W obu przypadkach kluczowa jest jedna rzecz: BFF ma obsługiwać logikę integracyjną, a nie rosnąć w mini-ERP z własnym światem reguł.
Jeśli widzisz, że jedna usługa BFF zaczyna zawierać rozbudowane warunki biznesowe, to zwykle sygnał, że granica została postawiona źle. I właśnie dlatego kolejny element to dyscyplina operacyjna, nie tylko framework.
Przeczytaj również: Co to jest klasyczny ASP? Działanie, DevOps i kiedy migrować
Zadbaj o wdrożenie, testy i obserwowalność
W DevOps największy błąd polega na traktowaniu BFF jak zwykłego endpointu. To nadal osobna usługa, więc potrzebuje własnego cyklu życia, własnego monitoringu i własnej odpowiedzialności za wydajność. Przy 3 do 6 wywołań downstream na jeden request bez śledzenia trace’ów zaczynasz zgadywać, a nie diagnozować.
- Wydziel osobny pipeline CI/CD dla BFF, nawet jeśli reszta systemu ma wspólne repozytorium.
- Dodaj testy kontraktowe, żeby frontend nie rozjechał się z odpowiedzią po cichu.
- Ustaw timeouty, retry z limitem i mechanizmy odcinania awarii, bo jedna wadliwa usługa nie powinna blokować całego widoku.
- Mierz latencję, liczbę błędów i cache hit ratio na poziomie pojedynczych endpointów.
- Włącz tracing rozproszony, bo bez niego nie zobaczysz, który downstream zjada czas odpowiedzi.
To właśnie połączenie dobrego kodu i dobrych praktyk operacyjnych decyduje, czy BFF upraszcza system, czy tylko dokładania pracy zespołowi. Kiedy te fundamenty są ustawione, pozostaje już głównie uniknąć kilku klasycznych błędów.
Najczęstsze błędy, które psują korzyści
Największe problemy z tym wzorcem nie biorą się z samej idei, tylko z jej złego użycia. Widziałem kilka powtarzalnych błędów i prawie zawsze kończyły się podobnie: większą złożonością bez realnego zysku.
- Przenoszenie logiki domenowej do BFF - warstwa pośrednia zaczyna decydować o cenach, statusach i regułach biznesowych, choć powinna tylko adaptować dane.
- Zbyt wiele osobnych BFF-ów - jeśli każdy ekran dostaje własną usługę, utrzymanie szybko robi się droższe niż korzyść z dopasowania.
- Brak właściciela - frontend, backend i DevOps zakładają, że „ktoś inny” to utrzyma, więc odpowiedzialność się rozmywa.
- Za słaba obserwowalność - bez metryk i trace’ów nie da się ocenić, czy problem leży w BFF, czy w usługach źródłowych.
- Ukrywanie problemów architektonicznych - BFF nie naprawi źle pociętej domeny ani chaotycznych mikroserwisów, może je tylko na chwilę zasłonić.
- Traktowanie warstwy jak cache wszystkiego - cache pomaga, ale nie zastępuje sensownego modelu danych i spójnych kontraktów.
Jeśli chcesz, by ta architektura faktycznie pomagała, musisz pilnować granicy między adaptacją a biznesem. To nie jest detal, tylko warunek, bez którego wzorzec bardzo szybko traci sens. Na końcu zostawiam krótką listę rzeczy, które sprawdzam, zanim sam rekomenduję takie rozwiązanie.
Co sprawdzić przed wdrożeniem własnej warstwy
Zanim dorzucę kolejny komponent do systemu, zadaję sobie kilka bardzo prostych pytań. Jeżeli odpowiedzi są niejasne, zwykle oznacza to, że BFF jest jeszcze przedwczesny.
- Czy istnieje więcej niż jeden istotnie różny klient, na przykład web, mobile i panel administracyjny?
- Czy jeden widok składa dane z kilku usług i przez to front robi się ciężki w utrzymaniu?
- Czy problemem jest dopasowanie odpowiedzi do UI, a nie sama logika domenowa?
- Czy zespół potrafi utrzymać osobny deployment, monitoring i testy tej warstwy?
- Czy jesteś w stanie zmierzyć efekt, na przykład mniej requestów po stronie klienta, krótszy czas renderu albo prostszy kod frontendu?
Jeśli na większość tych pytań odpowiadasz „tak”, BFF ma realne uzasadnienie. Jeśli nie, lepiej zacząć od prostszego API i wrócić do tematu dopiero wtedy, gdy pojawi się wyraźny rozdźwięk między potrzebami klientów. W architekturze wygrywa nie najbardziej efektowna warstwa, tylko ta, która usuwa konkretny koszt po stronie produktu i zespołu.