Prefetching to technika wstępnego pobierania danych zanim program rzeczywiście ich potrzebuje. W praktyce chodzi o skrócenie czekania na pamięć, dysk, sieć albo kolejną stronę aplikacji, ale tylko wtedy, gdy da się przewidzieć następny krok. Pokażę, jak ten mechanizm działa, kiedy przynosi realny zysk i jak użyć go rozsądnie w prostym projekcie.
Najważniejsze rzeczy o prefetchingu, które warto zapamiętać
- Najlepiej działa tam, gdzie kolejny odczyt da się przewidzieć z dużą pewnością.
- Sprzęt zwykle pobiera całą linię cache, nie pojedynczy bajt, więc zysk opiera się na lokalności danych.
- Zbyt agresywne wyprzedzenie potrafi wypchnąć potrzebne dane z cache i obniżyć wydajność.
- W Pythonie najczęściej opłaca się przy danych z API, bazy, plików i kolejkach zadań I/O-bound.
- Prefetching, cache, preload i lazy loading rozwiązują podobny problem, ale w inny sposób.
Jak działa wstępne pobieranie danych
Mechanizm jest prosty tylko na pierwszy rzut oka. Program albo sprzęt zakłada, że skoro właśnie użyłeś jednej porcji danych, za chwilę przydadzą się sąsiednie elementy lub następny dokument, więc pobiera je wcześniej, najczęściej w tle. Największy sens ma to wtedy, gdy wzorzec dostępu jest przewidywalny i nie trzeba zgadywać zbyt daleko.
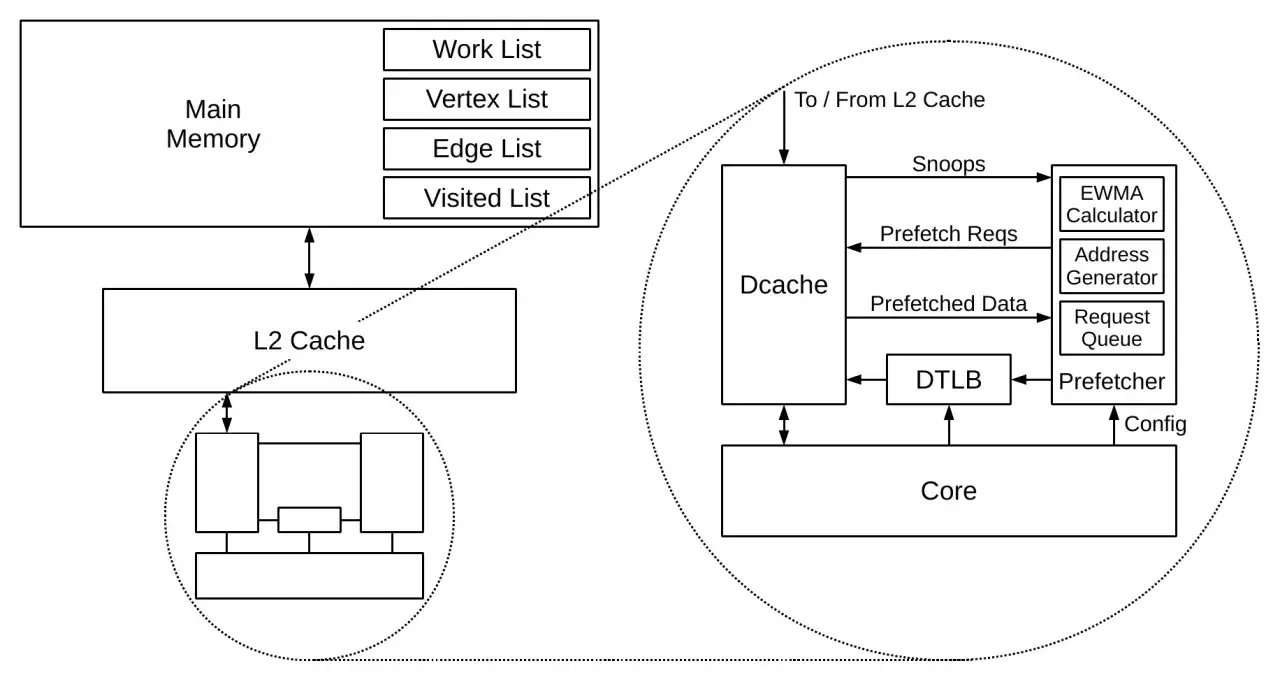
W procesorach i bibliotekach ten sam pomysł działa na różnych poziomach pamięci: od cache L1 i L2 po pamięć główną. Jak opisuje Intel, nawet jeśli prosisz o pojedynczy element, sprzęt zwykle działa na poziomie całych linii cache, bo to one są naturalną jednostką opłacalnego pobierania.
| Wariant | Co pobiera wcześniej | Gdzie spotkasz | Największy plus | Ryzyko |
|---|---|---|---|---|
| Prefetch sprzętowy | Linie cache i sąsiednie dane | Procesory, pamięć, pętle liniowe | Działa automatycznie bez zmian w kodzie | Przy chaotycznym dostępie trafia w próżnię |
| Prefetch programowy | Dokładnie wskazane dane | Kod niskopoziomowy, biblioteki, HPC | Daje większą kontrolę nad momentem pobrania | Łatwo pobrać za wcześnie albo za późno |
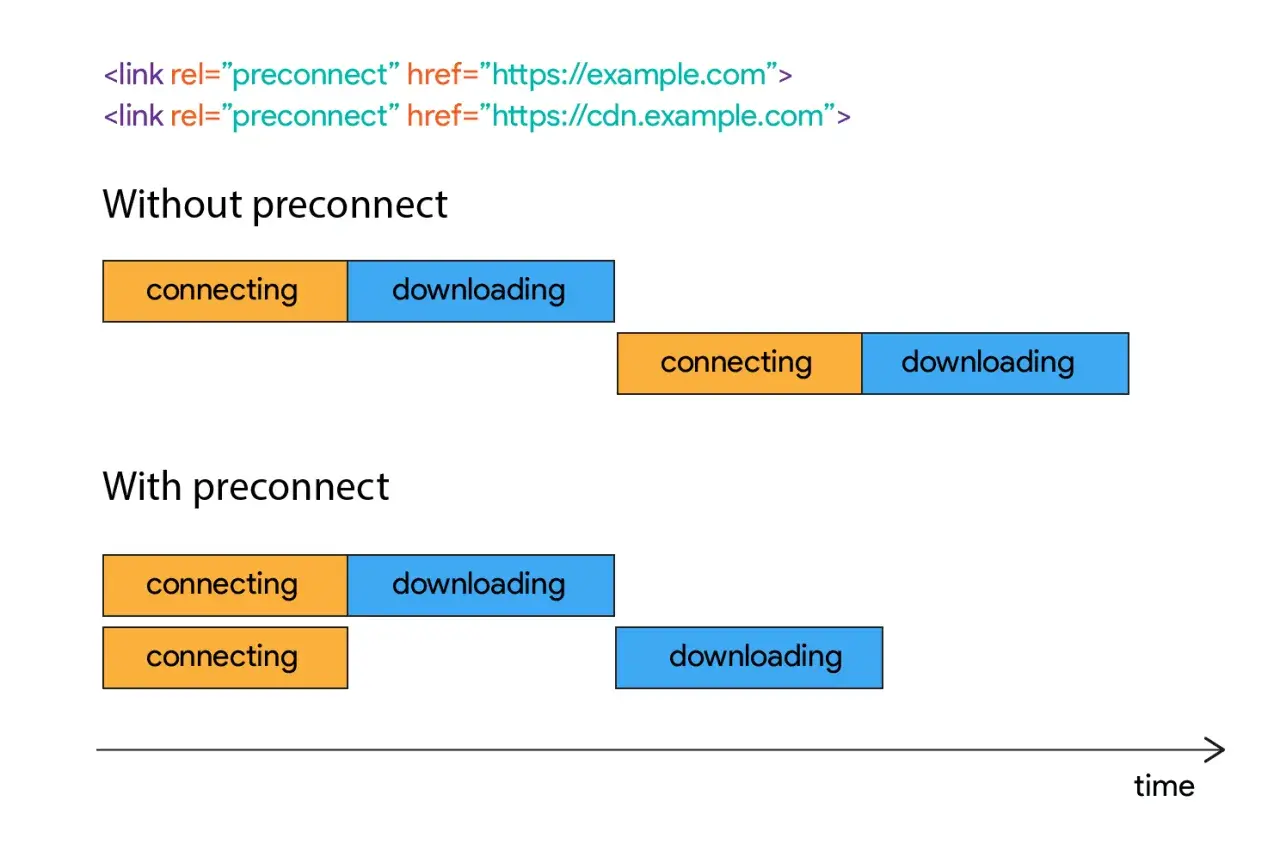
| Prefetch webowy | Następny dokument albo zasób | Przeglądarki, aplikacje internetowe | Skraca czas przejścia do kolejnej strony | Zależy od cache, nagłówków i polityki przeglądarki |
Dobrze jest myśleć o prefetchingu jak o wyciąganiu kolejki o jeden lub dwa kroki do przodu, a nie jak o magicznym przyspieszaczu wszystkiego. To prowadzi prosto do pytania, kiedy taki ruch naprawdę daje odczuwalny zysk.
Gdzie prefetching daje realny zysk
Największe korzyści widzę tam, gdzie jedna porcja danych naturalnie wynika z poprzedniej. Wtedy można ukryć latencję za pracą, którą program i tak wykonuje.
- Pętle po tablicach i buforach - odczyt kolejnych elementów jest liniowy, więc prefetcher ma czym się kierować.
- Przetwarzanie plików w blokach - kiedy analizujesz bieżący blok, następny może już lądować w pamięci.
- Strony aplikacji i kolejne widoki - jeśli użytkownik prawie na pewno przejdzie dalej, można przygotować zasoby wcześniej.
- Zapytania do API i bazy - po pobraniu jednej strony wyników można dociągnąć następną, zanim użytkownik skończy czytać obecną.
- Pipeline ETL i zadania wsadowe - pobieranie danych z wyprzedzeniem ogranicza przestoje między etapami.
To działa dlatego, że czas oczekiwania nie znika, tylko zostaje przesunięty poza krytyczną ścieżkę. Jeśli potrafisz przewidzieć kolejny krok z dużym prawdopodobieństwem, system sprawia wrażenie szybszego bez zwiększania mocy obliczeniowej. Jeśli wzorzec jest zbyt chaotyczny, mechanizm zaczyna marnować zasoby.
Kiedy prefetching szkodzi bardziej niż pomaga
Jak pokazuje dokumentacja Intela, zbyt dalekie wyprzedzenie może sprawić, że dane zostaną wyrzucone z cache, zanim program po nie sięgnie. Wtedy zamiast przyspieszenia dostajesz dodatkowy ruch w pamięci, większą presję na kolejki i czasem nawet gorszy wynik niż przed zmianą.
- Losowy dostęp do danych - grafy, drzewa i rozrzucone rekordy są trudne do przewidzenia, więc trafność prefetchu spada.
- Zbyt duże wyprzedzenie - dane mogą się zestarzeć w cache, zanim staną się potrzebne.
- Mały cache i duża konkurencja - inne wątki lub procesy mogą potrzebować tych samych zasobów.
- Ograniczona sieć lub bateria - na urządzeniach mobilnych dodatkowy transfer i praca tła mogą kosztować więcej niż oszczędzają.
- Web z restrykcjami cache - klasyczny prefetch bywa blokowany przez nagłówki cache albo ograniczany przez cache partitioning, więc nie zawsze daje się wykorzystać tak, jak planujesz.
W przeglądarkach dochodzi jeszcze praktyczny szczegół: zasób pobrany z wyprzedzeniem nie zawsze jest używalny poza tym samym kontekstem witryny, a stare podejście ma więcej ograniczeń niż nowsze mechanizmy do nawigacji. Dokumentacja MDN pokazuje, że w takich scenariuszach lepiej traktować prefetching jako opcję, nie obietnicę.
Jak wdrożyć go w projekcie Pythonowym
W Pythonie najczęściej używam prefetchingu tam, gdzie koszt leży po stronie I/O, a nie samego obliczania. Najprostsza zasada brzmi: pobieraj tylko jeden krok do przodu, a potem sprawdź, czy skraca to czekanie bez rozdmuchiwania pamięci.
Ja zwykle zaczynam od fragmentu, który da się przewidzieć: następnej strony API, kolejnego rekordu z bazy albo następnego bloku pliku. Dopiero potem sprawdzam, czy nie lepiej pobierać mniejszych porcji, bo zbyt szeroki bufor często daje efekt odwrotny od zamierzonego.
from concurrent.futures import ThreadPoolExecutor
def fetch_page(page):
# np. request do API, zapytanie do bazy albo odczyt z pliku
...
def process_page(data):
# przetwarzanie bieżącej porcji
...
with ThreadPoolExecutor(max_workers=1) as pool:
future = pool.submit(fetch_page, 1)
for page in range(1, 6):
data = future.result()
future = pool.submit(fetch_page, page + 1)
process_page(data)Ten wzorzec ma sens, gdy pobieranie danych jest wolniejsze niż ich przetwarzanie, ale nadal przewidywalne. Nie przyspieszy ciężkich obliczeń CPU-bound, bo tam wąskim gardłem jest procesor, a nie czekanie na dane. Jeśli projekt już korzysta z asyncio, podobny pomysł można zrealizować bez dodatkowych wątków.
To wciąż tylko technika, nie strategia sama w sobie. Zanim uznasz ją za sukces, warto porównać ją z innymi sposobami przyspieszania ładowania, bo łatwo pomylić ją z cachingiem albo preloadem.
Prefetching, cache, preload i lazy loading to nie to samo
Te pojęcia są podobne tylko z daleka. W praktyce różnią się momentem pobrania, priorytetem i tym, czy dane są potrzebne z dużym prawdopodobieństwem, czy tylko "na wszelki wypadek".
| Technika | Co robi | Kiedy ma sens | Główne ograniczenie |
|---|---|---|---|
| Prefetching | Pobiera dane wcześniej, zanim będą potrzebne | Gdy kolejny krok jest prawdopodobny, ale nie pewny | Może zużyć cache, pamięć albo transfer na coś, co się nie przyda |
| Caching | Przechowuje już użyte dane do ponownego wykorzystania | Gdy te same dane wracają często | Wymaga trafień, inaczej nie daje zysku |
| Preload | Pobiera zasób wcześniej, bo zaraz będzie potrzebny | Gdy zasób jest krytyczny dla bieżącego renderu lub kroku | Zły dobór obniża priorytet lub blokuje ładowanie właściwych rzeczy |
| Lazy loading | Odkłada pobranie do momentu użycia | Gdy część treści nie jest potrzebna od razu | Może dodać opóźnienie przy pierwszym użyciu |
W webie klasyczny jest zwykle niskopriorytetowy i bardziej nastawiony na przyszłą nawigację, a służy do rzeczy potrzebnych niemal od razu. W dokumentacji MDN widać też, że w nowocześniejszych scenariuszach nawigacyjnych lepiej sprawdza się mechanizm oparty na Speculation Rules, bo lepiej pasuje do przewidywania kolejnych stron i ma mniej ograniczeń. Gdy to rozróżnisz, zostaje najważniejsze pytanie: czy zysk naprawdę widać w metrykach.
Jak sprawdzić, czy mechanizm rzeczywiście przyspiesza system
Tu nie wystarcza wrażenie, że "wydaje się szybciej". Jeśli prefetching ma sens, powinien poprawić czas odpowiedzi bez wyraźnego wzrostu kosztu po stronie pamięci, sieci albo energii.
- Porównaj medianę i p95 czasu odpowiedzi, czyli wartość, której nie przekracza 95 procent żądań.
- Sprawdź liczbę odwołań do dysku, sieci lub cache missów przed i po zmianie.
- Obserwuj zużycie RAM, bo dodatkowe bufory potrafią zjeść cały zysk z szybszego pobierania.
- Na urządzeniach mobilnych patrz na baterię i transfer danych, nie tylko na czas ładowania.
- Testuj na realistycznym ruchu, bo syntetyczny benchmark często nie oddaje rzeczywistego wzorca dostępu.
Jeśli poprawa jest niewielka, a koszty rosną zauważalnie, lepiej wycofać zmianę i wrócić do prostszego pobierania. Prefetching opłaca się wtedy, gdy skraca czekanie bez wprowadzania chaosu w pamięci i bez ukrytego rachunku w innych zasobach.