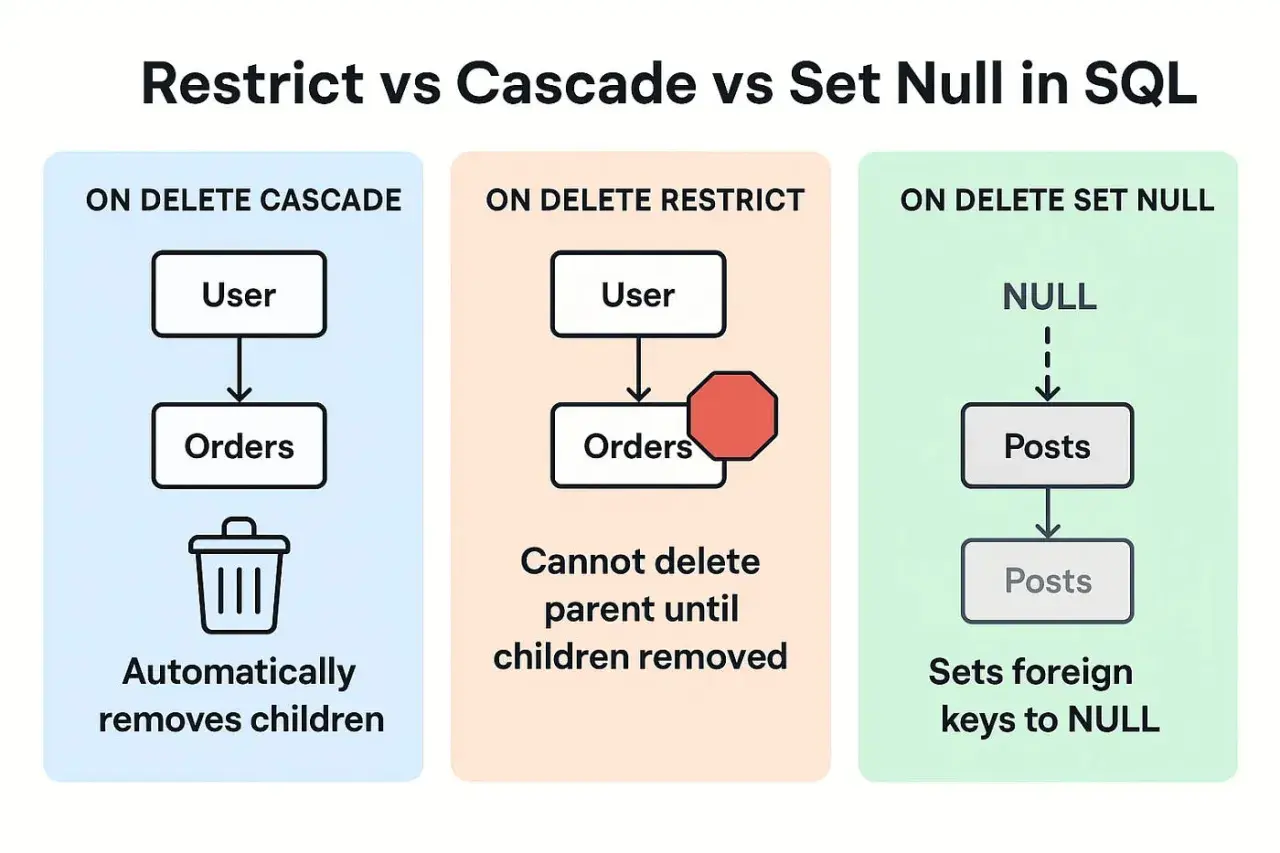
Najważniejsze zasady usuwania kaskadowego w bazie danych
- Kaskada działa przez klucz obcy - baza usuwa rekordy podrzędne tylko wtedy, gdy relacja jest poprawnie zdefiniowana.
- To dobre rozwiązanie dla danych zależnych, np. pozycji zamówienia, wpisów w tabelach łącznikowych i podobnych struktur.
- Nie stosuj jej do danych historycznych, logów, audytu ani tam, gdzie rekord ma wartość samodzielną.
- Alternatywy to blokada usunięcia, ustawienie wartości `NULL` albo ręczne kasowanie w transakcji.
- W SQLite trzeba włączyć egzekwowanie kluczy obcych, a w MySQL kaskadowe akcje nie uruchamiają triggerów.
Jak działa usuwanie kaskadowe między tabelami
Najprościej mówiąc, baza danych pilnuje relacji rodzic-dziecko. Rekord rodzica znajduje się w tabeli nadrzędnej, a rekordy dziecka w tabeli podrzędnej odwołują się do niego przez klucz obcy. Jeśli usuwasz rodzica, baza nie musi zgadywać, co zrobić z dziećmi - wykonuje z góry zdefiniowaną regułę i usuwa je automatycznie.
To ma sens tylko wtedy, gdy dane podrzędne naprawdę nie powinny istnieć bez rodzica. W przeciwnym razie kaskada może okazać się zbyt agresywna. Ja zwykle patrzę na to bardzo praktycznie: jeśli usunięcie jednego wiersza ma wyczyścić całe „drzewo” powiązanych rekordów, to chcę mieć pewność, że ta zależność jest biznesowo bezdyskusyjna.
Warto też pamiętać, że chodzi o ochronę spójności referencyjnej. Baza nie pozwala wtedy zostawić „sierot”, czyli rekordów, które wskazują na coś, czego już nie ma. Dzięki temu schemat danych jest prostszy do utrzymania, a aplikacja nie musi ręcznie sprzątać każdej relacji osobno. Żeby zobaczyć to bez teorii, przejdźmy do prostego modelu zamówień i pozycji zamówienia.
 2` filtruje wyniki, aby wyświetlić tylko te wydziały, które mają więcej niż 2 studentów, co jest przykładem działan...">
2` filtruje wyniki, aby wyświetlić tylko te wydziały, które mają więcej niż 2 studentów, co jest przykładem działan...">
Przykład z zamówieniami, który pokazuje mechanizm w praktyce
Najczytelniejszy przykład to zamówienie i jego pozycje. Gdy usuwasz zamówienie, zwykle nie chcesz zostawiać pozycji zamówienia bez kontekstu, bo one nie mają samodzielnego znaczenia. Właśnie tu kaskada robi robotę.
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_email VARCHAR(255) NOT NULL
);
CREATE TABLE order_items (
id INT PRIMARY KEY,
order_id INT NOT NULL,
product_name VARCHAR(255) NOT NULL,
quantity INT NOT NULL,
CONSTRAINT fk_order_items_order
FOREIGN KEY (order_id) REFERENCES orders(id) ON DELETE CASCADE
);
DELETE FROM orders WHERE id = 42;Po wykonaniu takiego `DELETE` baza usuwa nie tylko rekord z `orders`, ale też wszystkie wiersze z `order_items`, które wskazują na `order_id = 42`. To oszczędza kod aplikacji i eliminuje ryzyko, że ktoś zapomni o jednym z powiązanych miejsc. W podobny sposób działa to też w tabelach łącznikowych many-to-many, gdzie kaskada zwykle czyści same powiązania, a nie dane główne.
W praktyce ten wzorzec jest bardzo wygodny, ale tylko wtedy, gdy relacja jest naprawdę hierarchiczna. To prowadzi do ważniejszego pytania: kiedy kaskada naprawdę pomaga, a kiedy lepiej jej nie włączać.
Kiedy kaskada ma sens, a kiedy szkodzi
Najbezpieczniej traktować kaskadę jako narzędzie dla danych zależnych, a nie jako domyślny sposób sprzątania wszystkiego, co powiązane. W projektach, które widzę najczęściej, dobrze sprawdza się w kilku powtarzalnych sytuacjach.
Dobry wybór, gdy dane są czysto zależne
- pozycje zamówienia zależne od nagłówka zamówienia,
- rekordy w tabelach łącznikowych, np. przypisania użytkownik-rola,
- szczegóły techniczne, które nie mają sensu bez nadrzędnego obiektu,
- dane tymczasowe lub robocze, które nie powinny żyć dłużej niż byt nadrzędny.
Przeczytaj również: Relacyjne bazy danych - Przewodnik po SQL, kluczach i JOIN-ach
Lepiej jej unikać, gdy dane mają wartość samodzielną
- logi i audyt, które trzeba zachować dla historii lub zgodności,
- dane archiwalne,
- rekordy współdzielone przez wiele obiektów,
- modele z miękkim usuwaniem, gdzie zamiast kasowania zapisujesz status lub datę usunięcia.
Tu właśnie najczęściej pojawia się błąd początkujących: widzą wygodę i włączają kaskadę wszędzie, gdzie coś „pasuje”. A potem okazuje się, że usunięcie jednego obiektu wyczyściło więcej danych, niż ktokolwiek przewidywał. Gdy wybór nie jest oczywisty, warto zestawić kaskadę z innymi akcjami referencyjnymi.
Jak wypada wobec `RESTRICT`, `SET NULL` i ręcznego usuwania
Nie każda relacja powinna kończyć się automatycznym kasowaniem. Czasem lepiej zablokować usunięcie, czasem zachować rekord dziecka i tylko odłączyć go od rodzica, a czasem przejąć pełną kontrolę po stronie aplikacji. Poniższe zestawienie dobrze pokazuje różnice.
| Mechanizm | Co robi po usunięciu rodzica | Kiedy ma sens | Ryzyko lub ograniczenie |
|---|---|---|---|
| Kaskada usuwania | Usuwa wszystkie powiązane rekordy podrzędne | Gdy dziecko nie ma sensu bez rodzica | Może wyczyścić zbyt dużo danych, jeśli relacja jest źle zaprojektowana |
| `RESTRICT` / `NO ACTION` | Blokuje usunięcie rodzica, jeśli istnieją rekordy podrzędne | Gdy chcesz wymusić ręczne uporządkowanie danych | Trzeba wcześniej usunąć lub przepiąć zależne wiersze |
| `SET NULL` | Zostawia rekord dziecka, ale zeruje klucz obcy | Gdy dziecko ma wartość samodzielną, ale bez rodzica traci powiązanie | Kolumna obcego klucza musi dopuszczać `NULL` |
| Ręczne usuwanie w aplikacji | Aplikacja usuwa dane w ustalonej kolejności | Gdy logika jest złożona albo zależy od warunków biznesowych | Więcej kodu, większa odpowiedzialność po stronie programu |
Jeśli mam wskazać praktyczną regułę, to jest ona dość prosta: im bardziej oczywista zależność między rekordami, tym bardziej naturalna jest kaskada. Im więcej wyjątków biznesowych, tym bardziej skłaniam się ku blokadzie albo ręcznej logice w transakcji. Problem w tym, że na papierze wszystko wygląda prosto, a w silnikach baz danych pojawiają się detale, które potrafią zaskoczyć.
Pułapki, które najczęściej wychodzą dopiero w produkcji
Najwięcej problemów nie wynika z samej idei, tylko z założeń, które ktoś zrobił przy wdrożeniu. W różnych silnikach baza zachowuje się podobnie na poziomie koncepcji, ale w szczegółach różnice są realne.
| Silnik | Na co uważać |
|---|---|
| PostgreSQL | Mechanizm jest zgodny z klasycznym modelem kluczy obcych, więc kluczowe są poprawne relacje i testy wielopoziomowych usunięć. |
| MySQL | Kaskadowe akcje nie uruchamiają triggerów, więc nie opieraj audytu wyłącznie na triggerach. |
| SQLite | Egzekwowanie kluczy obcych trzeba włączyć jawnie, na przykład przez `PRAGMA foreign_keys = ON`. |
- Nie zakładaj, że test lokalny mówi wszystko - ta sama relacja może zachowywać się inaczej, jeśli zmieniasz silnik albo konfigurację.
- Uważaj na duże usunięcia - jeden rekord nadrzędny może pociągnąć za sobą tysiące lub miliony wierszy podrzędnych.
- Nie mieszaj kaskady z miękkim usuwaniem bez planu - jeśli używasz pola typu `deleted_at`, automatyczne kasowanie często rozmija się z logiką aplikacji.
- Sprawdzaj ścieżki zależności - łańcuchy kilku tabel mogą być trudne do przewidzenia, jeśli schemat był rozwijany przez dłuższy czas.
To wszystko prowadzi do jednego wniosku: kaskada sama w sobie nie jest ani dobra, ani zła. Jest po prostu bardzo skuteczna, więc trzeba używać jej z precyzją. Dlatego przed wdrożeniem warto przejść przez krótki, praktyczny checklist.
Co sprawdzić, zanim włączysz kaskadę w istniejącym projekcie
Zanim zmienisz schemat w produkcyjnym systemie, przejdź przez kilka konkretnych pytań. To oszczędza późniejszych niespodzianek, a przy okazji zmusza do uczciwego przemyślenia zależności między tabelami.
- Czy rekord podrzędny naprawdę nie ma sensu bez nadrzędnego? Jeśli ma, kaskada zwykle nie jest dobrym wyborem.
- Ile danych może zniknąć jednym poleceniem? Warto oszacować skalę, zwłaszcza w relacjach 1:N i łańcuchach kilku tabel.
- Czy masz testy na usuwanie rodzica z realistycznymi danymi? Pusty sandbox nie pokaże problemów z objętością i zależnościami.
- Czy backup i odtwarzanie są sprawdzone? Kaskada jest bezpieczna tylko wtedy, gdy masz plan awaryjny.
- Czy logika aplikacji nie zakłada ręcznego usuwania? Jeśli tak, trzeba zsynchronizować kod z nowym zachowaniem bazy.
Jeśli miałbym zostawić jedną praktyczną zasadę, brzmiałaby tak: kaskadowe usuwanie wybieraj wtedy, gdy dane podrzędne są naprawdę częścią życia rekordu nadrzędnego, a nie tylko luźnym powiązaniem. W dobrze zaprojektowanym schemacie taka reguła upraszcza kod, zmniejsza liczbę błędów i odciąża aplikację, ale użyta bez dyscypliny potrafi wyczyścić więcej, niż planujesz.