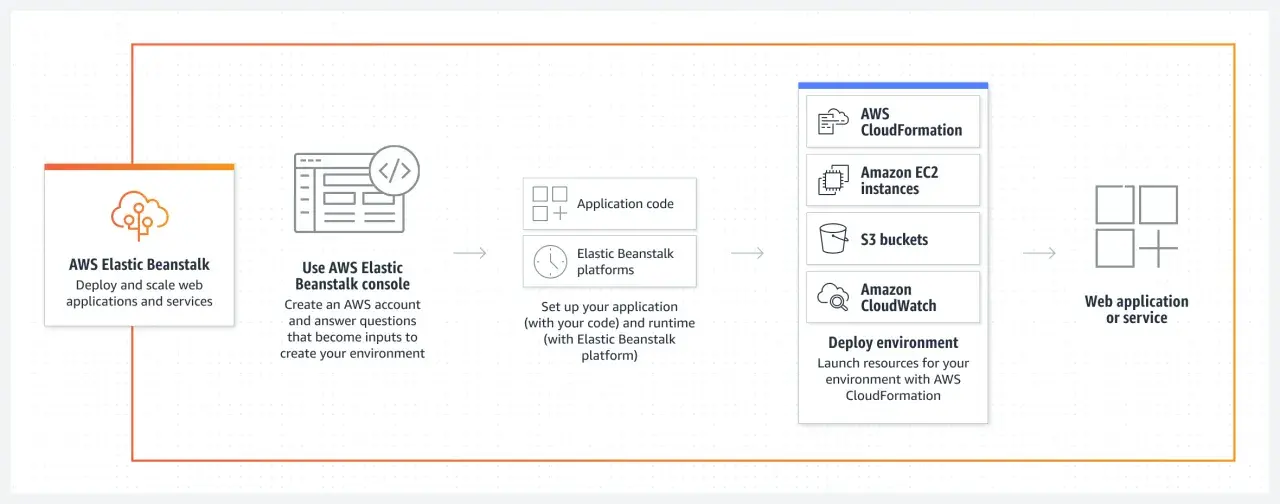
To narzędzie przydaje się wtedy, gdy chcesz szybko uruchomić aplikację webową na AWS, ale nie chcesz od razu składać całego stosu infrastruktury ręcznie. W tym artykule pokazuję, jak działa Elastic Beanstalk w praktyce, kiedy ma sens w backendzie i DevOps, ile daje automatyzacji oraz gdzie zaczynają się jego ograniczenia. Jeśli pracujesz w Pythonie, znajdziesz tu też konkretne wskazówki wdrożeniowe, które realnie ułatwiają życie.
Najważniejsze rzeczy, które warto wiedzieć przed wdrożeniem aplikacji na AWS
- Usługa automatyzuje provisioning, load balancing, auto scaling i monitoring, ale nie zabiera całej kontroli nad środowiskiem.
- Najlepiej sprawdza się przy klasycznych aplikacjach webowych, zwłaszcza w Pythonie, Django i Flasku.
- Według AWS nie ma opłaty za samą usługę, płacisz za zasoby, które uruchamiasz pod aplikacją.
- Pod spodem działają m.in. EC2, Auto Scaling, Elastic Load Balancing, S3 i CloudWatch.
- Im prostszy deployment i stabilniejsza architektura, tym większy zwrot z użycia tej platformy.
Czym jest Elastic Beanstalk i kiedy naprawdę pomaga
Najkrócej mówiąc, to warstwa zarządzania wdrożeniem aplikacji webowych na AWS. Wrzucasz kod, wybierasz platformę, a usługa przygotowuje środowisko, uruchamia zasoby i pilnuje podstawowej obsługi produkcyjnej: skalowania, równoważenia ruchu i monitoringu. Ja traktuję ją jako sensowny kompromis między pełnym ręcznym zarządzaniem serwerami a cięższymi platformami kontenerowymi.
Ta opcja ma największy sens wtedy, gdy zespół chce dowozić funkcje, a nie spędzać tygodni na składaniu infrastruktury. Dobrze pasuje do monolitów, paneli administracyjnych, API i klasycznych aplikacji w Pythonie, zwłaszcza jeśli bazują na WSGI, mają przewidywalny ruch i nie wymagają bardzo złożonej topologii sieciowej. Jeśli aplikacja jest już mocno kontenerowa, rozproszona albo wymaga specyficznych komponentów DevOps, zaczyna się robić mniej wygodnie.
W praktyce warto myśleć o tej usłudze jak o narzędziu do przyspieszenia startu i uporządkowania podstaw. Nie jest to magiczna skrzynka, która rozwiązuje wszystkie problemy operacyjne. To raczej szybka ścieżka do stabilnego wdrożenia, o ile wiesz, czego od niej oczekujesz. Następny krok to zobaczenie, jak wygląda sam proces uruchamiania aplikacji.
Jak wygląda wdrożenie krok po kroku
Proces jest prosty, ale jego sens widać dopiero wtedy, gdy rozbijesz go na etapy. Najpierw wybierasz platformę, na przykład Python, konfigurujesz środowisko i przekazujesz paczkę aplikacji. Potem usługa zajmuje się resztą: tworzy zasoby, podłącza je do ruchu i sprawdza, czy nowa wersja przechodzi testy zdrowia.
- Wybierasz platformę dopasowaną do języka i sposobu uruchamiania aplikacji.
- Przekazujesz kod razem z konfiguracją, zmiennymi środowiskowymi i ewentualnymi plikami statycznymi.
- Usługa tworzy środowisko i uruchamia instancje, load balancer oraz warstwę automatycznego skalowania.
- Sprawdza zdrowie aplikacji przez health checks i podstawowe metryki.
- Wdraża kolejne wersje z użyciem wybranej strategii publikacji.
W Pythonie zwykle dochodzi jeszcze konfiguracja WSGI, zmiennych środowiskowych i statycznych zasobów. AWS opisuje to dość jasno: możesz ustawiać takie rzeczy jak proxy, mapowanie plików statycznych czy ścieżkę WSGI bez grzebania w każdym serwerze z osobna. To ważne, bo wiele problemów z wdrożeniem nie wynika z samego kodu, tylko z tego, że konfiguracja aplikacji i infrastruktury rozjeżdżają się po drodze.
Gdy już wiesz, jak przebiega wdrożenie, warto przyjrzeć się temu, co faktycznie dzieje się pod spodem, bo właśnie tam ukrywa się większość kosztów i większość korzyści.
Co dzieje się pod spodem i za co naprawdę płacisz
Ta usługa nie działa w próżni. Pod spodem korzysta z EC2, Auto Scaling, Elastic Load Balancing, S3, CloudWatch i często także z SNS oraz RDS. To dlatego z jednej strony upraszcza start, a z drugiej pozostawia ci realny wpływ na instancje, typy maszyn, sieć, bazy danych i polityki wdrożeń.
| Komponent | Rola | Dlaczego ma znaczenie |
|---|---|---|
| EC2 | Uruchamia aplikację na instancjach obliczeniowych | To główny koszt i główne miejsce strojenia wydajności |
| Auto Scaling | Dodaje lub usuwa instancje zależnie od obciążenia | Chroni przed przeciążeniem i nadpłacaniem za bezczynne zasoby |
| Elastic Load Balancing | Rozdziela ruch między instancje | Poprawia dostępność i umożliwia bezpieczniejsze wdrożenia |
| S3 | Przechowuje artefakty i elementy pomocnicze | Ułatwia deploy, archiwizację i przenoszenie wersji |
| CloudWatch | Zbiera metryki, logi i alarmy | Bez tego trudno sensownie zarządzać produkcją |
Według AWS za samą usługę nie ma dodatkowej opłaty. Płacisz za zasoby, które faktycznie uruchamiasz, a główne koszty zwykle robią instancje EC2, load balancer, transfer danych oraz ewentualna baza. To uczciwy model, ale trzeba go pilnować, bo w prostym projekcie rachunek potrafi urosnąć szybciej, niż się spodziewasz, jeśli dasz zbyt duże instancje albo zostawisz nadmiarowe środowiska testowe.
W praktyce dostajesz też kilka strategii wdrożenia, które robią dużą różnicę przy większym ruchu. Rolling update zmienia instancje partiami, rolling z dodatkową partią utrzymuje pełną pojemność, immutable buduje nowe środowisko przed przełączeniem ruchu, a traffic splitting kieruje część użytkowników na nową wersję i ułatwia kontrolowany rollout. AWS zaznacza też, że przy traffic splitting liczba instancji w tymczasowej grupie jest taka sama jak w oryginalnej, więc chwilowy koszt i zapotrzebowanie na zasoby rosną.
Z tej warstwy wynika najważniejszy kompromis: oszczędzasz czas, ale nie dostajesz pełnej swobody jak na gołym EC2. I właśnie dlatego warto uczciwie porównać to rozwiązanie z alternatywami.
Zalety i ograniczenia, o których łatwo zapomnieć
Największa zaleta jest prosta: szybko przechodzisz od kodu do działającej aplikacji. Nie musisz ręcznie składać klastra, stawiać load balancera, pisać wszystkich skryptów wdrożeniowych i ciągle pilnować podstawowych alarmów. To dobre rozwiązanie dla zespołów, które chcą mieć DevOps w wersji pragmatycznej, a nie rytualnej.
Druga zaleta to zachowanie kontroli nad zasobami. AWS wprost podkreśla, że nie zamyka ci drogi do EC2, EBS, stref dostępności, logowania na instancje czy dodatkowych ustawień środowiska. Ja uważam to za mocny punkt tej platformy, bo pozwala zacząć prosto, a potem stopniowo przejmować więcej kontroli tam, gdzie naprawdę jest potrzebna.
| Kryterium | Ta usługa | EC2 | Kontenery na ECS/EKS |
|---|---|---|---|
| Szybkość startu | Wysoka | Niska | Średnia |
| Poziom kontroli | Średni | Wysoki | Wysoki |
| Złożoność utrzymania | Niska do średniej | Wysoka | Średnia do wysokiej |
| Najlepsze zastosowanie | Klasyczne aplikacje webowe i API | Pełna customizacja środowiska | Architektura kontenerowa i mikroserwisy |
| Typowy profil zespołu | Mały lub średni zespół produktowy | Zespół z mocnym naciskiem na infrastrukturę | Zespół nastawiony na platform engineering |
Ograniczenie pojawia się wtedy, gdy projekt zaczyna wymagać rzeczy, których usługa nie ukrywa w wygodny sposób. Jeśli potrzebujesz nietypowego routingu, skomplikowanej orkiestracji usług, sidecarów, rozbudowanych sieci między usługami albo bardzo specyficznego modelu uruchamiania procesów, szybciej trafisz na ścianę. Wtedy zwykle lepszą drogą staje się ECS, EKS albo zwykłe EC2 z własną automatyzacją.
Jest jeszcze jeden praktyczny minus: łatwo zbytnio zaufać domyślnej konfiguracji. Domyślne alarmy, limity i strategie wdrożenia są dobrym startem, ale nie są odpowiedzią na każdy ruch produkcyjny. W kolejnej sekcji pokazuję, jak korzystać z tej platformy rozsądnie, szczególnie w projektach Pythona.
Jak używać go sensownie w projektach Pythona
Jeśli budujesz aplikację w Pythonie, traktuj tę usługę jako narzędzie do uproszczenia uruchomienia, a nie jako wymówkę do chaosu w konfiguracji. Najlepiej działa z aplikacjami WSGI, czyli na przykład z Django i Flaskiem, gdzie struktura wdrożenia jest przewidywalna, a zależności można łatwo opisać w pliku konfiguracyjnym i zmiennych środowiskowych.
Ja zwykle zwracam uwagę na pięć rzeczy. Po pierwsze, trzymaj sekrety poza kodem i korzystaj ze zmiennych środowiskowych. Po drugie, zadbaj o osobny endpoint health check, bo bez niego trudno sensownie ocenić stan aplikacji. Po trzecie, nie opieraj trwałości danych na lokalnym dysku instancji, bo po wymianie maszyny wszystko przepada. Po czwarte, logi kieruj do miejsca, z którego da się je faktycznie czytać i przeszukiwać. Po piąte, migracje bazy i zadania jednorazowe rozdziel od zwykłego procesu uruchamiania, żeby nie blokować deploya.
Warto też uważać na aktualizacje platformy i sposób publikacji. Managed platform updates są wygodne, ale trzeba rozumieć, kiedy wejść w wersję immutable, a kiedy wystarczy rolling update. Przy ruchu produkcyjnym to robi realną różnicę, bo minimalizuje ryzyko, że nowa wersja popsuje działającą aplikację. Jeśli w projekcie masz intensywny async, WebSockety albo bardzo specyficzny model uruchamiania procesów, często rozsądniej od razu iść w kontenery, zamiast później dopasowywać się do ograniczeń po fakcie.
W praktyce ta platforma najlepiej działa tam, gdzie ważniejsze jest szybkie i przewidywalne wdrażanie niż absolutna swoboda. I właśnie na tej osi decyzji zamyka się cały temat wyboru narzędzia.
Co wybrałbym przy nowym projekcie i kiedy nie iść tą drogą
Gdybym startował z nowym backendem w Pythonie, wybrałbym tę usługę wtedy, gdy projekt jest jeszcze prosty, zespół niewielki, a celem jest szybkie wejście na produkcję bez budowania własnej platformy operacyjnej. To bardzo dobry wybór dla aplikacji biznesowych, paneli, prostych API i monolitów, które mają rosnąć stopniowo.
Nie wybrałbym jej jako domyślnego rozwiązania dla dużej architektury mikroserwisowej, systemów o wysokiej złożoności sieciowej albo projektów, w których od początku potrzebujesz ścisłej kontroli nad orkiestracją kontenerów. W takich przypadkach lepiej od razu postawić na narzędzie, które naturalnie pasuje do skali i struktury systemu, zamiast próbować rozciągać prostszą usługę poza jej mocne strony.
Jeśli mam dać jedną praktyczną radę, to byłaby ona taka: zaczynaj od prostoty, ale nie ignoruj ścieżki wzrostu. Dla wielu zespołów EB jest dobrym pierwszym krokiem, bo pozwala skupić się na produkcie, a nie na ręcznym stawianiu serwerów. Gdy ograniczenia zaczną naprawdę boleć, migracja do bardziej zaawansowanej architektury będzie decyzją opartą na faktach, a nie na modzie.