Instrukcja CASE pozwala wprowadzić logikę warunkową bezpośrednio do zapytania SQL: dzięki niej można nadawać etykiety, porządkować wyniki, liczyć dane tylko dla wybranych rekordów i upraszczać raporty. To jedno z tych narzędzi, które szybko podnoszą jakość pracy z bazą, ale tylko wtedy, gdy używa się go świadomie. Poniżej pokazuję, jak działa CASE, gdzie sprawdza się najlepiej i jakie błędy najczęściej psują rezultat.
Najważniejsze rzeczy, które warto wiedzieć o CASE w SQL
- CASE zwraca jedną wartość na podstawie pierwszego spełnionego warunku.
- Istnieją dwa główne warianty: prosty i wyszukujący, a każdy służy trochę innemu zadaniu.
- Najczęściej używa się go w
SELECT,ORDER BY,HAVINGi przy agregacjach warunkowych. - Brak
ELSEzwykle kończy się wynikiemNULL, więc trzeba to kontrolować. - Jeśli reguł robi się dużo, lepsza może być tabela słownikowa albo CTE zamiast rozbudowanego CASE.
Jak działa CASE krok po kroku
W dokumentacji PostgreSQL i Microsoft Learn CASE jest opisany jako wyrażenie, które można wstawić tam, gdzie SQL oczekuje pojedynczej wartości. W praktyce oznacza to prostą zasadę: silnik sprawdza warunki od góry do dołu, a zwraca wynik pierwszego dopasowania. Jeśli żaden warunek nie pasuje, działa gałąź ELSE, a gdy jej nie ma, wynik zwykle kończy się jako NULL.
Najwygodniej myśleć o tym jak o kontrolowanym if / else if / else, ale z jedną ważną różnicą: CASE nie steruje przebiegiem programu, tylko buduje wartość w ramach zapytania. Dzięki temu możesz go użyć nie tylko do opisu danych, ale też do ich grupowania, sortowania i przeliczania. To właśnie dlatego CASE tak często pojawia się w raportach, analizach biznesowych i zapytaniach, które muszą łączyć techniczne dane z logiką po stronie biznesu.
Typowy zapis wygląda tak:
CASE
WHEN warunek_1 THEN wynik_1
WHEN warunek_2 THEN wynik_2
ELSE wynik_domyslny
ENDWarto zapamiętać prostą regułę: kolejność ma znaczenie. Jeśli dwa warunki mogą być spełnione jednocześnie, wygra ten, który stoi wyżej. To daje dużą kontrolę, ale wymaga dyscypliny przy pisaniu logiki. Gdy to rozumiesz, dużo łatwiej odróżnić sam mechanizm od jego składni.
Dwa podstawowe warianty składni
CASE występuje w dwóch praktycznych odmianach. W wersji prostej porównujesz jedną wartość z kilkoma możliwymi opcjami. W wersji wyszukującej sprawdzasz dowolne warunki logiczne, więc możesz budować bardziej złożone reguły. W pracy z danymi częściej używam właśnie tej drugiej, bo jest elastyczniejsza, ale pierwsza bywa czytelniejsza, gdy mapowanie jest proste i stałe.
| Wariant | Jak wygląda | Kiedy używać | Na co uważać |
|---|---|---|---|
| Prosty CASE | CASE status WHEN 'paid' THEN ... |
Gdy porównujesz jedną kolumnę z kilkoma konkretnymi wartościami | Mniej wygodny przy złożonych warunkach i zakresach |
| CASE wyszukujący | CASE WHEN amount > 100 THEN ... |
Gdy potrzebujesz progów, zakresów, kilku warunków naraz lub zagnieżdżeń | Łatwo go przeładować, jeśli reguł robi się zbyt dużo |
Przykład prosty jest dobry do mapowania statusów:
CASE status
WHEN 'paid' THEN 'opłacone'
WHEN 'pending' THEN 'oczekuje'
WHEN 'canceled' THEN 'anulowane'
ELSE 'inne'
ENDWersja wyszukująca lepiej radzi sobie z progami i zakresami:
CASE
WHEN total_amount >= 1000 THEN 'vip'
WHEN total_amount >= 500 THEN 'regular'
ELSE 'small'
ENDW MySQL trzeba jeszcze pamiętać o rozróżnieniu między CASE używanym w zapytaniach a CASE statement w procedurach składowanych. To podobna nazwa, ale inny kontekst, więc przy większych projektach łatwo pomylić mechanizmy. Kiedy odróżniasz te dwa warianty, składnia przestaje być przeszkodą, a zaczyna być po prostu narzędziem do modelowania wyniku.
Przykłady, które naprawdę przydają się w raportach
Najczęściej korzystam z CASE wtedy, gdy chcę w jednym zapytaniu nadać danym sens biznesowy bez rozbijania logiki na dodatkowe kroki. To szczególnie praktyczne w analizie sprzedaży, finansów i danych operacyjnych, gdzie surowe wartości trzeba szybko zamienić na czytelne kategorie.
Oznaczanie rekordów etykietami
Klasyczny przykład to przypisywanie segmentów klientom lub zamówieniom. Zamiast wysyłać do aplikacji liczby, od razu zwracasz gotową etykietę:
SELECT
order_id,
total_amount,
CASE
WHEN total_amount >= 1000 THEN 'vip'
WHEN total_amount >= 500 THEN 'regular'
ELSE 'small'
END AS segment
FROM orders;To działa dobrze, bo raport od razu pokazuje biznesowy sens danych, bez dodatkowego przetwarzania po stronie frontendu albo Pythona.
Sortowanie według własnych reguł
CASE przydaje się też wtedy, gdy naturalna kolejność tekstów nie jest tą, której potrzebujesz. Jeśli priorytet ma pierwszeństwo przed datą, możesz wymusić własny porządek:
SELECT
ticket_id,
priority,
created_at
FROM tickets
ORDER BY
CASE priority
WHEN 'high' THEN 1
WHEN 'medium' THEN 2
ELSE 3
END,
created_at DESC;To ważne, bo domyślne sortowanie alfabetyczne często jest technicznie poprawne, ale biznesowo bezużyteczne.
Liczenie tylko wybranych rekordów
Jednym z najmocniejszych zastosowań CASE jest agregacja warunkowa. Zamiast robić kilka osobnych zapytań, można policzyć wybrane grupy w jednym przebiegu:
SELECT
COUNT(*) AS total_orders,
SUM(CASE WHEN status = 'paid' THEN 1 ELSE 0 END) AS paid_orders,
SUM(CASE WHEN status = 'pending' THEN 1 ELSE 0 END) AS pending_orders
FROM orders;To podejście jest czytelne i przenośne między silnikami. W praktyce oszczędza czas, bo nie musisz dublować logiki w kilku miejscach, a wynik da się łatwo wykorzystać w dashboardzie lub raporcie finansowym.
Przeczytaj również: Normalizacja baz danych - Porządek, który oszczędza czas
Zmiana wartości przy aktualizacji
CASE bywa też używany w UPDATE, gdy trzeba zmienić dane zależnie od warunku:
UPDATE customers
SET discount = CASE
WHEN lifetime_value >= 5000 THEN 0.15
WHEN lifetime_value >= 2000 THEN 0.10
ELSE 0.05
END;To wygodne przy jednorazowych korektach, ale przy długofalowych regułach lepiej zastanowić się, czy sama kolumna nie powinna wynikać z osobnej tabeli reguł. Takie przykłady pokazują, że CASE nie jest ozdobą składni, tylko narzędziem do modelowania wyniku.
Gdzie działa najlepiej i kiedy może zaszkodzić
CASE da się wykorzystać w wielu miejscach zapytania, ale nie każde użycie jest równie dobre. Najlepiej sprawdza się tam, gdzie potrzebujesz obliczyć wartość końcową, a nie tam, gdzie próbujesz za jego pomocą obejść strukturę danych. Gdy zaczyna zastępować model danych, zwykle robi się cięższy, mniej czytelny i trudniejszy do utrzymania.
| Miejsce użycia | Po co się sprawdza | Praktyczna uwaga |
|---|---|---|
SELECT |
Tworzenie etykiet, progów, opisów, klas danych | Najbardziej naturalne i najczytelniejsze zastosowanie |
ORDER BY |
Własna kolejność sortowania | Świetne przy priorytetach i rankingach biznesowych |
HAVING |
Filtrowanie wyników po agregacji | Dobre przy analizach sum, średnich i liczników warunkowych |
UPDATE ... SET |
Zmiana wartości zależnie od reguły | Przy większej liczbie reguł rośnie ryzyko błędu |
WHERE |
Warunkowe filtrowanie rekordów | Może pogorszyć użycie indeksów, jeśli owiniesz CASE wokół kolumny |
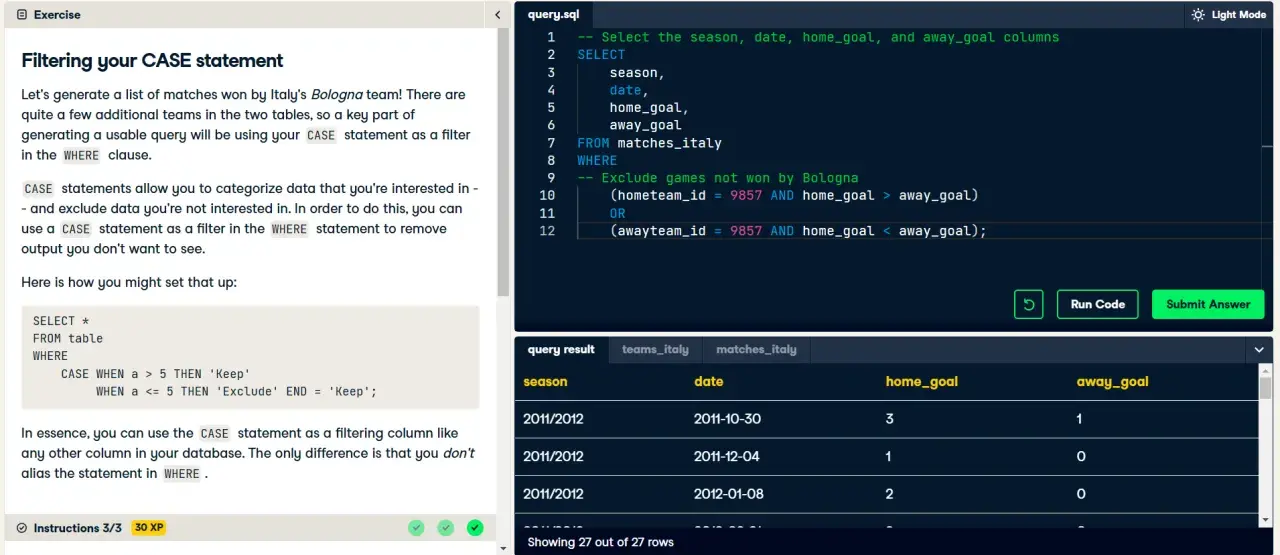
Najbardziej ostrożny byłbym właśnie przy WHERE. Jeśli zbudujesz warunek tak, że CASE obejmuje kolumnę filtrowaną, optimizer może mieć trudniej z wykorzystaniem indeksu. Nie znaczy to, że CASE w filtrze jest zły z definicji, ale warto najpierw sprawdzić, czy prostszy zapis z AND, OR albo osobnym CTE nie da lepszego planu wykonania. W praktyce drobna zmiana składni potrafi mieć większy wpływ niż rozbudowana optymalizacja na papierze.
Warto też pamiętać, że CASE nie zawsze jest idealnym zabezpieczeniem przed drogimi obliczeniami. Jeśli wewnątrz gałęzi umieścisz złożone wyrażenia, funkcje agregujące albo operacje zależne od planu wykonania, nie zakładaj automatycznie, że wszystko zostanie policzone dokładnie tak, jak sobie wyobrażasz. To kolejny powód, żeby nie używać CASE jako obejścia dla źle zaprojektowanego zapytania.
Gdy widzisz, że CASE zaczyna pojawiać się w połowie zapytania, to zwykle sygnał, że logika jest już na granicy wygody. I właśnie wtedy najłatwiej zrobić błąd, choć składnia nadal wygląda poprawnie.
Najczęstsze błędy, które psują logikę zapytań
Większość problemów z CASE nie wynika ze składni, tylko z kolejności warunków i zbyt dużego zaufania do domyślnego zachowania silnika. To drobiazgi, ale ich skutki potrafią być bardzo konkretne: zły segment klienta, błędna suma, mylący ranking albo puste wartości w raporcie.
-
Brak gałęzi ELSE - jeśli żaden warunek nie pasuje, dostaniesz
NULLi często nie zauważysz tego od razu. - Zła kolejność warunków - warunek bardziej ogólny może „zabrać” rekordy, które miały trafić do dokładniejszej gałęzi.
- Mieszanie typów - gałęzie CASE powinny zwracać wartości, które da się sensownie połączyć w jeden typ wyniku.
- Zbyt głębokie zagnieżdżenia - kilka poziomów CASE w CASE szybko obniża czytelność i utrudnia testowanie.
- Używanie CASE tam, gdzie lepsza byłaby tabela - jeśli reguły biznesowe zmieniają się często, słownik lub tabela mapująca jest zwykle rozsądniejsza.
-
Ignorowanie NULL-i - porównania z
NULLnie działają jak zwykłe=, więc trzeba to uwzględnić w warunkach.
Przykład błędu z kolejnością warunków jest banalny, ale bardzo częsty:
CASE
WHEN score >= 50 THEN 'pass'
WHEN score >= 80 THEN 'excellent'
ELSE 'fail'
ENDW tym układzie wynik excellent nigdy nie zostanie zwrócony, bo każda wartość 80+ spełnia też warunek 50+. Poprawny zapis musi zaczynać się od bardziej restrykcyjnej gałęzi:
CASE
WHEN score >= 80 THEN 'excellent'
WHEN score >= 50 THEN 'pass'
ELSE 'fail'
ENDTo mała zmiana, ale w raportach robi ogromną różnicę. Kiedy pilnujesz takich detali, CASE przestaje być źródłem przypadkowych błędów i zaczyna działać przewidywalnie.
Jak pisać czytelny CASE w większych projektach
W prostych zapytaniach CASE może mieć kilka linii i nadal pozostaje zrozumiały. Problem zaczyna się wtedy, gdy reguł przybywa, a zapytanie ma żyć miesiącami. Wtedy stawiam na przejrzystość, bo to ona decyduje, czy ktoś za trzy miesiące zrozumie, co miało zostać policzone.
- Układaj warunki od najbardziej specyficznych do najbardziej ogólnych.
- Trzymaj gałęzie krótkie i konsekwentnie wcięte.
- Nadaj wynikowi sensowny alias, żeby raport nie wymagał zgadywania.
- Jeśli ten sam CASE powtarza się w kilku miejscach, rozważ CTE, widok albo tabelę mapującą.
- Gdy reguł jest dużo i zmieniają się często, odpuść walkę z długą składnią - model danych powinien to uprościć, a nie komplikować.
Najbardziej praktyczna zasada, jaką stosuję, brzmi tak: jeśli potrzebujesz więcej niż kilku warunków i zaczynasz dopisywać wyjątki, zatrzymaj się i sprawdź, czy to nadal jest logika zapytania, czy już miniaplikacja ukryta w SQL. W tym drugim przypadku CASE zwykle nie jest najlepszym miejscem na całą odpowiedzialność. To właśnie w większych projektach różnica między sprytnym skrótem a technicznym długiem staje się naprawdę widoczna.
Kiedy CASE wystarczy, a kiedy lepiej sięgnąć po inną konstrukcję
CASE jest świetny do lokalnej logiki: klasyfikacji, etykietowania, prostych progów, własnego sortowania i warunkowych agregacji. Jeśli potrzebujesz jednorazowo opisać dane albo przygotować raport, zazwyczaj wystarczy i robi robotę bardzo dobrze. Gdy jednak reguły biznesowe stają się wspólne dla wielu zapytań, zaczynają częściej się zmieniać albo muszą być utrzymywane przez więcej niż jedną osobę, lepiej przenieść je do osobnej warstwy.
Najczęściej wybieram wtedy tabelę słownikową, widok albo CTE, bo te rozwiązania są łatwiejsze do testowania i mniej podatne na przypadkowe rozjazdy. CASE nadal może tam pozostać jako element pomocniczy, ale nie powinien być jedynym miejscem, w którym ukrywasz całą logikę systemu. Taki podział daje więcej kontroli i zwykle lepiej skaluje się wraz z projektem.
Jeśli zapamiętasz jedną rzecz, niech będzie prosta: CASE najlepiej działa jako narzędzie do dopracowania wyniku, a nie zastępstwo dla całego modelu danych. Właśnie wtedy jest najczytelniejszy, najbardziej praktyczny i najłatwiejszy do utrzymania w kolejnych iteracjach pracy nad bazą.