Rola typu big data scientist łączy programowanie, statystykę i rozumienie biznesu, ale w praktyce chodzi przede wszystkim o jedno: przełożenie dużych, chaotycznych zbiorów danych na decyzje, które można obronić liczbami. W tym artykule pokazuję, czym taki specjalista zajmuje się na co dzień, jakie podstawy programowania naprawdę są potrzebne i jak zacząć naukę bez błądzenia po omacku. Dorzucam też porównanie z pokrewnymi rolami i zestaw konkretnych umiejętności, które mają znaczenie w pracy z Pythonem.
Ta rola łączy analizę danych, kod i decyzje biznesowe
- Najpierw trzeba dobrze nazwać problem i ustalić, jakie dane w ogóle mają sens.
- Python i SQL są zwykle bazą, ale bez statystyki i czystego kodu daleko nie zajdziesz.
- Pandas, scikit-learn i Spark rozwiązują różne problemy skali, więc nie ucz się ich bez kontekstu.
- Najwięcej błędów wynika nie z modeli, lecz z jakości danych, złego celu i słabej komunikacji.
- Dobre portfolio pokazuje cały proces: od pobrania danych po wnioski i rekomendacje.
Czym naprawdę zajmuje się specjalista od dużych zbiorów danych
W codziennej pracy taki specjalista nie „mieli danych” dla samej analizy. Zaczyna od pytania, jaką decyzję trzeba podjąć i czy dane w ogóle pozwalają ją podjąć. Dopiero potem pojawiają się model, wizualizacja i raport.
W praktyce to połączenie kilku ról. Z jednej strony trzeba umieć pobrać i uporządkować dane, z drugiej zbudować sensowny model albo analizę, a na końcu wyjaśnić wynik osobie nietechnicznej. W wielu projektach liczy się nie tylko to, czy model działa, ale czy zespół potrafi na jego podstawie zrobić coś konkretnego: ograniczyć odpływ klientów, wykryć anomalię, przewidzieć popyt albo usprawnić proces.
Najkrócej powiedziałbym tak: to nie jest rola od „ładnych wykresów”, tylko od przekładania danych na przewagę operacyjną. Ta perspektywa prowadzi wprost do pytania, jakich umiejętności programistycznych trzeba się nauczyć, żeby faktycznie wejść na ten poziom.
Jakie podstawy programowania naprawdę są potrzebne
Tu najczęściej pojawia się nieporozumienie. Początkujący myślą, że muszą od razu znać zaawansowane algorytmy, a tymczasem dużo ważniejsze jest swobodne poruszanie się po podstawach: typach danych, pętlach, funkcjach, wyjątkach, plikach i pracy na strukturach takich jak listy, słowniki czy DataFrame, czyli tabelaryczne zbiory danych z wierszami i kolumnami.
Jeśli miałbym wskazać fundamenty, które realnie wracają w projektach, wyglądałyby tak:
- Python jako główny język do analizy, automatyzacji i prototypowania.
- SQL, czyli język do zadawania pytań bazom danych, bez którego trudno samodzielnie wydobywać informacje z hurtowni i systemów źródłowych.
- Praca z bibliotekami takimi jak pandas, NumPy, czyli biblioteka do obliczeń liczbowych, i scikit-learn.
- Czytelny kod, czyli funkcje, podział na moduły i sensowne nazwy zmiennych.
- Wersjonowanie w Git, czyli systemie kontroli wersji, bez którego współpraca zespołowa szybko robi się chaotyczna.
- Podstawy testowania, bo bez nich trudno zaufać własnym wynikom.
Warto myśleć o Pythonie nie jak o „nauce języka”, tylko jak o narzędziu do budowania powtarzalnych procesów. Oficjalna dokumentacja Pythona prowadzi od razu przez tutorial, bibliotekę standardową i instalację pakietów, bo właśnie te elementy są później codziennym zapleczem pracy. To ważne, bo w analizie danych nie wygrywa ten, kto pamięta składnię na pamięć, tylko ten, kto potrafi szybko złożyć sensowny proces przetwarzania.
| Umiejętność | Po co jest potrzebna | Typowy efekt w pracy |
|---|---|---|
| Python | Automatyzacja analizy, przygotowanie danych, prototypowanie modeli | Szybsze iteracje i mniej ręcznego klikania |
| SQL | Wydobywanie danych z hurtowni i baz operacyjnych | Lepszy dostęp do danych bez czekania na inne zespoły |
| pandas | Czyszczenie, łączenie i przekształcanie danych tabelarycznych | Porządek w danych, zanim trafią do modelu lub raportu |
| scikit-learn | Budowa i ocena modeli uczenia maszynowego | Szybki start z klasyfikacją, regresją i walidacją |
| Git | Kontrola zmian i współpraca z zespołem | Możliwość cofania błędów i pracy zespołowej |
Jeżeli opanujesz ten zestaw, łatwiej będzie ci zrozumieć, jak te narzędzia składają się na cały proces pracy z dużymi zbiorami danych.
Jak wygląda codzienna praca z danymi na dużą skalę
W praktyce większość projektów przechodzi przez podobny łańcuch: pozyskanie danych, zapis, przetwarzanie, czyszczenie i dopiero potem analiza. AWS opisuje to właśnie jako pięć kroków, a ja dodałbym jeszcze szósty, którego często brakuje początkującym: komunikację wyniku. Bez niej nawet dobry model zostaje w notatniku analitycznym.
Najczęstszy przebieg pracy wygląda mniej więcej tak:
- Weryfikuję źródła danych i sprawdzam, czy są kompletne, aktualne i zgodne z celem projektu.
- Porządkuję dane, usuwam braki, duplikaty i niespójności.
- Tworzę cechy albo agregaty, które lepiej opisują problem.
- Buduję analizę albo model i sprawdzam, czy wynik jest stabilny.
- Pokazuję rezultat w formie wykresu, tabeli, panelu lub krótkiej rekomendacji.
Tu właśnie wchodzi Spark i podobne narzędzia. Apache Spark jest projektowany do pracy rozproszonej i może działać z Pythonem, SQL, Scalią, Javą albo R, co ma znaczenie wtedy, gdy dane nie mieszczą się wygodnie na jednej maszynie. To nie jest jednak narzędzie „na wszelki wypadek”. W małych i średnich projektach pandas często wystarcza, a Spark staje się sensowny dopiero wtedy, gdy skala naprawdę zaczyna boleć.
Jeśli miałbym wskazać jedną praktyczną różnicę między juniorem a osobą bardziej doświadczoną, powiedziałbym tak: junior widzi głównie kod, a mocniejszy specjalista widzi cały przepływ danych od źródła do decyzji. I właśnie to odróżnia zwykłą analizę od pracy, która ma realny wpływ na firmę.
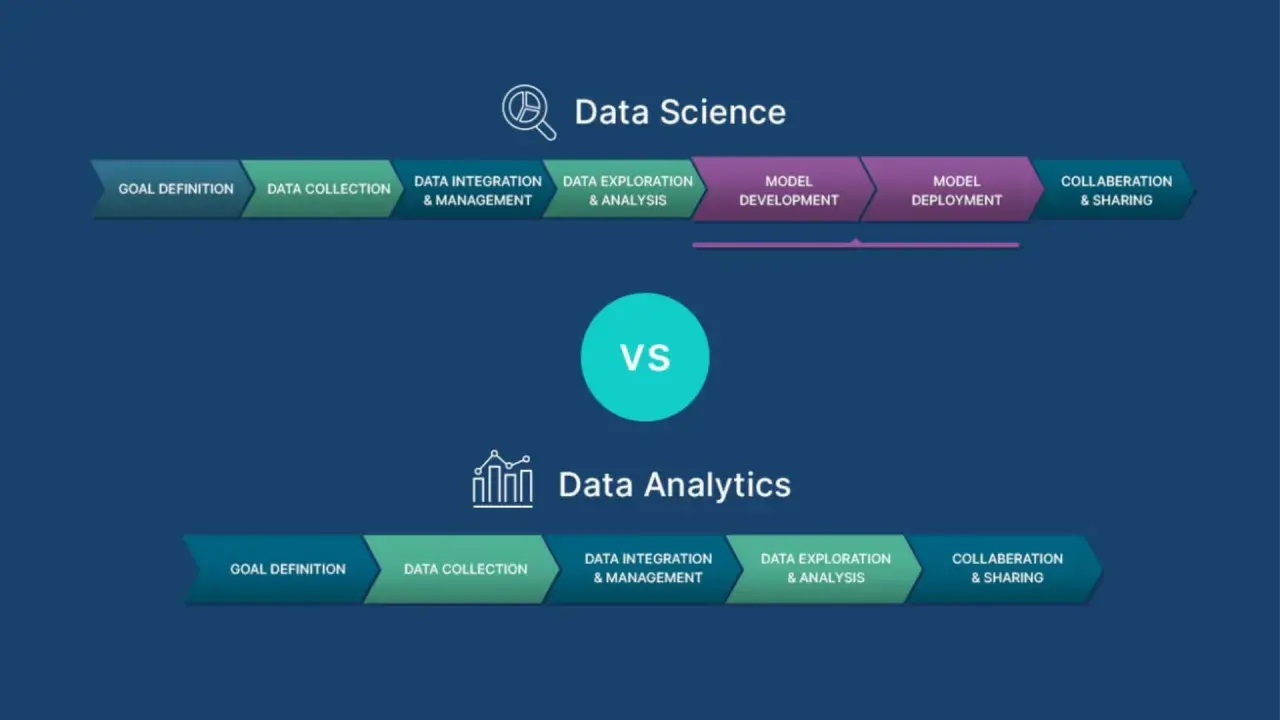
Czym ta rola różni się od analityka danych i data engineera
Te nazwy często są mieszane, a w ogłoszeniach bywa jeszcze większy chaos. Dlatego wolę porównywać je po zadaniu, a nie po tytule stanowiska. Wtedy różnice stają się dużo bardziej praktyczne. Na polskim rynku nazwy stanowisk bywają jeszcze bardziej rozciągnięte niż zakres obowiązków, więc warto czytać ogłoszenia po zadaniach, nie po tytule.
| Rola | Główny cel | Najczęstsze narzędzia | Co zwykle dostarcza |
|---|---|---|---|
| Analityk danych | Opisać, co się wydarzyło i dlaczego | SQL, Excel, BI, podstawowy Python | Raport, panel, wnioski biznesowe |
| Data engineer | Zbudować stabilny przepływ danych | SQL, Python, Airflow, Spark, chmura | Pipeline, hurtownia, warstwa zasilania danych |
| Specjalista od dużych zbiorów danych | Znaleźć wzorce, zbudować model i przełożyć wynik na decyzję | Python, SQL, pandas, scikit-learn, Spark | Analiza predykcyjna, prototyp modelu, rekomendacja |
Granice są oczywiście płynne. W mniejszej firmie jedna osoba może robić wszystko po trochu, a w dużej organizacji role są ostrzej rozdzielone. To ważne, bo nie ma jednego „właściwego” zakresu obowiązków. Jest za to jedno rozsądne pytanie: czy chcesz bardziej budować infrastrukturę, czy wyciągać z danych wnioski i przewidywania? Odpowiedź na nie pomaga dobrać ścieżkę nauki.
Skoro różnice są już jasne, zostaje najważniejsze pytanie: jak wejść w ten obszar bez rozbijania nauki na przypadkowe kawałki.
Jak wejść do zawodu krok po kroku
Najlepsza kolejność nauki jest zaskakująco mało efektowna, ale działa. Najpierw podstawy programowania, potem analiza danych, dopiero później modele i narzędzia do dużej skali. Odwrócenie tej kolejności zwykle kończy się frustracją.
- Opanuj Pythona na poziomie wygodnego pisania funkcji, pracy na plikach, listach, słownikach i wyjątkach.
- Dodaj SQL, bo bez pobierania i łączenia danych z bazy trudno mówić o samodzielności.
- Naucz się pandas i ćwicz na rzeczywistych zbiorach danych, nie tylko na prostych przykładach z kursu.
- Poznaj podstawy statystyki, zwłaszcza średnią, medianę, rozkłady, korelację, testowanie hipotez i overfitting, czyli nadmierne dopasowanie modelu do danych treningowych.
- Zrób pierwsze modele w scikit-learn, ale skup się na walidacji i interpretacji, nie na samym „trenowaniu”.
- Wejdź w Spark lub inny silnik rozproszony dopiero wtedy, gdy naprawdę rozumiesz, po co go używasz.
- Zbuduj portfolio z 2-3 projektów, które pokazują cały proces, a nie tylko ładne wykresy w notatnikach analitycznych.
Najlepsze projekty portfolio to takie, które przypominają prawdziwą pracę. Przykład: prognoza odejścia klientów dla sklepu internetowego, analiza anomalii w logach aplikacji albo model przewidujący zapotrzebowanie na produkt na podstawie historii sprzedaży. Każdy z tych projektów uczy czegoś innego, ale wszystkie pokazują tę samą rzecz: umiesz zamienić dane w działanie.
Jeśli dopiero zaczynasz, nie próbuj budować „kompletnej platformy AI”. Lepiej stworzyć jeden dopracowany projekt niż pięć niedokończonych notatników analitycznych. Rekruter albo lider techniczny zwykle i tak patrzy na to, czy potrafisz myśleć procesowo, czy tylko kopiować gotowe przykłady.
Na tym etapie naturalnie pojawiają się też pułapki, bo sama znajomość narzędzi nie wystarcza.
Najczęstsze błędy i ograniczenia, o których lepiej wiedzieć wcześniej
W tej roli najłatwiej przepalić czas nie na kodzie, tylko na złych założeniach. Najczęstszy błąd to zaczynanie od modelu, zanim wiadomo, czy problem biznesowy jest dobrze opisany i czy dane są wystarczająco dobre. Drugi to przekonanie, że bardziej złożony algorytm automatycznie da lepszy wynik. W praktyce często wygrywa prostsze rozwiązanie, ale dobrze przygotowane.| Błąd | Dlaczego szkodzi | Lepsze podejście |
|---|---|---|
| Skupienie na modelu bez czyszczenia danych | Model uczy się szumu, a nie wzorca | Najpierw jakość danych, potem model |
| Brak jasnego pytania biznesowego | Analiza nie prowadzi do decyzji | Ustal, co ma się zmienić po wynikach pracy |
| Praca w jednym notatniku analitycznym bez struktury | Trudno odtworzyć i rozwijać projekt | Dziel kod na moduły, testuj i wersjonuj |
| Ignorowanie komunikacji | Dobry wynik nie zostaje wykorzystany | Pokazuj wnioski prostym językiem i z kontekstem |
| Sięganie po Spark bez potrzeby | Technologia komplikuje projekt zamiast pomagać | Dobieraj narzędzie do skali i zadania |
Jest jeszcze jedno ograniczenie, o którym rzadko mówi się wprost: nie każda organizacja ma dojrzałe dane. Czasem największą częścią pracy jest nie modelowanie, tylko odzyskanie sensu z niepełnych, niespójnych albo rozproszonych źródeł. Właśnie dlatego cierpliwość, porządek i umiejętność priorytetyzacji są tu równie ważne jak znajomość algorytmów.
Gdy to rozumiesz, łatwiej ocenić, czy ta ścieżka naprawdę pasuje do twojego sposobu myślenia, czy tylko brzmi atrakcyjnie na papierze.
Co warto mieć w portfolio, żeby pokazać realną wartość
Jeśli budujesz profil pod taką rolę, portfolio powinno udowadniać trzy rzeczy: że umiesz pracować z danymi, że rozumiesz podstawy programowania i że potrafisz myśleć procesowo. Samo wrzucenie notatnika analitycznego z modelem klasyfikacyjnym zwykle nie wystarcza.
- Projekt end-to-end z opisem problemu, czyszczeniem danych, analizą i rekomendacją.
- Przykład pracy z SQL, który pokazuje, że potrafisz samodzielnie pobrać i przetworzyć dane.
- Choć jeden projekt z Pythonem, gdzie kod jest uporządkowany, a nie tylko „działa na moim komputerze”.
- Krótka notka interpretacyjna, w której wyjaśniasz, co wynik oznacza dla biznesu albo użytkownika.
W praktyce lepiej wypadają projekty mniejsze, ale dopracowane. Dobry przykład to analiza rotacji klientów w e-commerce, prosty model prognozy popytu albo system wykrywania nietypowych zdarzeń w logach. Takie case’y są użyteczne, bo pokazują, że potrafisz połączyć technikę z sensem biznesowym, a nie tylko popisywać się narzędziami.
Najprostszy test na start jest prosty: weź publiczny zbiór danych, napisz krótki skrypt w Pythonie, dodaj SQL albo plik CSV, zrób kilka wykresów i opisz wynik jednym akapitem po polsku. Jeśli ten proces bardziej cię porządkuje niż męczy, to sygnał, że ta ścieżka ma sens. Jeśli bardziej kręci cię sama infrastruktura, warto równolegle przyjrzeć się roli data engineera.