CloudFront to warstwa, która potrafi wyraźnie przyspieszyć stronę, API i dystrybucję plików, ale jej największa wartość w backendzie i DevOps nie kończy się na samym obniżeniu opóźnień. Dobrze ustawiona CDN odciąża origin, porządkuje cache, upraszcza rollouty i daje sensowną warstwę ochrony przed ruchem i atakami. Poniżej pokazuję, kiedy to rozwiązanie naprawdę pomaga, jak je skonfigurować bez typowych pułapek i na co patrzeć w metrykach, żeby nie zgadywać, tylko mierzyć efekt.
Najważniejsze rzeczy, które warto wiedzieć o CloudFront przed wdrożeniem
- CloudFront działa najlepiej tam, gdzie można sensownie cache’ować odpowiedzi i ograniczyć liczbę żądań do originu.
- Sieć AWS obejmuje ponad 600 punktów obecności, 13 regional edge caches i działa w 100+ miastach w 50 krajach.
- Najczęstsze błędy to zbyt szerokie przekazywanie nagłówków, ciastek i parametrów query oraz brak wersjonowania plików statycznych.
- W S3 najbezpieczniej używać Origin Access Control, a nie publicznego bucketu.
- CloudFront Functions sprawdzą się przy lekkich zmianach na krawędzi, a Lambda@Edge wtedy, gdy potrzebujesz więcej logiki i dostępu do body.
- W monitoringu najczęściej patrzę na `CacheHitRate`, `5xxErrorRate`, `OriginLatency` i koszty invalidacji.
Co CloudFront daje w backendzie i DevOps
Ja traktuję CloudFront nie jak „dodatek do hostingu”, ale jak warstwę kontrolną przed aplikacją. W praktyce działa to jako globalna CDN, która serwuje treści z punktów brzegowych bliżej użytkownika, a gdy trzeba, sięga do originu, czyli źródła danych: S3, ALB, EC2, API Gateway albo własnego serwera HTTP. To ma sens nie tylko dla grafik i JS-a, ale też dla API, stron renderowanych po stronie serwera i treści dynamicznych, które mają przynajmniej częściowo przewidywalny wzorzec ruchu.- Statyczne zasoby - obrazy, CSS, JS, fonty, pliki do pobrania.
- Ruch API - gdy część odpowiedzi da się cache’ować albo przynajmniej odfiltrować na krawędzi.
- Treści multimedialne - wideo, miniatury, duże pliki, katalogi produktowe.
- Ochrona originu - mniej bezpośrednich żądań do backendu, łatwiejsze utrzymanie i mniejsze ryzyko przeciążenia.
Największa różnica pojawia się wtedy, gdy rozumiesz pojęcie cache hit ratio, czyli procent żądań obsłużonych bez sięgania do originu. Im wyższy ten współczynnik, tym mniejsze opóźnienie dla użytkownika i mniejsze obciążenie zaplecza. CloudFront jest do tego dobrze przygotowany: AWS mówi o ponad 600 POP-ach, 13 regional edge caches oraz obecności w 100+ miastach w 50 krajach. To już nie jest „jakiś CDN”, tylko realna warstwa infrastruktury, którą trzeba świadomie zaprojektować.
To prowadzi do kolejnego pytania: jak dokładnie przebiega żądanie i gdzie w tym procesie da się odzyskać najwięcej wydajności.
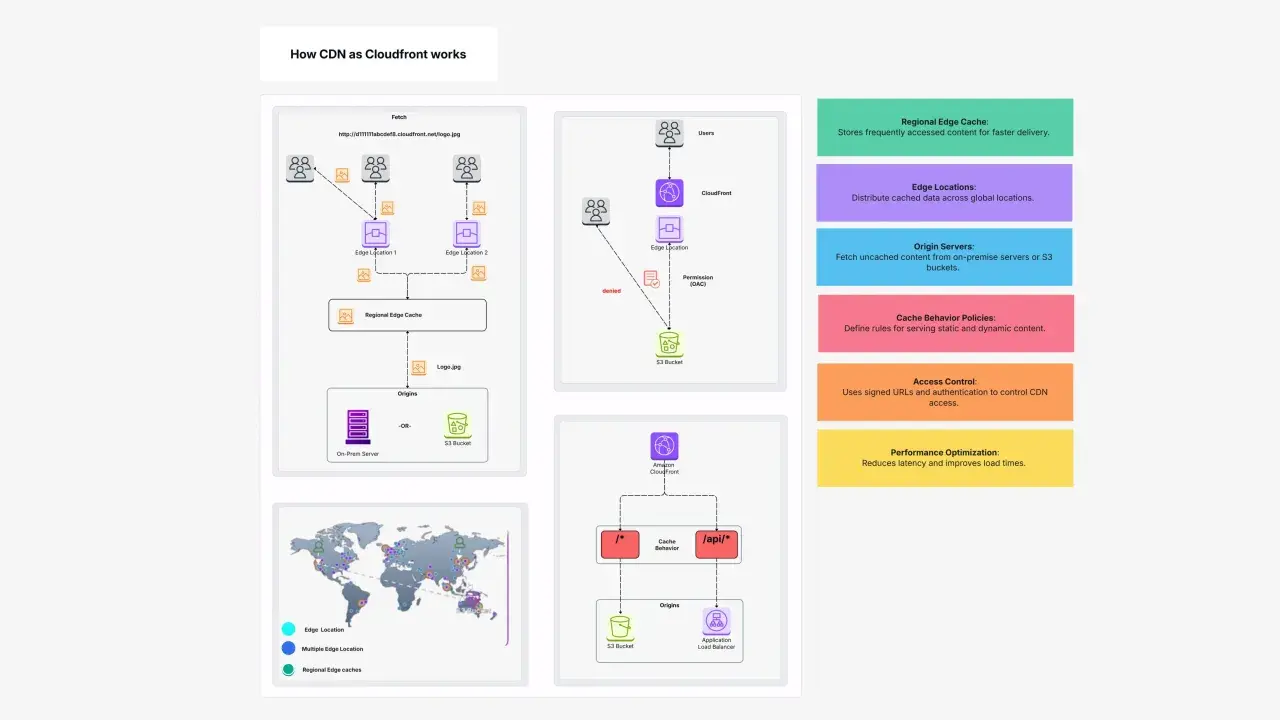
Jak działa przepływ ruchu od przeglądarki do originu
Mechanika CloudFront jest prosta, ale warto ją rozumieć, bo od tego zależy konfiguracja cache. Gdy użytkownik wysyła żądanie, DNS kieruje je do najbliższego punktu obecności w sensie opóźnienia. Edge location sprawdza cache, a jeśli obiekt jest dostępny, odsyła go od razu. Jeśli nie, CloudFront najpierw próbuje regional edge cache, a dopiero potem idzie do originu.
- Użytkownik otwiera stronę lub wywołuje zasób API.
- DNS kieruje ruch do najbliższego punktu brzegowego CloudFront.
- CloudFront sprawdza lokalny cache, a potem regional edge cache.
- Jeśli odpowiedzi nie ma, żądanie trafia do originu i wraca już zbuforowane na kolejne wywołania.
W praktyce ważne są tu dwa dodatkowe elementy. Po pierwsze, CloudFront może działać z wieloma originami i przełączać ruch na zapasowy, jeśli podstawowy przestaje odpowiadać. Po drugie, warstwa regional edge caches i Origin Shield pozwala ograniczyć liczbę bezpośrednich wejść do originu, co jest szczególnie przydatne przy pikach ruchu i przy treściach, które potrafią gwałtownie wracać do popularności. Dla backendu oznacza to mniej niepotrzebnych requestów, a dla DevOps mniej gaszenia pożarów na źródle danych.
Skoro wiadomo już, jak przepływa ruch, warto przejść do konfiguracji. To właśnie tam najłatwiej zepsuć albo poprawić cały efekt.
Jak skonfigurować dystrybucję bez typowych błędów
Największy błąd, który widzę, to ustawianie CloudFront „na szybko” i dokładanie wszystkiego do cache key „na wszelki wypadek”. To niemal zawsze kończy się słabym cache hit ratio. Ja zwykle zaczynam od prostego modelu: osobny behavior dla statycznych plików, osobny dla API i osobny dla ścieżki głównej aplikacji. Dopiero potem dokładam wyjątki.
| Ustawienie | Za co odpowiada | Moja domyślna decyzja |
|---|---|---|
| Origin | Skąd CloudFront pobiera treści | S3 z OAC, ALB albo custom HTTP origin |
| Cache policy | Co trafia do cache key | Minimum nagłówków, ciastek i query stringów |
| Origin request policy | Co CloudFront przekazuje do originu | Tylko to, czego origin naprawdę potrzebuje |
| Viewer protocol policy | HTTP vs HTTPS | Redirect HTTP do HTTPS |
| Behavior pattern | Które ścieżki idą do którego originu | Osobne reguły dla `/assets/*`, `/api/*` i `/` |
| Compression | Gzip/Brotli dla treści tekstowych | Włączone, jeśli nie ma przeciwwskazań po stronie originu |
Jeżeli korzystasz z S3, OAC jest dziś sensowniejszym wyborem niż publiczny bucket. Dzięki temu bucket nie musi być otwarty dla całego internetu, a CloudFront dostaje podpisane żądania do originu. To jest prostsze do utrzymania i bezpieczniejsze niż ratowanie prywatności samymi regułami w aplikacji.
Warto też pamiętać o mniej oczywistych limitach. CloudFront ma maksymalną długość żądania lub odpowiedzi z originu na poziomie 32 768 bajtów, a maksymalna długość URL to 8 192 bajty. Przy API z bardzo rozbudowanymi nagłówkami albo długimi parametrami query takie limity potrafią wyjść z cienia w najmniej wygodnym momencie.
Od tego miejsca naturalnie przechodzi się do cache. Bez niego CloudFront jest po prostu drogim pośrednikiem, a nie sensowną warstwą wydajności.
Cache, invalidacje i wersjonowanie zasobów
Tu zwykle robi się największa różnica między poprawnym wdrożeniem a takim, które tylko „jest włączone”. Ja najpierw decyduję, co ma być cache’owane długo, co krótko, a co w ogóle nie powinno trafiać do cache. Dopiero później myślę o invalidacjach. To ważne, bo invalidacja jest narzędziem operacyjnym, a nie substytutem dobrego versioningu.
- Pliki JS/CSS - najlepiej wersjonować nazwą pliku, zamiast polegać na częstych invalidacjach.
- HTML i entry point aplikacji - zwykle krótszy TTL, bo to one sterują resztą frontendu.
- Obrazy i assety produktowe - długi TTL, jeśli wersjonowanie jest stabilne.
- Rzeczy często zmieniane - krótszy TTL albo invalidacja po zmianie.
Przy invalidacjach liczy się kilka praktycznych faktów. Pierwsze 1 000 ścieżek invalidacji w miesiącu jest darmowe, a każda kolejna ścieżka jest już płatna. Jedna ścieżka z wildcardem, na przykład `/*` albo `/images/*`, liczy się jako pojedyncza pozycja, nawet jeśli unieważnia tysiące plików. To oznacza, że broad-brush invalidation jest wygodna, ale kosztowo i operacyjnie nie zawsze rozsądna.
Od niedawna CloudFront obsługuje też invalidację po cache tagach. To przydatne wtedy, gdy wiele powiązanych obiektów nie ma wspólnego prefiksu URL, ale logicznie należy do jednej grupy, na przykład do konkretnego produktu, kategorii albo kampanii. Ja traktuję to jako bardzo praktyczne ułatwienie dla zespołów, które mają rozproszoną strukturę treści i nie chcą budować sztucznej mapy ścieżek tylko po to, żeby wymusić odświeżenie.
Z tego wynika prosty wniosek: versioning dla assetów, rozsądny TTL dla HTML i invalidacje tylko tam, gdzie naprawdę trzeba natychmiast wymusić świeżą wersję. Następny krok to bezpieczeństwo, bo CDN bez ochrony originu daje tylko połowę wartości.
Bezpieczeństwo, które warto włączyć od razu
CloudFront dobrze pasuje do aplikacji, które mają stanąć jako „front door” przed resztą infrastruktury. W praktyce oznacza to, że użytkownik łączy się z CDN, a nie bezpośrednio z originem. To od razu zmniejsza powierzchnię ataku i ułatwia stosowanie spójnych reguł. Ja w takim układzie od pierwszego dnia włączam HTTPS, pilnuję ochrony originu i myślę o tym, czy treść ma być publiczna, czy kontrolowana podpisem.
- Wymuszaj HTTPS - redirect HTTP do HTTPS powinien być standardem, nie opcją.
- Używaj certyfikatu ACM - to najprostsza ścieżka dla własnej domeny.
- Chroń S3 przez OAC - bucket nie powinien być publiczny tylko dlatego, że stoi za CDN.
- Włącz signed URLs lub signed cookies - jeśli treści mają być dostępne tylko dla wybranych użytkowników.
- Dodaj AWS WAF - jeśli wystawiasz publiczny сайт lub API i potrzebujesz reguł aplikacyjnych.
Warto też pamiętać, że CloudFront współpracuje z AWS Shield Standard bez dodatkowej opłaty, co daje podstawową ochronę przed atakami DDoS. To nie zastępuje porządnej architektury, ale w praktyce jest rozsądnym pierwszym buforem. Ja szczególnie lubię ten model przy publicznych API i aplikacjach, które mają duży rozrzut geograficzny oraz wyraźne skoki ruchu.
Bezpieczeństwo na krawędzi to jednak nie to samo co odporność całej usługi. Jeśli origin padnie, CDN nie zrobi magii. Dlatego kolejny temat to awaryjność.
Jak zbudować awaryjność i nie ufać pojedynczemu originowi
CloudFront obsługuje wiele originów i ma natywny mechanizm origin failover, więc można automatycznie przełączyć ruch na zapasowy backend, gdy podstawowy przestanie spełniać warunki odpowiedzi. W AWS można łączyć w ten sposób zasoby takie jak S3, EC2, Media Services albo własne serwery HTTP. To bardzo użyteczne, ale tylko wtedy, gdy architektura po stronie originów jest świadomie zaprojektowana.
Najbardziej praktyczne wzorce, z którymi pracuję, wyglądają tak:
- S3 jako primary i S3 jako backup - dobre dla statycznych zasobów i prostych stron.
- ALB jako primary i alternatywny origin - sensowne dla aplikacji backendowych, które muszą przeżyć awarię regionu lub klastra.
- CloudFront przed API wieloregionowym - przydatne, gdy chcesz połączyć edge delivery z routingiem do najlepszego regionu.
- Tryb maintenance fallback - prosty sposób na kontrolowaną degradację zamiast twardego błędu dla użytkownika.
Jest jednak ograniczenie, które łatwo zignorować: failover CDN nie zastępuje replikacji danych ani logiki spójności. Jeśli aplikacja zapisuje stan, musisz wiedzieć, co dzieje się z write path, jak synchronizują się bazy i czy drugi origin naprawdę potrafi przejąć ruch bez utraty danych albo spójności sesji. CloudFront może przełączyć ruch bardzo szybko, ale nie naprawi problemów, które dzieją się głębiej w systemie.
To prowadzi do ostatniej praktycznej decyzji: gdzie kończy się prosta konfiguracja CDN, a zaczyna edge compute, czyli funkcje na krawędzi.
Kiedy wybrać CloudFront Functions, a kiedy Lambda@Edge
Jeśli ktoś pyta mnie, od czego zacząć, zwykle odpowiadam: od najprostszego narzędzia, które rozwiązuje problem. CloudFront Functions nadają się do lekkich operacji na żądaniach i odpowiedziach, a Lambda@Edge wtedy, gdy potrzebujesz więcej logiki, dostępu do body albo bardziej złożonej pracy na originie. Różnica nie jest kosmetyczna. Ona naprawdę wpływa na latencję, koszty i utrzymanie.
| Aspekt | CloudFront Functions | Lambda@Edge |
|---|---|---|
| Typ zadań | Redirecty, przepisywanie URL, proste reguły, lekkie auth | Rozbudowana logika, modyfikacja treści, analiza body, decyzje originowe |
| Startup i wydajność | Submilisekundowe uruchamianie, lekkie wykonanie | Cięższy model wykonania, większy narzut operacyjny |
| Język i runtime | JavaScript runtime dla CloudFront Functions | Najnowsze wspierane runtime Node.js i Python w Lambda@Edge |
| Dostęp do body | Brak dostępu do body HTTP | Dostęp możliwy, ale z limitami 40 KB dla viewer request i 1 MB dla origin request |
| Ograniczenia | Brak network calls, brak `fs`, `process`, `env`, logi do 10 KB | Trzeba używać wersjonowanej funkcji, a nie `$LATEST` czy aliasu |
| Najlepszy wybór | Gdy chcesz prosto i szybko zmodyfikować ruch na krawędzi | Gdy potrzebujesz głębszej logiki i większej elastyczności |
Ja w praktyce wybieram CloudFront Functions do prostych redirectów, normalizacji hosta, drobnych reguł A/B i prostego przestawiania nagłówków. Lambda@Edge zostawiam na sytuacje, w których trzeba zajrzeć głębiej w request, przetworzyć body albo wykonać bardziej złożoną logikę po stronie originu. Ten podział oszczędza czas, bo nie przepalam mocy obliczeniowej na problem, który da się rozwiązać prostszym mechanizmem.
To już prowadzi do ostatniego elementu: kosztów i monitoringu. W DevOps to często właśnie metryki pokazują, czy architektura działa, czy tylko wygląda dobrze na diagramie.
Koszty, monitoring i sygnały ostrzegawcze
CloudFront nie jest „darmowy po wdrożeniu”, tylko przewidywalny, jeśli rozumiesz, co generuje koszt. Najważniejsze składniki to transfer danych, liczba requestów, ewentualne opłaty za Origin Shield, invalidacje ponad darmowy limit, dodatkowe metryki oraz real-time logs. Standardowe logi CloudFront są darmowe, a metryki domyślne publikowane do CloudWatch nie wchodzą w dodatkową opłatę CloudWatch, ale część rozszerzonych metryk już tak.
| Metrika | Co mówi | Co zwykle poprawiam |
|---|---|---|
CacheHitRate |
Jaki procent ruchu idzie z cache | TTL, cache policy, nagłówki, cookies, query strings |
5xxErrorRate |
Jak często origin lub edge zwraca błąd serwera | Failover, timeouty, zdrowie originu, reguły WAF |
OriginLatency |
Ile trwa pierwszy bajt z originu | Lepszy cache, Origin Shield, szybszy backend |
BytesDownloaded |
Ile danych pobierają użytkownicy | Kompresja, lżejsze assety, optymalizacja frontendu |
BytesUploaded |
Ruch wysyłany do CloudFront metodami POST, PUT, OPTIONS | Ograniczenie niepotrzebnych uploadów i ciężkich requestów |
Do planowania ruchu przydają się też twarde limity domyślne: 150 Gbps transferu na dystrybucję i 250 000 requestów na sekundę na dystrybucję. To nie są wartości, do których większość zespołów dojdzie od razu, ale dobrze wiedzieć, gdzie przebiega domyślna granica. W praktyce patrzę na nie zwłaszcza wtedy, gdy aplikacja zaczyna rosnąć szybciej niż przewidywał zespół produktowy.
Jeśli metryki pokazują niski hit ratio, nie szukam od razu „problemu w CloudFront”. Najczęściej problem siedzi w zbyt szerokim przekazywaniu nagłówków, ciastek albo parametrów query. Jeśli rośnie `5xxErrorRate`, sprawdzam origin, timeouty, reguły failover i to, czy przypadkiem nie ma konfliktu między cache’owaniem a zachowaniem API. To są właśnie sygnały, które odróżniają dobrze zarządzaną dystrybucję od tej, która tylko działa.
Co wdrożyć najpierw, żeby zobaczyć realny efekt
- Postaw CloudFront przed statycznymi plikami i sprawdź, jaki masz realny `CacheHitRate` po 24-48 godzinach.
- Jeśli originem jest S3, przejdź na OAC i usuń publiczny dostęp do bucketa.
- Podziel ruch na osobne behaviors dla `/assets/*`, `/api/*` i ścieżki głównej aplikacji.
- Ogranicz headers, cookies i query strings do tego, co naprawdę zmienia odpowiedź.
- Włącz alarmy na `5xxErrorRate` i `OriginLatency`, a przy większym ruchu przetestuj Origin Shield oraz failover.
Jeżeli chcesz zobaczyć największy zwrot z pracy w możliwie krótkim czasie, zacząłbym od wariantu S3 + CloudFront albo ALB + CloudFront, bo właśnie tam najszybciej widać różnicę między dobrze ustawionym cache a konfiguracją, która tylko udaje optymalizację. W praktyce to nie sam CDN robi robotę, tylko to, czy umiesz go wpiąć w architekturę tak, by przyspieszał, chronił i upraszczał utrzymanie jednocześnie.