
Kontrola dostępu do danych na poziomie pojedynczych rekordów to jeden z tych mechanizmów, które realnie porządkują bezpieczeństwo w bazie, zwłaszcza gdy jedna tabela obsługuje wielu użytkowników, klientów albo zespołów. W tym artykule pokazuję, czym jest ten mechanizm, jak działa w praktyce, gdzie daje największy sens, czym różni się od klasycznych uprawnień i jakie błędy najczęściej psują jego skuteczność.
Najważniejsze fakty o kontroli dostępu na poziomie wierszy
- Mechanizm filtruje dane w bazie tak, aby użytkownik widział tylko dozwolone wiersze, a nie całą tabelę.
- Nie zastępuje uprawnień GRANT, tylko dodaje do nich bardziej precyzyjną warstwę ochrony.
- Najlepiej sprawdza się w aplikacjach wielotenantowych, panelach administracyjnych i systemach z danymi wrażliwymi.
- Polityka zwykle opiera się na warunku logicznym, który baza ocenia przy odczycie i zapisie.
- Źle zaprojektowana polityka może spowolnić zapytania albo stworzyć fałszywe poczucie bezpieczeństwa.
- W praktyce trzeba testować nie tylko `SELECT`, ale też `INSERT`, `UPDATE` i `DELETE`.
Czym jest kontrola dostępu na poziomie wierszy
Najprościej ujmując, chodzi o to, że baza sama decyduje, które rekordy wolno pokazać danemu użytkownikowi lub procesowi. Zamiast polegać wyłącznie na filtrach w aplikacji, definiuję regułę w warstwie bazy, dzięki czemu każdy odczyt i zapis przechodzi przez ten sam punkt kontroli.
W praktyce to rozwiązanie przydaje się wtedy, gdy jedna tabela przechowuje dane wielu klientów, pracowników albo oddziałów i każdy ma widzieć tylko swój fragment. To szczególnie ważne w systemach SaaS, aplikacjach finansowych, HR, medycznych i wszędzie tam, gdzie pomyłka w warstwie aplikacji mogłaby ujawnić cudze dane.
Najważniejsze jest to, że taki mechanizm działa centralnie. Jeśli ktoś odpyta bazę z innego miejsca niż aplikacja główna, na przykład z narzędzia analitycznego albo konsoli SQL, nadal obowiązuje ta sama polityka. Właśnie dlatego nie traktuję go jako dodatku, tylko jako warstwę bezpieczeństwa, która domyka cały model dostępu. Z tego punktu płynnie przechodzimy do tego, jak baza faktycznie stosuje takie reguły do zapytań.
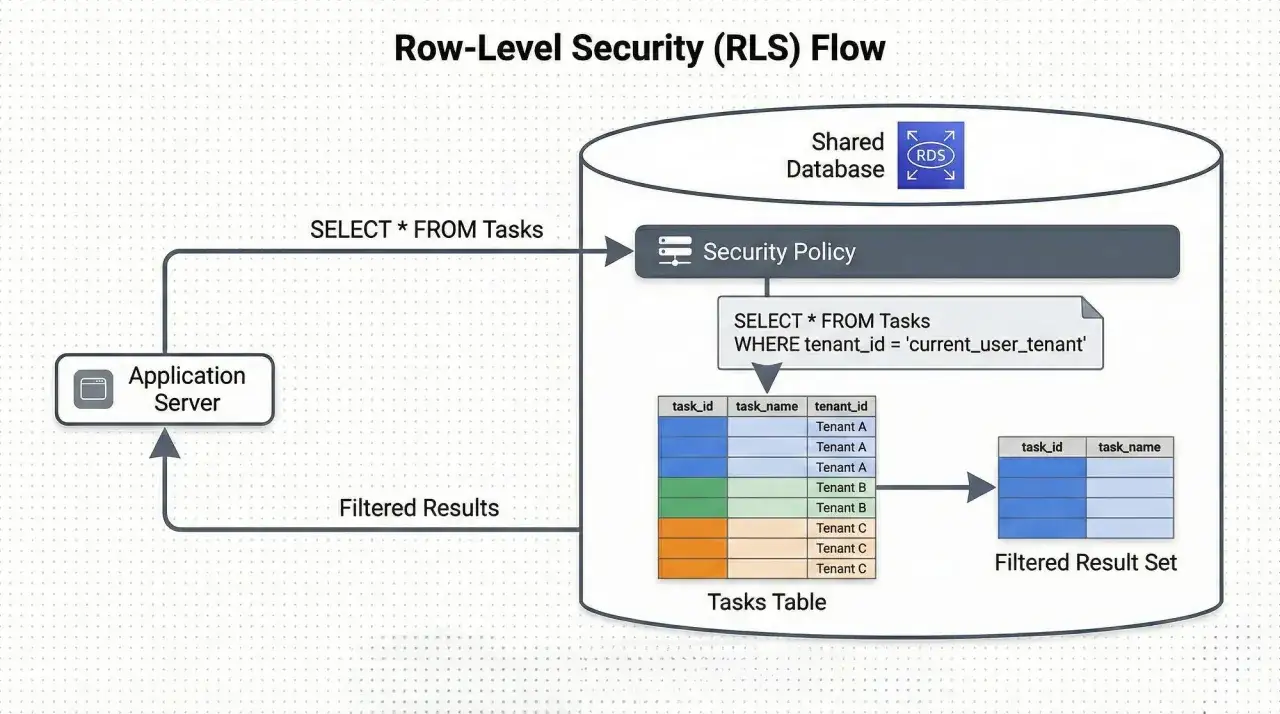
Jak baza stosuje politykę do zapytania
W praktyce silnik bazy dołącza do zapytania warunek logiczny, który mówi, które wiersze są widoczne, a które mają zostać odrzucone. W zależności od systemu zarządzania bazą ta reguła ma inną nazwę i inną składnię, ale cel pozostaje ten sam: baza ocenia uprawnienia na poziomie danych, a nie całej tabeli.
-- Przykład w stylu PostgreSQL
ALTER TABLE invoices ENABLE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation ON invoices
USING (tenant_id = current_setting('app.tenant_id')::int)
WITH CHECK (tenant_id = current_setting('app.tenant_id')::int);W tym układzie warunek USING określa, które wiersze można odczytać albo wskazać do modyfikacji, a WITH CHECK pilnuje, żeby nowo zapisywany rekord też spełniał regułę. Ja zwykle zapisuję obie części razem, bo rozdzielenie odczytu i zapisu to jeden z najczęstszych miejsc błędów.
Różne bazy realizują ten pomysł inaczej, ale logika jest podobna. W PostgreSQL definiuje się polityki dla tabel, w SQL Server używa się predykatów bezpieczeństwa opartych na funkcji tabelarycznej, a Oracle dokleja dynamiczny warunek WHERE do zapytania przez VPD. To brzmi podobnie, ale w szczegółach są ważne różnice.
| Silnik | Jak to działa | Co warto zapamiętać |
|---|---|---|
| PostgreSQL | Polityki przypisane do tabeli, oceniane dla wybranych operacji | Po włączeniu ochrony brak polityki oznacza domyślnie brak widoczności danych |
| SQL Server | Predykaty filtrowania i blokowania oparte o funkcje inline table-valued | Oddziela odczyt od zapisu i pozwala blokować nie tylko selekty, ale też zmiany |
| Oracle | VPD dynamicznie dopisuje warunek do SQL | Dużo daje przy politykach opartych na kontekście sesji i atrybutach użytkownika |
To ważne, bo sam termin bywa używany szeroko, ale implementacja nie jest identyczna w każdej bazie. Gdy znam różnice, łatwiej mi zdecydować, czy politykę budować w samym silniku, czy tylko wspierać ją dodatkowymi regułami aplikacyjnymi.
Gdzie ten mechanizm daje największą wartość
W aplikacjach Pythona, zwłaszcza tych zbudowanych na ORM-ach i połączeniach współdzielonych między wieloma procesami, najczęściej widzę go w systemach wielotenantowych. Jeden schemat, jedna tabela, wielu klientów i każdy ma widzieć tylko własne rekordy - to jest naturalne środowisko dla takiej kontroli.
Najbardziej typowe scenariusze wyglądają tak:
- SaaS dla wielu klientów - każdy tenant widzi wyłącznie swoje faktury, projekty albo zgłoszenia.
- Systemy wewnętrzne - pracownik może przeglądać tylko dane swojego działu, regionu albo zespołu.
- Dane wrażliwe - w HR, finansach czy ochronie zdrowia dostęp musi być ograniczony nie do tabeli, ale do konkretnych wierszy.
- Raportowanie i ad hoc SQL - polityka działa także wtedy, gdy ktoś odpytuje bazę spoza głównej aplikacji.
Właśnie ten ostatni punkt bywa niedoceniany. Wiele zespołów zakłada, że skoro aplikacja filtruje rekordy, to wszystko jest załatwione. Problem pojawia się wtedy, gdy do bazy zagląda analityk, skrypt serwisowy albo administrator. Jeśli ochrona siedzi tylko w kodzie, wystarczy jedno obejście ścieżki, żeby reguły przestały działać. Dlatego następny krok to porównanie tego mechanizmu z innymi sposobami ochrony danych.
RLS a GRANT, widoki i filtrowanie w kodzie
Żeby nie przeceniać ani nie upraszczać tematu, zawsze zestawiam ten mechanizm z trzema innymi podejściami. Każde rozwiązuje inny problem, a dopiero razem dają sensowny model bezpieczeństwa.
| Mechanizm | Co kontroluje | Mocna strona | Słaba strona |
|---|---|---|---|
| GRANT | Prawo do tabeli, widoku, operacji lub kolumny | Jest prosty i czytelny | Nie rozróżnia wierszy, więc nie wystarcza przy danych współdzielonych |
| Widok z filtrem | To, co zwraca konkretne zapytanie | Dobrze maskuje złożoność zapytań | Działa tylko, jeśli wszyscy korzystają z widoku, a nie z tabeli źródłowej |
| Kontrola na poziomie wierszy | Widoczność i modyfikację konkretnych rekordów | Jest egzekwowana centralnie przez bazę | Wymaga dobrego projektu polityk i testów |
| Filtrowanie w aplikacji | Wynik po stronie kodu | Elastyczne i szybkie do wdrożenia | Najłatwiej je ominąć przypadkiem albo przez alternatywną ścieżkę dostępu |
Ja zwykle traktuję RLS jako warstwę obowiązkową, a widoki i filtrację w aplikacji jako dodatkowe ułatwienie dla zespołu. To ważne rozróżnienie: nie zamieniam bezpieczeństwa na wygodę. Widok może pomóc uprościć zapytania, ale nie powinien być jedyną linią obrony, jeśli baza przechowuje dane, które trzeba realnie odseparować. Z tego powodu warto też znać najczęstsze błędy przy wdrażaniu takiej polityki.
Najczęstsze błędy, które psują bezpieczeństwo
Największy problem widzę wtedy, gdy zespół myśli wyłącznie o odczycie, a zapomina o zapisie. W praktyce trzeba sprawdzić osobno: kto może zobaczyć rekord, kto może go zmienić i czy po zmianie nadal spełnia warunki polityki.
- Testowanie tylko `SELECT` - polityka może działać przy odczycie, ale przepuszczać błędne `UPDATE` albo `INSERT`.
- Brak kontroli kontekstu sesji - jeśli identyfikator tenanta lub roli nie jest poprawnie ustawiany przy każdym połączeniu, ochrona zaczyna działać losowo.
- Zbyt złożony predykat - warunek bezpieczeństwa, którego nie da się dobrze zindeksować, szybko staje się problemem wydajnościowym.
- Założenie, że administrator zawsze widzi wszystko tak samo - w różnych silnikach zachowanie kont uprzywilejowanych jest inne i trzeba to sprawdzić osobno.
- Mylenie ochrony wierszy z maskowaniem kolumn - to nie jest to samo; czasem trzeba dodatkowo ukrywać konkretne pola, a nie całe rekordy.
- Brak testów narzędzi pomocniczych - eksport, raporty, zadania wsadowe i skrypty serwisowe potrafią ominąć ścieżkę, na której bazuje aplikacja webowa.
W SQL Server dochodzą jeszcze specyficzne ograniczenia związane z predykatami filtrującymi i blokującymi, a w PostgreSQL trzeba pamiętać o wyjątkach dla właściciela tabeli i ról uprzywilejowanych. Wniosek jest prosty: nie wolno zakładać, że jedna dobra definicja polityki załatwia cały temat. Potrzebny jest jeszcze plan wdrożenia i utrzymania.
Jak przygotować politykę, żeby dało się ją utrzymać
Jeżeli projektuję takie zabezpieczenie od zera, zaczynam od prostego pytania: od czego naprawdę zależy dostęp do danych? Najczęściej okazuje się, że to nie jest jedna zmienna, tylko kombinacja kilku atrybutów - organizacji, roli, regionu, typu rekordu albo statusu procesu. Dopiero wtedy zapisuję regułę w bazie.
- Ustalam jeden nadrzędny wymiar izolacji, na przykład
tenant_id,department_idalboowner_id. - Przenoszę ten kontekst do sesji albo do mechanizmu, który baza może odczytać bez zgadywania po stronie aplikacji.
- Definiuję osobno reguły dla
SELECT,INSERT,UPDATEiDELETE. - Dodaję testy integracyjne z użytkownikami o różnych rolach i z różnymi wartościami kontekstu.
- Sprawdzam indeksy pod warunek polityki, żeby nie zamienić bezpieczeństwa w kosztowny pełny skan.
- Rozdzielam konta serwisowe, administracyjne i raportowe, zamiast zakładać, że jedno konto zrobi wszystko.
W aplikacjach Pythona bardzo pomaga mi też konsekwentne zarządzanie połączeniami. Przy poolingu trzeba pilnować, żeby kontekst sesji był ustawiany i czyszczony w sposób deterministyczny, bo inaczej jedna prośba może odziedziczyć stan poprzedniej. To już nie jest problem samej bazy, tylko sposobu, w jaki aplikacja korzysta z połączeń.
Trzy rzeczy, które sprawdzam przed uruchomieniem na produkcji
Pierwsza rzecz to zachowanie przy prawdziwych operacjach, a nie tylko na prostych testowych zapytaniach. Sprawdzam, czy polityka działa dla odczytu, aktualizacji, wstawiania i usuwania oraz czy nie przepuszcza danych po zmianie wartości kluczowych kolumn.
Druga rzecz to ścieżki uprzywilejowane. Backup, panel administracyjny, skrypty migracyjne i raporty muszą mieć jasno opisane zasady dostępu, bo to właśnie tam najłatwiej o niechciane obejście zabezpieczenia. Jeśli polityka ma być fundamentem bezpieczeństwa, nie może być zależna od pamięci konkretnej osoby w zespole.
Trzecia rzecz to koszt utrzymania. Dobra polityka jest czytelna, testowalna i możliwa do wyjaśnienia w dwóch zdaniach. Jeśli po kilku miesiącach nikt nie potrafi powiedzieć, dlaczego dany rekord jest widoczny albo niewidoczny, to znaczy, że model wymaga uproszczenia albo lepszego komentarza w dokumentacji wewnętrznej. Najlepsze polityki są niewidoczne dla użytkownika, ale bardzo konkretne dla zespołu, który je utrzymuje.