Dobrze zaprojektowane bazy danych decydują o tym, czy aplikacja będzie łatwa w rozwoju, szybka w wyszukiwaniu informacji i odporna na chaos w danych. W tym tekście wyjaśniam, jak działa model relacyjny, gdzie wchodzi SQL, jak dobrać silnik do projektu i na co uważać, gdy łączysz bazę z Pythonem. To materiał dla osoby, która chce zrozumieć temat praktycznie, bez suchych definicji.
Najważniejsze decyzje przy pracy z danymi
- Model relacyjny opiera się na tabelach, kluczach i schemacie, a SQL służy do odczytu, zapisu i porządkowania rekordów.
- SQLite sprawdza się przy prototypach i małych narzędziach, PostgreSQL przy bardziej wymagających aplikacjach, a MySQL lub MariaDB w wielu klasycznych wdrożeniach webowych.
- Indeksy przyspieszają odczyt, ale zwiększają koszt zapisu, więc trzeba je dodawać tam, gdzie faktycznie pomagają.
- Parametryzowane zapytania to podstawowa ochrona przed SQL injection.
- W Pythonie najprościej zacząć od `sqlite3`, a potem przejść do dedykowanego sterownika lub ORM.
Jak rozumieć model relacyjny bez żargonu
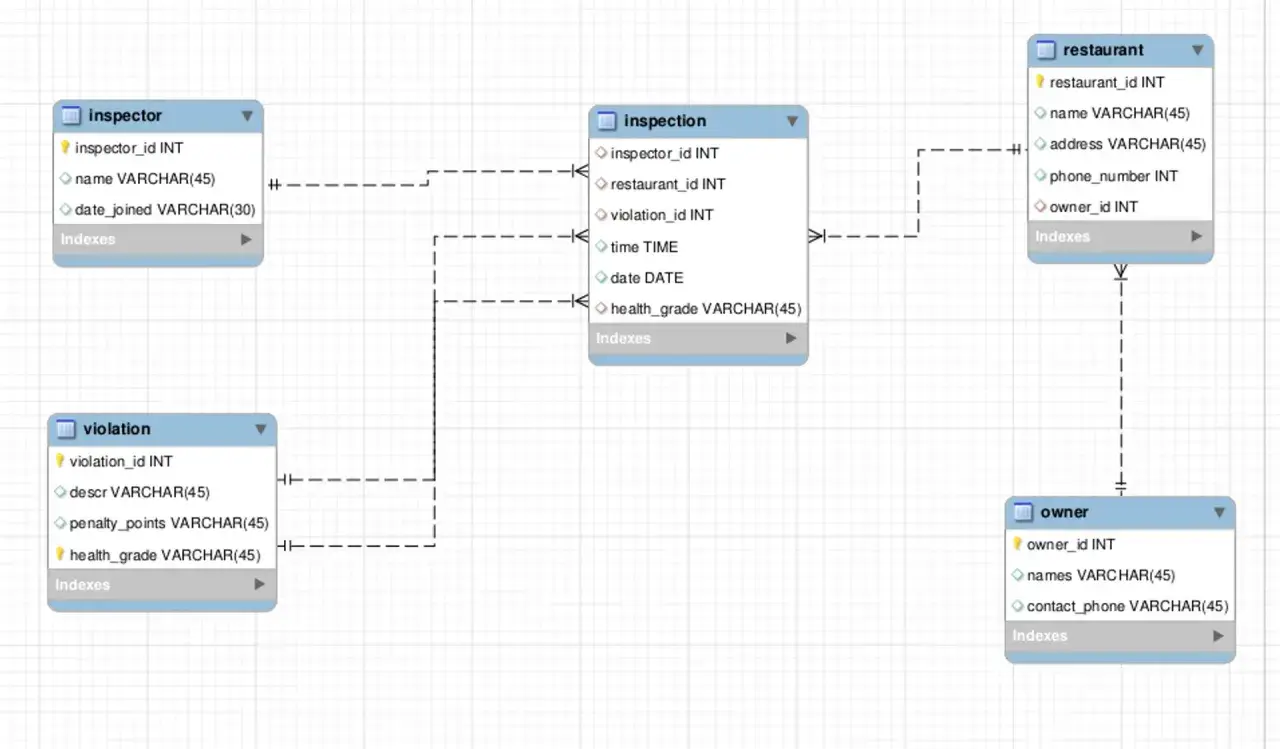
Najpierw porządkuję pojęcia. Relacyjny model opiera się na tabelach, a każda tabela opisuje jeden typ obiektów: klientów, zamówienia, produkty albo wpisy blogowe. Wiersz to pojedynczy rekord, kolumna to cecha rekordu, a schemat określa, jakie pola w ogóle istnieją i jakiego są typu.
W praktyce największą różnicę robią trzy rzeczy: klucz główny, który jednoznacznie identyfikuje rekord, klucz obcy, który łączy tabele ze sobą, oraz ograniczenia, które pilnują jakości danych. Dzięki temu nie muszę zgadywać, czy numer klienta naprawdę istnieje albo czy cena może być ujemna. Gdy te reguły są dobrze ustawione, aplikacja mniej się psuje i łatwiej ją rozwijać.
Normalizacja, czyli rozdzielanie danych na sensowne tabele, zwykle zmniejsza duplikację i ułatwia aktualizacje, ale nie jest religią. Czasem świadomie zostawia się pewną redundancję, jeśli poprawia to szybkość odczytu albo upraszcza raporty. Z takim fundamentem SQL przestaje być abstrakcją i staje się narzędziem do operowania na strukturze, którą właśnie opisałem.
Gdy ten model jest jasny, SQL zaczyna wyglądać jak naturalny język pracy z tabelami, a nie zbiór przypadkowych poleceń.
Jak SQL porządkuje pracę z rekordami
SQL jest językiem, którym pytasz bazę o dane i mówisz jej, co ma zmienić. Najważniejsze polecenia to `SELECT` do odczytu, `INSERT` do dodawania, `UPDATE` do modyfikacji i `DELETE` do usuwania. Do tego dochodzą polecenia strukturalne, takie jak `CREATE TABLE`, `ALTER TABLE` i `DROP TABLE`, bo bez nich nie zbudujesz stabilnego schematu.
W praktyce liczą się też filtry i łączenia. `WHERE` zawęża wynik, `JOIN` łączy dane z kilku tabel, `GROUP BY` zbiera rekordy w grupy, a `ORDER BY` ustawia kolejność. To właśnie tutaj większość początkujących łapie pierwszy moment, w którym wszystko zaczyna się składać, bo okazuje się, że SQL nie służy do ręcznego przeglądania tabel, tylko do zadawania precyzyjnych pytań o dane.
SELECT name, price
FROM products
WHERE price < 100
ORDER BY price ASC;Do tego dochodzą transakcje. Jeśli kilka operacji ma tworzyć jedną całość, zamykam je w transakcji, żeby albo wykonały się wszystkie, albo żadna. To szczególnie ważne przy płatnościach, stanach magazynowych i rejestracji użytkowników. Gdy opanujesz ten poziom, kolejny krok to nie więcej składni, tylko wybór odpowiedniego silnika pod realne obciążenie.
Jak wybrać silnik do projektu, gdy liczy się praktyka
Wybór zależy od skali, liczby zapisów i tego, czy chcesz uruchomić system bez osobnej infrastruktury. Ja zwykle patrzę na to tak: jeśli projekt ma być lokalny, prosty albo prototypowy, wystarczy lekka baza plikowa; jeśli ma pracować dla wielu użytkowników i przechowywać krytyczne dane, lepiej od razu postawić na pełny silnik serwerowy.
| Silnik | Kiedy ma sens | Największy plus | Ograniczenie |
|---|---|---|---|
| SQLite | prototypy, narzędzia lokalne, małe aplikacje | jeden plik, brak osobnego serwera, szybki start | słabiej znosi intensywny zapis równoległy |
| PostgreSQL | aplikacje webowe, większy ruch, mocne wymagania spójności | rozbudowany SQL, dobre ograniczenia, solidna transakcyjność | wymaga więcej konfiguracji i utrzymania |
| MySQL lub MariaDB | klasyczne projekty webowe i środowiska hostingowe, które już to wspierają | popularność w wielu stackach i łatwa dostępność | warto znać różnice dialektu i funkcji między implementacjami |
Przy małym projekcie kusząca jest prostota, ale nie mylę jej z najlepszym wyborem na lata. Jeśli od początku spodziewam się wielu jednoczesnych zapisów albo raportowania w tle, nie upieram się przy rozwiązaniu plikowym tylko dlatego, że startuje szybciej. To prowadzi prosto do błędów, które najczęściej ujawniają się dopiero po wdrożeniu.
Niezależnie od silnika, najwięcej problemów zwykle nie bierze się z technologii, tylko z błędów projektowych i bezpieczeństwa.
Najczęstsze błędy, które kosztują czas i dane
Najwięcej problemów widziałem nie w samym SQL-u, tylko w złym myśleniu o schemacie i bezpieczeństwie. To są rzeczy, które naprawdę psują projekty najczęściej:
- Brak ograniczeń integralności - jeśli nie ustawisz kluczy, typów i reguł, dane zaczną się rozjeżdżać szybciej, niż zakładasz. Błąd w aplikacji nie powinien mieć prawa zapisać niepoprawnego rekordu.
- Sklejanie zapytań z tekstu - to prosta droga do SQL injection. Zamiast tego używaj zapytań parametryzowanych, bo wejście użytkownika nie powinno zmieniać struktury zapytania.
- Indeksy dodawane na ślepo albo wcale - indeks przyspiesza odczyt, ale kosztuje przy zapisie i zajmuje miejsce. Daj go tam, gdzie naprawdę filtrujesz, sortujesz albo łączysz dane.
- Zbyt duże tabele bez podziału na sensowne encje - jedna uniwersalna tabela zwykle kończy się mnóstwem pustych kolumn, trudnymi aktualizacjami i chaosem w raportach.
- Brak transakcji przy operacjach wieloetapowych - jeśli zapis ma znaczenie biznesowe, musi być atomowy. W przeciwnym razie jedna awaria zostawia system w stanie pośrednim.
W ochronie przed SQL injection najbezpieczniej działa właśnie parametryzacja, bo dane trafiają do zapytania jako wartości, a nie jako część kodu. To jedna z tych praktyk, które warto wdrożyć od pierwszego projektu, a nie dopiero po audycie. Kiedy te podstawowe błędy masz pod kontrolą, integracja z Pythonem staje się dużo prostsza.
Jak łączyć Python i SQL bez zbędnej warstwy magii
W Pythonie najłatwiej zacząć od `sqlite3`, bo moduł jest w standardowej bibliotece i pozwala pracować z plikiem albo z bazą w pamięci. To dobre środowisko do nauki, prototypów i małych narzędzi, a potem ten sam model myślenia przenosisz do PostgreSQL albo MySQL przez dedykowany sterownik.
import sqlite3
with sqlite3.connect("app.db") as conn:
cur = conn.cursor()
cur.execute(
"SELECT id, name FROM users WHERE email = ?",
(email,)
)
user = cur.fetchone()W tym przykładzie najważniejszy jest znak `?`. To placeholder, czyli miejsce na wartość przekazywaną osobno od tekstu zapytania. Dzięki temu nie składasz SQL-a przez konkatenację stringów i nie otwierasz drzwi dla wstrzyknięć. W innych sterownikach składnia parametrów bywa inna, ale zasada pozostaje ta sama: kod i dane mają być rozdzielone.
Warto też używać kontekstu `with`, bo zamyka połączenie i pomaga domknąć transakcję bez ręcznego pilnowania każdego kroku. Jeśli projekt rośnie, ORM może przyspieszyć pracę, ale nie zastąpi rozumienia zapytań, złączeń i indeksów. Najlepsze efekty daje ten moment, w którym wiesz, kiedy użyć warstwy abstrakcji, a kiedy zejść niżej i napisać SQL ręcznie. Z tego właśnie wynika sens kolejnej sekcji: nie ucz się wszystkiego naraz, tylko w właściwej kolejności.
Ścieżka nauki, która daje szybki zwrot
Jeśli chcesz wejść w temat bez błądzenia, układam naukę w takiej kolejności:
- Zrozum model danych - ustal, jakie encje istnieją w projekcie i jakie relacje je łączą.
- Napisz kilka prostych zapytań SELECT - filtruj po `WHERE`, sortuj po `ORDER BY` i pobieraj tylko te kolumny, których naprawdę potrzebujesz.
- Dodaj złączenia i agregacje - `JOIN`, `GROUP BY` i `HAVING` to moment, w którym z pojedynczych tabel zaczynasz robić sensowne raporty.
- Wprowadź ograniczenia i transakcje - dzięki nim baza sama pilnuje spójności zamiast liczyć wyłącznie na kod aplikacji.
- Sprawdź wydajność w jednym konkretnym miejscu - zanim dodasz indeksy wszędzie, zobacz, które zapytania naprawdę są ciężkie.
- Połącz to z projektem w Pythonie - nawet prosty CRUD uczy więcej niż sama teoria, bo wymusza pracę z rzeczywistym przepływem danych.
Ta kolejność działa, bo najpierw buduje rozumienie struktury, a dopiero potem dokłada narzędzia. W praktyce szybciej dojdziesz do momentu, w którym umiesz samodzielnie odróżnić problem w modelu od problemu w zapytaniu. A kiedy to umiesz, łatwiej podjąć decyzję, co naprawdę warto zapamiętać na dłużej.
Co naprawdę ma znaczenie, gdy projekt zaczyna rosnąć
Najlepszy punkt wyjścia to nie najbardziej rozbudowany silnik, tylko taki układ, który pasuje do obciążenia i zespołu. Dla aplikacji lokalnej wystarczy lekkie rozwiązanie, dla systemu wieloużytkownikowego przyda się pełniejszy serwer, a dla każdego projektu wspólny mianownik jest ten sam: poprawny schemat, rozsądne indeksy, transakcje i parametryzowane zapytania.- Na początku projektuj mniej tabel, ale dokładniej.
- Dodawaj indeksy wtedy, gdy masz konkretny problem z odczytem.
- Traktuj bezpieczeństwo jako domyślne ustawienie, nie dodatkową funkcję.
- Nie zakładaj, że ORM zwalnia z myślenia o SQL.
Jeśli trzymasz się tych zasad, praca z danymi staje się przewidywalna, a aplikacja łatwiejsza w rozwoju. I to jest właśnie praktyczna różnica między chaotycznym magazynem rekordów a dobrze zaprojektowanym systemem, który można spokojnie rozbudowywać.