W praktyce to nie jest spór o to, które narzędzie jest „lepsze”, tylko o to, na jakim etapie życia aplikacji potrzebujesz pakowania kontenerów, a na jakim ich orkiestracji. Docker pomaga mi zbudować i uruchomić obraz, Kubernetes przejmuje zarządzanie wieloma instancjami, skalowaniem, restartami i wdrożeniami. Jeśli patrzysz na ten temat z perspektywy backendu albo DevOps, różnica ma bezpośredni wpływ na szybkość wdrożeń, stabilność i koszty utrzymania, więc warto rozumieć ją bez uproszczeń typu kubernetes vs docker.
Co warto zapamiętać o Dockerze i Kubernetesie
- Docker służy przede wszystkim do tworzenia i uruchamiania kontenerów, czyli spakowanych środowisk aplikacji.
- Kubernetes zajmuje się orkiestracją kontenerów: rozmieszcza je, skaluje, restartuje i aktualizuje.
- To nie są zamienniki 1:1. W typowym procesie backendowym Docker dostarcza obraz, a Kubernetes nim zarządza po wdrożeniu.
- Jeśli masz małą aplikację, jeden serwer i prosty release flow, Docker albo Docker Compose często wystarcza.
- Jeśli masz kilka usług, potrzebujesz wysokiej dostępności i automatycznego skalowania, Kubernetes zaczyna robić różnicę.
- Największy błąd to wdrażanie Kubernetesa „na zapas”, zanim faktycznie rośnie złożoność systemu.
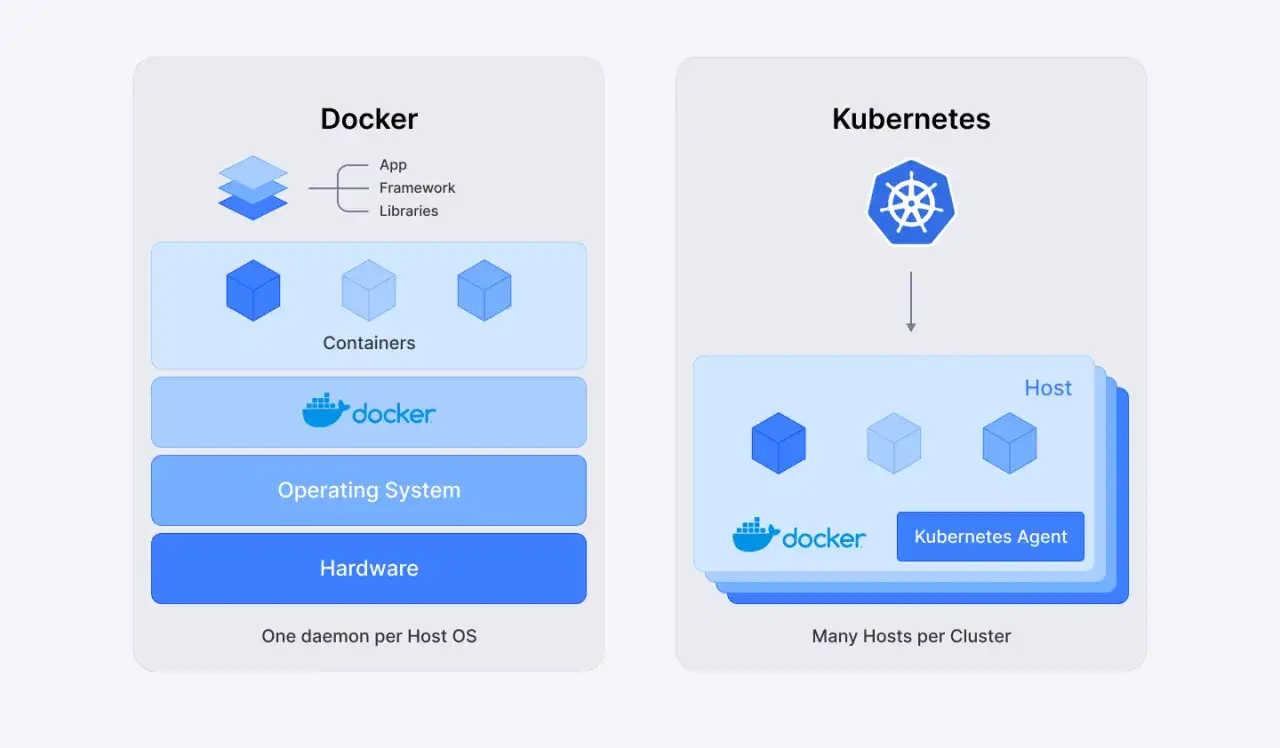
Na czym polega różnica między Dockerem a Kubernetesem
Ja zwykle zaczynam od rozdzielenia dwóch warstw. Docker odpowiada za konteneryzację, czyli przygotowanie aplikacji tak, żeby działała w przewidywalnym, odizolowanym środowisku. Kubernetes odpowiada za orkiestrację, czyli za to, co dzieje się, gdy takich kontenerów jest wiele i trzeba nimi sensownie zarządzać w czasie.
Według dokumentacji Kubernetes to platforma do zarządzania konteneryzowanymi workloadami i usługami, a w dokumentacji Dockera kontener to uruchamialna instancja obrazu. W praktyce oznacza to prostą rzecz: Docker pomaga mi przygotować „co uruchomić”, a Kubernetes decyduje „gdzie, ile razy i jak to utrzymać przy życiu”.
Warto dodać jeszcze jedną rzecz, bo często umyka w dyskusjach technicznych: dziś Kubernetes nie potrzebuje Dockera jako silnika uruchomieniowego pod spodem. Korzysta z runtime’ów zgodnych z CRI, ale nadal bez problemu pracuje z obrazami zbudowanymi w Dockerze. To właśnie dlatego te technologie się nie wykluczają.
To rozróżnienie jest ważne, bo wiele osób traktuje oba narzędzia jak konkurentów w jednej kategorii. To błąd. Kubernetes nie zastępuje Dockera w budowaniu obrazów, a Docker nie daje tego poziomu automatyzacji wdrożeń, autoskalowania i samonaprawy, który dostaję w K8s. I właśnie dlatego porównanie ma sens tylko wtedy, gdy mówimy o różnych etapach tego samego procesu.
Skoro to już uporządkowane, warto sprawdzić, kiedy sama konteneryzacja wystarcza i nie trzeba od razu dokładać całego klastra.
Kiedy sam Docker wystarczy w backendzie
W wielu projektach backendowych Docker jest po prostu wystarczający. Jeśli aplikacja działa na jednym serwerze, ma niewiele zależności i wdrożenie można opisać w kilku krokach, dokładanie Kubernetesa zwykle tylko podnosi koszt wejścia bez realnego zysku.
- Masz jedną aplikację albo kilka usług, ale uruchamiasz je na jednej maszynie.
- Chcesz mieć powtarzalne środowisko lokalne, staging i produkcję oparte na tych samych obrazach.
- Potrzebujesz szybkiego startu, a nie pełnej automatyzacji klastra.
- Zespół nie ma jeszcze dojrzałych procesów DevOps albo nie chce utrzymywać dodatkowej warstwy infrastruktury.
- W praktyce wystarcza Ci Docker Compose do uruchomienia API, bazy i kolejki w jednym środowisku.
W projektach Pythona to działa szczególnie dobrze. FastAPI, Django czy Flask można bez problemu opakować w obraz, a obok postawić PostgreSQL, Redis albo Celery w Compose. Taki układ bardzo pomaga w developmentcie, bo lokalne środowisko zaczyna przypominać produkcję, ale bez kosztu uczenia się całego ekosystemu Kubernetes.
Ja często widzę, że zespoły próbują przejść na K8s zanim opanują prosty, stabilny proces budowania i tagowania obrazów. To odwrotna kolejność. Najpierw warto mieć dobrze opisany Dockerfile, sensowny pipeline CI i jasny sposób wersjonowania obrazu. Dopiero potem ma sens rozbudowa orkiestracji.
Gdy aplikacja zaczyna rosnąć, pojawia się jednak moment, w którym sam Docker przestaje być wygodny. Wtedy wchodzi Kubernetes.
Gdzie Kubernetes zaczyna robić realną różnicę
Kubernetes staje się sensowny wtedy, gdy problemem nie jest już samo uruchomienie kontenera, tylko utrzymanie wielu instancji aplikacji w ruchu. To najczęściej oznacza mikroserwisy, większy ruch, potrzebę rozkładania obciążenia albo częste wdrożenia bez przerywania pracy systemu.
Najbardziej praktyczne sygnały, że K8s zaczyna się opłacać, wyglądają tak:
- Potrzebujesz kilku replik tej samej usługi, bo pojedynczy proces nie wystarcza albo nie jest odporny na awarie.
- Chcesz rolling update, czyli aktualizację bez zatrzymywania całej aplikacji naraz.
- Ważne jest autohealing, czyli automatyczne odtwarzanie padłych podów.
- Masz wiele usług, które muszą się odnajdywać w sieci, a ręczne adresowanie instancji przestaje działać.
- Chcesz ustawiać limity CPU i RAM oraz pilnować, żeby jedna usługa nie zjadała całego hosta.
- Potrzebujesz spójnego środowiska dla kilku zespołów albo kilku klas usług działających równolegle.
Warto też pamiętać o jednym szczególe, który często umyka początkującym: w Kubernetesie podstawową jednostką jest Pod, czyli grupa jednego lub większej liczby kontenerów współdzielących sieć i zasoby. To istotne, bo K8s nie zarządza „samym Dockerem”, tylko jednostkami pracy wyższego poziomu. W praktyce daje to większą elastyczność, ale też więcej konfiguracji.
Jeśli jednak cały zespół ma do ogarnięcia jedną aplikację i kilka zależności, Kubernetes może być po prostu zbyt ciężki. Dlatego poniżej zestawiam oba podejścia bez marketingu i bez uproszczeń.
Jak wypadają w bezpośrednim porównaniu
Wybór najlepiej widać w praktycznych kryteriach, a nie w hasłach. Ja patrzę przede wszystkim na to, ile kontroli daje narzędzie i ile kosztuje ta kontrola w utrzymaniu.
| Kryterium | Docker | Kubernetes | Co to znaczy w praktyce |
|---|---|---|---|
| Główna rola | Budowanie i uruchamianie kontenerów | Orkiestracja kontenerów | Docker rozwiązuje problem obrazu i uruchomienia, K8s problem pracy całego systemu |
| Jednostka pracy | Kontener | Pod i kontrolery | W K8s myślisz o replikach, politykach i stanie docelowym, nie o pojedynczym procesie |
| Skalowanie | Ręczne lub przez prostsze mechanizmy | Automatyczne, poziome i deklaratywne | Przy większym ruchu K8s szybciej nadąża za zmianą obciążenia |
| Wysoka dostępność | Ograniczona, zależy od własnego setupu | Wbudowana jako model działania | Jeśli padnie instancja, K8s może ją odtworzyć bez ręcznej interwencji |
| Wdrożenia | Proste, ale mniej elastyczne | Rolling update, rollback, strategie wdrożeń | Dużo łatwiej robić bezpieczne releasy w systemach produkcyjnych |
| Trudność wejścia | Niska do umiarkowanej | Wyraźnie wyższa | K8s wymaga czasu na naukę, a Docker daje szybki efekt |
| Koszt operacyjny | Niższy przy małych systemach | Wyższy, ale uzasadniony przy większej skali | Im bardziej złożony system, tym bardziej opłaca się ta dodatkowa warstwa |
To zestawienie dobrze pokazuje sedno: Docker upraszcza pracę z kontenerem, a Kubernetes upraszcza życie, gdy kontenerów robi się dużo. Nie ma tu zwycięzcy uniwersalnego. Jest tylko narzędzie adekwatne do skali problemu.
W praktyce obie technologie często działają razem, a nie przeciw sobie. I właśnie to jest następny krok, który warto zrozumieć przed wyborem stacku.
Jak Docker i Kubernetes współpracują w jednym pipeline
Najzdrowszy model, który widzę w zespołach backendowych, wygląda tak: Docker buduje obraz aplikacji, a Kubernetes wdraża ten obraz i zarządza jego cyklem życia. Dzięki temu jedno narzędzie nie próbuje robić wszystkiego naraz.
Typowy proces jest prosty:
- Tworzę Dockerfile, który opisuje środowisko uruchomieniowe aplikacji.
- W CI buduję obraz i oznaczam go wersją, na przykład numerem commita albo tagiem release.
- Obraz trafia do rejestru, z którego potem pobiera go środowisko docelowe.
- Kubernetes odczytuje manifesty albo chart Helm i uruchamia odpowiednią liczbę podów.
- Jeśli wdrożenie się nie uda, mogę zrobić rollback bez ręcznego grzebania na serwerze.
To podejście dobrze działa również w projektach Pythonowych. Mogę lokalnie testować usługę w Dockerze, a w produkcji uruchamiać ją na K8s bez przepisywania aplikacji. Zmienia się tylko warstwa deploymentu, nie sam kod. To właśnie dlatego obrazy powinny być możliwie niemutowalne — nową wersję aplikacji dostarczam nowym obrazem, a nie „doklejam” zmian do działającego kontenera.
Jeżeli ktoś używa Kubernetesa tylko do „odpalania kontenerów”, to zwykle przepłaca za złożoność. Jeśli ktoś używa samego Dockera w systemie, który już wymaga replik, autoskalowania i odporności na awarie, to zaczyna płacić ręcznie czasem ludzi. W obu przypadkach problem nie leży w narzędziu, tylko w dopasowaniu do etapu projektu.
Ta różnica najłatwiej wychodzi w błędach wdrożeniowych, więc warto nazwać je wprost.
Najczęstsze błędy przy wyborze narzędzia
Największy błąd to traktowanie Kubernetesa jak domyślnego kolejnego kroku po Dockerze. W praktyce to nie jest upgrade „po kolei”, tylko odpowiedź na inny poziom złożoności.
- Wdrażanie K8s zbyt wcześnie - mały system nagle dostaje manifesty, ingressy, config mapy i sekrety, zanim faktycznie tego potrzebuje.
- Mylenie warstw - Docker jest od obrazu i kontenera, Kubernetes od zarządzania ich życiem w klastrze.
- Brak porządnych obrazów - jeśli Dockerfile jest chaotyczny, Kubernetes tylko szybciej rozmnoży problem.
- Ignorowanie stanu aplikacji - bazy danych, kolejki i wolumeny trzeba projektować ostrożniej niż stateless API.
- Brak obserwowalności - bez logów, metryk i alertów nawet dobry klaster staje się czarną skrzynką.
- Próba „ręcznego Kubernetesa” - stawianie klastra i zarządzanie nim jak pojedynczym serwerem zazwyczaj kończy się frustracją.
Ja szczególnie uczulam na ostatni punkt. Kubernetes daje największy sens wtedy, gdy korzysta się z jego modelu deklaratywnego. Jeśli ktoś próbuje nim zarządzać jak zbiorem ręcznych poleceń, to narzut rośnie szybciej niż korzyści.
Na tym etapie naturalnie pojawia się najważniejsze pytanie praktyczne: co wybrać dla własnego backendu, żeby nie przesadzić ani w jedną, ani w drugą stronę?
Jak wybrać bez przepalania czasu zespołu na zbyt ciężki stack
Gdybym miał sprowadzić decyzję do prostego testu, zacząłbym od tego, ile realnie kosztuje utrzymanie aplikacji w obecnym kształcie. Jeśli masz jedną maszynę, kilka usług i wdrożenie, które da się opisać w 3-4 krokach, Docker i ewentualnie Compose są najrozsądniejszym wyborem. Jeśli w grę wchodzą 2-3 repliki, automatyczne odtwarzanie padłych instancji, rozdzielenie ruchu i bezpieczne rollouty, Kubernetes zaczyna bronić się sam.
Ja też patrzę na zespół. Jeśli nikt nie ma czasu utrzymywać klastra, pisać polityk, monitorować zasobów i ogarniać aktualizacji platformy, to „technicznie lepsze” rozwiązanie może w praktyce spowolnić cały produkt. Z drugiej strony, jeśli system rośnie i ręczne wdrożenia zaczynają zabierać po kilkadziesiąt minut oraz wymagają sprawdzania kilku serwerów naraz, koszt prostoty robi się zbyt wysoki.
Najbardziej rozsądna ścieżka zwykle wygląda tak: najpierw porządny Docker i stabilny pipeline CI/CD, potem Kubernetes tylko wtedy, gdy uzasadnia to skala albo wymagania operacyjne. To podejście jest mniej efektowne niż szybkie „wchodzę w K8s”, ale dużo częściej kończy się systemem, który da się utrzymać bez gaszenia pożarów.
Jeśli miałbym to ująć jednym zdaniem, to Docker pomaga zacząć dobrze, a Kubernetes pomaga rosnąć bez chaosu. W praktyce najlepszy wybór zależy nie od mody na narzędzia, tylko od tego, czy Twoim głównym problemem jest jeszcze kontener, czy już cały jego ekosystem.