Dobrze zaprojektowana baza relacyjna daje coś, czego wiele projektów potrzebuje od pierwszego dnia: porządek, spójność i przewidywalne zapytania. W tym tekście pokazuję, czym dokładnie jest relacyjny model danych, jak działają klucze, JOIN-y i normalizacja, kiedy SQL naprawdę ułatwia życie oraz w jakich sytuacjach lepiej nie forsować tego podejścia na siłę. To wiedza przydatna zarówno przy nauce, jak i przy budowie aplikacji w Pythonie.
Relacyjne bazy porządkują dane, a SQL utrzymuje nad nimi kontrolę
- Dane są przechowywane w tabelach, a ich powiązania tworzą klucze główne i obce.
- SQL nie służy wyłącznie do odczytu - tworzy schemat, modyfikuje dane i pilnuje spójności.
- Normalizacja ogranicza duplikację, a transakcje pomagają uniknąć częściowych zapisów.
- Ten model najlepiej sprawdza się tam, gdzie liczy się logiczna структура danych, raportowanie i integracja wielu tabel.
- Przy bardzo zmiennych danych albo złożonych strukturach grafowych warto rozważyć inne podejście.
Czym naprawdę jest relacyjny model danych
Relacyjny model danych opiera się na prostym założeniu: informacje zapisuje się w tabelach, czyli wierszach i kolumnach, a sens tych danych wynika z relacji między tabelami. Każdy wiersz opisuje pojedynczy rekord, a kolumny przechowują jego cechy, na przykład nazwę klienta, datę zamówienia albo kwotę płatności. To brzmi elementarnie, ale właśnie ta prostota daje dużą przewagę - struktura jest czytelna dla człowieka i jednocześnie wygodna dla silnika bazy.
W praktyce relacyjna baza danych to nie tylko same tabele, ale cały system zarządzania nimi, czyli RDBMS. Taki system pilnuje schematu, wykonuje zapytania, obsługuje indeksy, transakcje, kopie zapasowe i reguły spójności. Najważniejsze jest jednak to, że relacje między danymi są opisane logicznie, a nie przez ich fizyczne położenie na dysku. Dzięki temu można je swobodnie łączyć i odpytywać bez przepisywania całej struktury przy każdej zmianie biznesowej.
To właśnie dlatego ten model tak dobrze pasuje do aplikacji biznesowych, paneli administracyjnych i systemów, w których dane muszą być powiązane z konkretnymi regułami. Kiedy fundament jest już jasny, warto wejść głębiej w to, jak te powiązania są faktycznie budowane.
Jak działa porządkowanie danych przez klucze i relacje
Klucz główny i klucz obcy
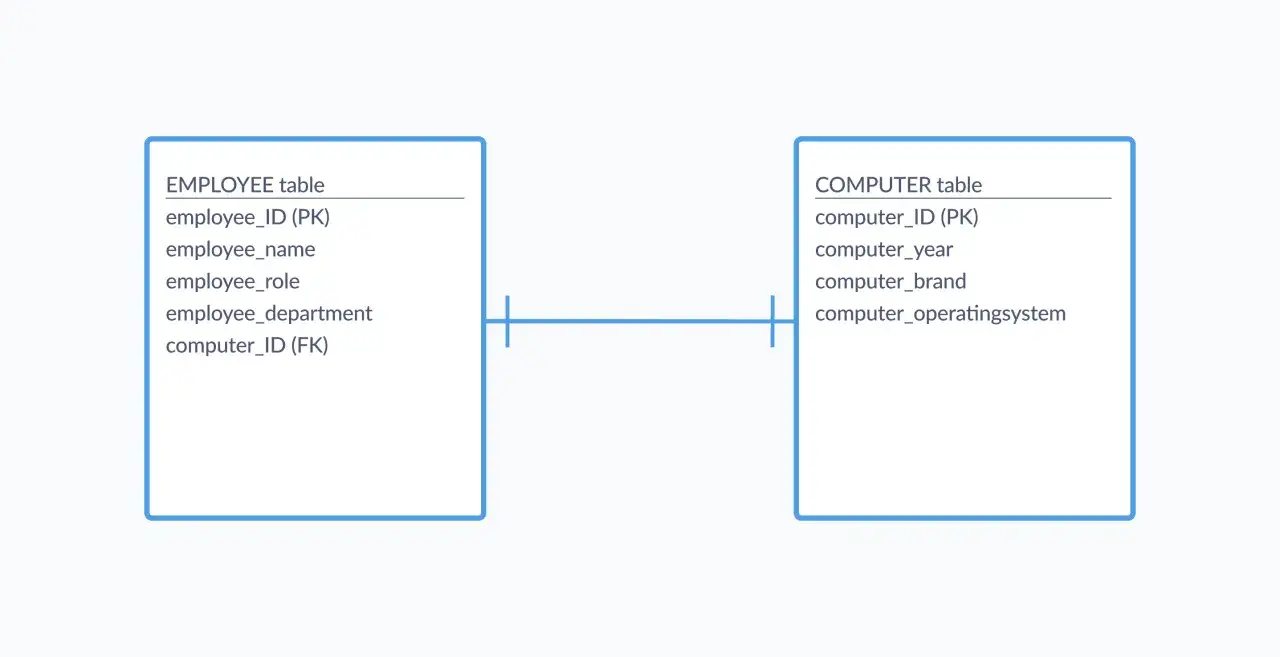
Klucz główny identyfikuje rekord jednoznacznie, a klucz obcy wskazuje na rekord w innej tabeli. W praktyce wygląda to tak: tabela users może mieć kolumnę id jako klucz główny, a tabela orders przechowuje user_id, który odwołuje się do konkretnego użytkownika. To pozwala uniknąć chaosu typu „ten sam klient zapisany pięć razy pod lekko inną nazwą”.
Największa korzyść z takiego układu to referential integrity, czyli spójność referencyjna. Baza nie pozwoli Ci odwołać się do klienta, który nie istnieje, jeśli ustawisz odpowiednie ograniczenia. Właśnie te reguły robią ogromną różnicę, gdy projekt zaczyna rosnąć i nie wystarcza już zwykłe „działa u mnie lokalnie”.
JOIN-y bez magii
Łączenie tabel, czyli JOIN, jest sercem pracy z relacyjnymi danymi. INNER JOIN pokazuje tylko rekordy, które pasują po obu stronach, a LEFT JOIN zachowuje wszystkie wiersze z tabeli po lewej stronie, nawet jeśli po prawej nie ma dopasowania. To niewielka różnica w składni, ale bardzo duża różnica w wyniku.
Dla czytelnika najważniejsze jest to, że relacje nie są tu abstrakcją. Jeżeli chcesz zobaczyć zamówienia konkretnego klienta, nie kopiujesz danych do nowej tabeli, tylko odwołujesz się do istniejących rekordów. To oszczędza miejsce, ogranicza duplikację i ułatwia aktualizację danych. Z tej samej zasady wynika jednak potrzeba rozsądnej normalizacji.
Przeczytaj również: Bazy danych od podstaw - SQL, Python i dobre praktyki
Normalizacja bez przesady
Normalizacja porządkuje strukturę tak, aby jedna informacja była zapisana w jednym miejscu. Najczęściej zaczyna się od pierwszej, drugiej i trzeciej postaci normalnej, bo właśnie one pomagają ograniczyć powtórzenia, błędy aktualizacji i rozjazdy między tabelami. Jeśli adres klienta trzymasz w trzech różnych miejscach, wcześniej czy później jeden z zapisów zacznie się różnić od pozostałych.
Nie robiłbym jednak z normalizacji dogmatu. W raportach i hurtowniach danych czasem celowo wprowadza się kontrolowaną denormalizację, żeby przyspieszyć odczyty albo uprościć analitykę. To kompromis, który ma sens wtedy, gdy wiesz, dlaczego go wprowadzasz. Gdy ten fundament jest ustawiony, naturalnie pojawia się pytanie o SQL, czyli o język, którym steruje się tą całą strukturą.
SQL, transakcje i kontrola spójności
SQL to język deklaratywny: mówisz w nim, co chcesz uzyskać, a silnik bazy sam dobiera sposób wykonania. To ważne rozróżnienie, bo wielu początkujących kojarzy SQL wyłącznie z SELECT, a tymczasem ten język obsługuje tworzenie schematu, modyfikację danych, kontrolę dostępu i transakcje. W praktyce to właśnie SQL spina cały relacyjny model w spójny system pracy.
| Grupa instrukcji | Do czego służy | Przykład |
|---|---|---|
| DDL | Tworzy i zmienia strukturę bazy |
CREATE TABLE, ALTER TABLE, DROP TABLE
|
| DML | Pracuje na danych |
SELECT, INSERT, UPDATE, DELETE
|
| TCL | Zarządza transakcjami |
COMMIT, ROLLBACK, SAVEPOINT
|
| DCL | Kontroluje uprawnienia |
GRANT, REVOKE
|
Transakcje są tym, co odróżnia zwykłe operacje od bezpiecznego wykonania kilku zmian naraz. Jeśli zapis zamówienia, płatność i zmiana stanu magazynu muszą wydarzyć się razem, baza ma zagwarantować, że nie zostaniesz z połową operacji po awarii albo błędzie aplikacji. Z tego powodu zwykle patrzę na cztery własności transakcyjne jako na praktyczny standard pracy:
- atomiczność - wszystko się zapisuje albo nic,
- spójność - baza nie łamie własnych reguł,
- izolacja - równoległe operacje nie mieszają sobie stanu,
- trwałość - zatwierdzone zmiany pozostają zapisane.
Właśnie dzięki SQL i transakcjom relacyjny model jest tak przewidywalny w systemach, gdzie błędny zapis kosztuje więcej niż kilka dodatkowych linii kodu. Taki fundament ma jednak sens przede wszystkim tam, gdzie dane mają określoną strukturę, więc przechodzę do pytania, kiedy to rozwiązanie naprawdę błyszczy.
Kiedy ten model sprawdza się najlepiej
Najlepsze zastosowania relacyjnych baz są bardzo konkretne. Widziałem je najczęściej w systemach, w których dane trzeba łączyć, filtrować i raportować, a jednocześnie pilnować reguł biznesowych. Najczęściej chodzi o:
- e-commerce - klienci, koszyki, zamówienia, płatności i statusy muszą być spójne,
- CRM i ERP - wiele powiązanych encji i dużo zależności między rekordami,
- systemy finansowe i księgowe - tu spójność i audyt są ważniejsze niż elastyczność schematu,
- aplikacje webowe z panelem administracyjnym - szybki odczyt, proste relacje i przewidywalna logika,
- raportowanie i analiza danych operacyjnych - zwłaszcza gdy trzeba łączyć dane z kilku źródeł.
Mniej komfortowo relacyjny model zachowuje się tam, gdzie każdy rekord może mieć zupełnie inną strukturę, a schemat zmienia się co chwilę. Dotyczy to na przykład części systemów logujących zdarzenia, danych dokumentowych o bardzo zmiennym kształcie albo problemów grafowych, w których najważniejsze są połączenia wielu typów węzłów. Właśnie wtedy porównanie z NoSQL przestaje być teorią i staje się decyzją architektoniczną.
Relacyjne bazy a NoSQL w praktycznym porównaniu
Nie traktuję tego jako wojny technologii. Patrzę raczej na to, jakie dane masz, jak często je zmieniasz i jakich zapytań będziesz używać najczęściej. W wielu projektach obie klasy rozwiązań mogą działać dobrze, ale każda wygrywa w innych warunkach.
| Kryterium | Relacyjny model | NoSQL |
|---|---|---|
| Struktura danych | Stały schemat, tabele i jasno opisane kolumny | Większa elastyczność, często dokumenty lub pary klucz-wartość |
| Spójność | Silna kontrola reguł i transakcji | Często większy nacisk na dostępność lub elastyczność kosztem ścisłej spójności |
| Łączenie danych |
JOIN jest naturalnym narzędziem |
Łączenia bywają trudniejsze lub przenoszone do aplikacji |
| Zmiana schematu | Wymaga dyscypliny i migracji | Łatwiejsza przy zmiennym modelu danych |
| Typowe zastosowanie | Systemy biznesowe, operacyjne i raportowe | Dane półstrukturalne, bardzo duża skala lub nietypowe wzorce dostępu |
Najbardziej praktyczna rada jest prosta: jeśli Twoje dane mają sensowną strukturę i będą regularnie łączone, relacyjny model zwykle wygrywa na starcie i długo później. Jeśli natomiast schemat zmienia się gwałtownie, a rekordy bywają bardzo różne między sobą, wtedy szukanie kompromisu w SQL może być bardziej kosztowne niż przejście na model dokumentowy. W projektach Pythona ta decyzja bardzo często przekłada się na codzienną wygodę pracy, więc warto zejść z poziomu teorii do konkretów wdrożeniowych.
Jak zacząć rozsądnie w projekcie Pythonowym
W Pythonie najczęściej zaczynam od prostego modelu danych i dopiero potem dokładam warstwę wygody. ORM, czyli mapper obiektowo-relacyjny, tłumaczy obiekty Pythona na tabele, ale nie zwalnia z myślenia o strukturze danych. To narzędzie przyspiesza pracę, jednak nie zastępuje dobrze zaprojektowanego schematu ani sensownych zapytań SQL.
- Na prototyp lub małą aplikację wybierz SQLite, jeśli potrzebujesz lekkiego startu bez osobnego serwera.
- Do aplikacji webowej, zespołowej i bardziej wymagającej produkcyjnie najczęściej lepiej pasuje PostgreSQL.
- Modeluj tabele pod relacje między danymi, a nie pod wygląd pojedynczego formularza w UI.
- Zakładaj indeksy tylko tam, gdzie faktycznie filtrujesz, sortujesz albo łączysz dane.
- Testuj migracje razem z danymi próbki, bo błędy schematu wychodzą później niż błędy w kodzie aplikacji.
W praktyce to właśnie tutaj najłatwiej popełnić kosztowne błędy: za dużo kolumn w jednej tabeli, za mało ograniczeń albo ślepa wiara, że ORM sam optymalizuje wszystko. Dobrze ułożony projekt nie musi być przesadnie skomplikowany, ale musi być spójny od początku.
Na co patrzę, zanim uznam projekt za gotowy
Jeżeli miałbym zostawić tylko kilka praktycznych kryteriów, byłyby to te poniżej. W moim doświadczeniu one najszybciej pokazują, czy projekt jest naprawdę uporządkowany, czy tylko wygląda dobrze na diagramie:
- Czy każda tabela ma jeden, jasny klucz główny?
- Czy relacje są opisane kluczami obcymi i ograniczeniami, a nie tylko „umową w zespole”?
- Czy najczęstsze zapytania mają sensowne indeksy?
- Czy wiem, które dane są krytyczne dla spójności, a które służą głównie do odczytu?
- Czy schemat da się rozwinąć bez przepisywania połowy aplikacji?
Jeżeli na te pytania odpowiadasz pewnie, relacyjny model jest bardzo dobrym fundamentem. Jeśli odpowiedzi są niejasne, problem zwykle nie leży w samej technologii, tylko w projekcie danych, który trzeba dopracować zanim zacznie boleć w produkcji.