
Ten sposób projektowania pomaga oddzielić logikę biznesową od frameworka, bazy danych i warstwy HTTP, dzięki czemu kod jest łatwiejszy w utrzymaniu i mniej podatny na przypadkowe zależności. W tym artykule pokazuję, na czym polega clean architecture, jak wygląda podział na warstwy, jak wdrożyć ten model w projekcie Pythonowym oraz kiedy taki układ naprawdę daje przewagę, a kiedy tylko dokłada ceremonii.
Najważniejsze zasady, które porządkują kod i zależności
- Rdzeń aplikacji powinien zawierać reguły biznesowe, a nie szczegóły techniczne.
- Zależności mają iść wyłącznie do środka, nigdy odwrotnie.
- Use case to miejsce, w którym orkiestruje się działanie systemu, a nie obsługuje HTTP czy SQL.
- Adaptery i infrastruktura są wymienne, jeśli dobrze odetniesz je od domeny.
- Ten model najlepiej sprawdza się tam, gdzie logika biznesowa żyje dłużej niż technologia wokół niej.
- W prostych CRUD-ach często lepiej zacząć lżej i dopiero potem wydzielać kolejne warstwy.
Na czym polega ta architektura i jaki problem rozwiązuje
Najprościej mówiąc, chodzi o to, żeby najcenniejsza część systemu, czyli reguły biznesowe, była jak najmniej zależna od reszty świata. W praktyce oznacza to, że zmiana bazy danych, frameworka webowego albo sposobu prezentacji danych nie powinna wymuszać przepisywania logiki zamówień, rozliczeń, rezerwacji czy walidacji domenowej.
Ja patrzę na to jak na świadome odwrócenie priorytetów. W wielu projektach na początku dominuje wygoda frameworka, a dopiero później okazuje się, że biznes jest przywiązany do ORM-u, kontrolerów albo widoków. Czysta architektura odwraca ten układ: najpierw definiujesz zasady działania systemu, a dopiero potem dobierasz sposób ich technicznej realizacji.
To podejście nie jest sztuką dla sztuki. Zwykle wygrywa tam, gdzie aplikacja ma żyć długo, rosnąć warstwowo i przechodzić zmiany niezależne od technologii. Jeśli rdzeń jest dobrze odseparowany, zyskujesz łatwiejsze testowanie, prostsze refaktoryzacje i mniejsze ryzyko, że nowy framework „przyklei się” do domeny na stałe.
Warto też rozróżnić rzecz ważną z praktycznego punktu widzenia: ten styl nie polega na mnożeniu folderów, tylko na pilnowaniu granic odpowiedzialności. To właśnie granice, a nie sama liczba katalogów, decydują o jakości rozwiązania. Żeby zobaczyć, jak to działa w kodzie, trzeba rozłożyć system na warstwy.
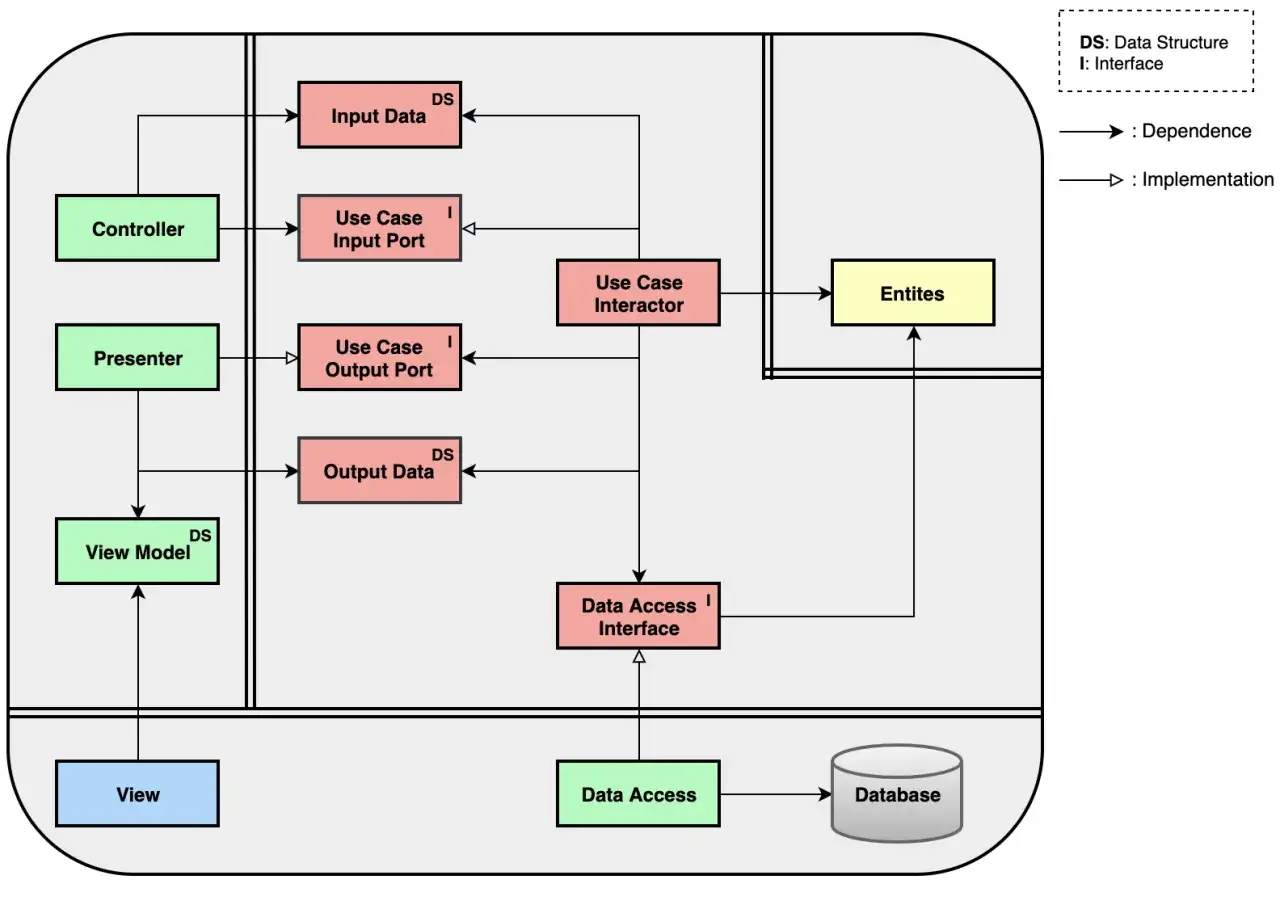
Jak wyglądają warstwy i przepływ zależności
W najbardziej użytecznym ujęciu system dzieli się na cztery obszary: domenę, warstwę aplikacyjną, adaptery oraz infrastrukturę. Każda z nich ma własny zakres odpowiedzialności, a zasada jest jedna: zależności mogą iść tylko do środka, czyli w stronę bardziej stabilnych reguł.
| Warstwa | Za co odpowiada | Czego nie powinna robić | Przykład w Pythonie |
|---|---|---|---|
| Domena | Reguły biznesowe i pojęcia kluczowe dla systemu | Nie powinna znać ORM-u, HTTP ani frameworka |
Order, Money, InvoicePolicy
|
| Warstwa aplikacyjna | Scenariusze użycia i orkiestracja procesu | Nie powinna zawierać szczegółów bazy czy interfejsu użytkownika |
PlaceOrderUseCase, CancelReservation
|
| Adaptery | Mapowanie wejścia i wyjścia między światem zewnętrznym a rdzeniem | Nie powinna przechowywać reguł biznesowych | Kontroler FastAPI, serializer, presenter |
| Infrastruktura | Konkrety techniczne: baza, kolejki, API zewnętrzne, cache | Nie powinna decydować o logice domenowej | Repozytorium SQLAlchemy, klient Stripe, Redis |
Najważniejszy element to zasada zależności. Inner layers, czyli warstwy wewnętrzne, nie powinny importować klas z zewnątrz. Domena nie może wiedzieć, że istnieje konkretny ORM, konkretna baza ani konkretny sposób obsługi requestów. To dlatego często definiuje się interfejs repozytorium w środku, a implementację w infrastrukturze.
W praktyce wygląda to tak, że use case mówi: „potrzebuję pobrać zamówienie i je zapisać”, ale nie wie, czy pod spodem siedzi PostgreSQL, plik JSON czy zewnętrzna usługa. Dzięki temu biznes pozostaje stabilny, a technika może się zmieniać bez wywracania całego projektu. To właśnie ten mechanizm sprawia, że architektura nie zamienia się w zbiór przypadkowych klas.
Gdy ten model jest już jasny, najważniejsze staje się pytanie: jak wdrożyć go w Pythonie bez przesadnej biurokracji.
Jak wdrożyć to w projekcie Pythonowym bez przesady
Najrozsądniej zacząć od domeny, a nie od folderów. Ja zwykle zaczynam od odpowiedzi na pytanie: jakie decyzje biznesowe musi podejmować system bez względu na to, czy działa przez API, CLI czy cron? Dopiero potem rozpisuję use case’y i dopinam adaptery.
app/
domain/
order.py
order_repository.py
application/
place_order.py
cancel_order.py
adapters/
http/
order_controller.py
infrastructure/
sqlalchemy_order_repository.py
payment_gateway.pyTaki układ nie jest obowiązkowy, ale dobrze pokazuje kolejność zależności. Domena trzyma model i reguły, warstwa aplikacyjna orkiestruje proces, adapter HTTP tłumaczy request na komendę, a infrastruktura dostarcza realne implementacje. Jeśli trzymasz się tej logiki, struktura folderów przestaje być dekoracją i zaczyna odzwierciedlać odpowiedzialności.
Dobry minimalny workflow wygląda zwykle tak:
- Wydziel model domenowy z regułami, które naprawdę mają znaczenie dla biznesu.
- Opisz use case jako pojedynczy scenariusz, na przykład złożenie zamówienia albo anulowanie rezerwacji.
- Zdefiniuj kontrakty dla potrzeb zewnętrznych, na przykład repozytorium lub bramkę płatności.
- Dodaj adaptery, które tłumaczą dane wejściowe i wyjściowe między światem zewnętrznym a rdzeniem.
- Na końcu połącz wszystko w jednym miejscu startowym, czyli composition root.
Composition root to po prostu miejsce, w którym sklejasz konkretne implementacje z kontraktami. To ważny termin: oznacza punkt konfiguracji aplikacji, a nie kolejną warstwę biznesową. W dobrze zrobionym projekcie ten fragment jest cienki, przewidywalny i łatwy do wymiany.
W Pythonie szczególnie dobrze działa rozdzielenie modelu od ORM-u. Zamiast robić z encji domenowej klasę SQLAlchemy, lepiej potraktować ORM jako adapter techniczny. Dzięki temu możesz testować reguły biznesowe bez bazy, a później dopiero sprawdzać mapowanie na poziomie integracyjnym. To nie jest tylko kwestia elegancji. To realnie skraca pętlę feedbacku w testach.
Jeżeli projekt ma rosnąć, testowanie zyskuje jeszcze bardziej. Use case da się sprawdzić na atrapach repozytoriów i serwisów zewnętrznych, więc większość logiki testujesz szybko i bez ciężkiej infrastruktury. To jedna z najbardziej niedocenianych zalet tego podejścia. Nie chodzi wyłącznie o porządek, ale o tempo pracy przy kolejnych zmianach.
Nie każdy system potrzebuje jednak takiej konstrukcji, dlatego warto od razu ustawić granicę opłacalności.
Kiedy taki układ ma sens, a kiedy lepiej wybrać prostsze rozwiązanie
Najczęściej widzę, że ten styl wygrywa w aplikacjach z żywą domeną, wieloma integracjami i dłuższym cyklem życia. Jeśli biznes zmienia reguły częściej niż technologia, separacja warstw daje sporo spokoju. Jeśli natomiast budujesz prosty panel administracyjny, niewielki CRUD albo jednorazowy prototyp, pełny podział może być zwyczajnie za ciężki.
| Sytuacja | Lepszy wybór | Dlaczego |
|---|---|---|
| System złożonych reguł biznesowych | Warstwowy rdzeń z wyraźnymi granicami | Zmiany dotyczą logiki, nie tylko ekranów |
| Aplikacja z wieloma wejściami, np. API, CLI i batch | Warstwa use case jako wspólny punkt sterowania | Jedna logika obsługuje kilka kanałów wejścia |
| Prosty CRUD bez trudnych reguł | Lżejsza architektura warstwowa | Mniej kodu pomocniczego i mniej ceremonii |
| MVP, który może się szybko zmienić | Start prostszy, bez nadmiaru abstrakcji | Łatwiej refaktoryzować po potwierdzeniu kierunku |
Ja zwykle patrzę na trzy sygnały ostrzegawcze. Po pierwsze, jeśli każda zmiana biznesowa wymaga dotykania frameworka, coś jest źle. Po drugie, jeśli testy bez bazy są niemożliwe albo bolesne, domena została zbyt mocno wciągnięta w technikalia. Po trzecie, jeśli zespół poświęca więcej czasu na utrzymanie struktury niż na rozwijanie produktu, układ jest za ciężki względem potrzeb.
To nie oznacza, że prostszy model jest gorszy. Oznacza tylko, że warto dobrać narzędzie do skali problemu. Dla wielu projektów najlepsza decyzja to nie „wdrożyć wszystko”, tylko „wdrożyć tyle, ile naprawdę chroni rdzeń aplikacji”. Następny krok to unikanie błędów, które najczęściej psują cały efekt.
Najczęstsze błędy, które psują cały efekt
Najbardziej kosztowny błąd widzę wtedy, gdy encja domenowa zaczyna dziedziczyć po klasie ORM albo importować bibliotekę HTTP. To natychmiast rozrywa izolację rdzenia. Wtedy zamiast czystej separacji dostajesz jedynie ładnie nazwane foldery, które i tak zależą od zewnętrznych narzędzi.
- Wchodzenie frameworka do domeny - model biznesowy powinien być czystym Pythonem, a nie nośnikiem adnotacji technicznych.
- Kontroler, który robi wszystko - jeśli endpoint waliduje, liczy, zapisuje i wysyła maila, to logika ucieka na zewnątrz rdzenia.
-
Anemiczne use case’y - jeśli warstwa aplikacyjna tylko woła
repository.save(), to nie wnosi prawie nic. - Przesadne mnożenie interfejsów - abstrakcje mają chronić zmianę, a nie produkować kolejne pliki bez sensu.
- Mieszanie DTO z encjami - obiekty transportowe służą do komunikacji, a encje do reguł biznesowych.
- Udawanie architektury tam, gdzie jej nie potrzeba - jeśli projekt jest mały, nadmiar warstw tylko spowolni zespół.
W praktyce najłatwiej utrzymać dyscyplinę, gdy każda warstwa ma jednozdaniowy opis odpowiedzialności. Jeśli nie umiesz go ująć prosto, to zwykle znak, że granice zostały narysowane źle. W dobrze zaprojektowanym systemie odpowiedź na pytanie „gdzie to powinno leżeć?” nie wymaga długiej debaty.
Jest jeszcze jedna rzecz, którą często pomija się w rozmowach o tym podejściu: nie chodzi o perfekcję, tylko o zmniejszenie kosztu zmian. Tylko tyle i aż tyle. Dlatego w ostatniej sekcji zostawiam sobie krótką praktyczną mapę, którą warto mieć w głowie przed pierwszym wdrożeniem.
Co warto zapamiętać, zanim zastosujesz ten styl w swoim projekcie
Największa wartość tego podejścia nie leży w diagramie, tylko w tym, że chroni rdzeń przed chaosem technologicznym. Jeśli projekt ma realną logikę biznesową, kilka kanałów wejścia i perspektywę rozwoju, taka separacja zwykle zwraca się bardzo szybko. Jeśli jednak tworzysz prostą aplikację, zacznij lżej i rozbudowuj strukturę dopiero wtedy, gdy naprawdę pojawi się potrzeba.
Ja trzymałbym się jednej reguły praktycznej: najpierw model biznesowy, potem use case, na końcu technika. Kiedy kolejność jest odwrócona, kod zaczyna żyć wokół frameworka, a nie wokół problemu użytkownika. A to właśnie problem użytkownika powinien wyznaczać granice architektury.
Jeżeli chcesz korzystać z tego podejścia skutecznie, myśl mniej o nazwach katalogów, a bardziej o kierunku zależności, stabilności domeny i kosztach zmian. To trzy rzeczy, które realnie decydują o tym, czy ten styl pomoże, czy tylko dołoży warstwę formalności.