
Amazon Redshift to hurtownia danych w chmurze, która rozwiązuje zupełnie inny problem niż klasyczna baza aplikacyjna: ma szybko analizować duże zbiory danych, obsługiwać raporty, dashboardy i zapytania przekrojowe bez duszenia się przy większym wolumenie. W tym artykule pokazuję, kiedy taka platforma ma sens, jak działa od strony SQL i infrastruktury oraz gdzie najłatwiej popełnić kosztowny błąd przy wdrożeniu.
Najkrócej mówiąc, to platforma do analityki danych, a nie zamiennik bazy transakcyjnej
- Redshift najlepiej sprawdza się przy danych od kilkuset GB wzwyż, gdy liczy się szybka analityka i raportowanie.
- Wydajność opiera się na MPP, kolumnowym składowaniu i kompresji, więc zapytania czytają mniej danych niż w typowej bazie OLTP.
- Serverless wybieram przy zmiennym obciążeniu, a provisioned, gdy ruch jest przewidywalny i wymaga większej kontroli.
- SQL pozostaje centralnym interfejsem, a dane można ładować z Amazon S3 lub odpytywać bezpośrednio jako data lake.
- Najczęstsze problemy to zły dobór trybu pracy, nieuwzględnienie kosztów i próba używania hurtowni jak bazy transakcyjnej.
Patrzę na Redshift jak na warstwę analityczną, która porządkuje dane na poziomie całej organizacji. AWS pozycjonuje tę usługę dla zbiorów od kilkuset gigabajtów do petabajta i więcej, więc to rozwiązanie dla środowisk, w których raportowanie przestaje być dodatkiem, a staje się jednym z głównych elementów pracy zespołu. Najwięcej sensu ma tam, gdzie trzeba łączyć wiele źródeł, liczyć agregacje i udostępniać wyniki biznesowi szybko, bez ręcznego kombinowania przy każdym raporcie.
W praktyce wybieram taką hurtownię, gdy:
- dane pochodzą z wielu systemów i trzeba je skleić w jeden model analityczny,
- dashboardy mają odpowiadać szybko mimo dużej liczby rekordów,
- zespół pracuje głównie w SQL i narzędziach BI,
- potrzebuję środowiska do analiz przekrojowych, a nie do tysięcy małych zapisów na sekundę.
Jeśli zadaniem jest obsługa koszyka zakupowego, logowania użytkowników albo innych transakcji operacyjnych, to nie jest właściwy kierunek. Właśnie dlatego warto najpierw zrozumieć, co dzieje się pod spodem, bo od tego zależy i wydajność, i koszt.
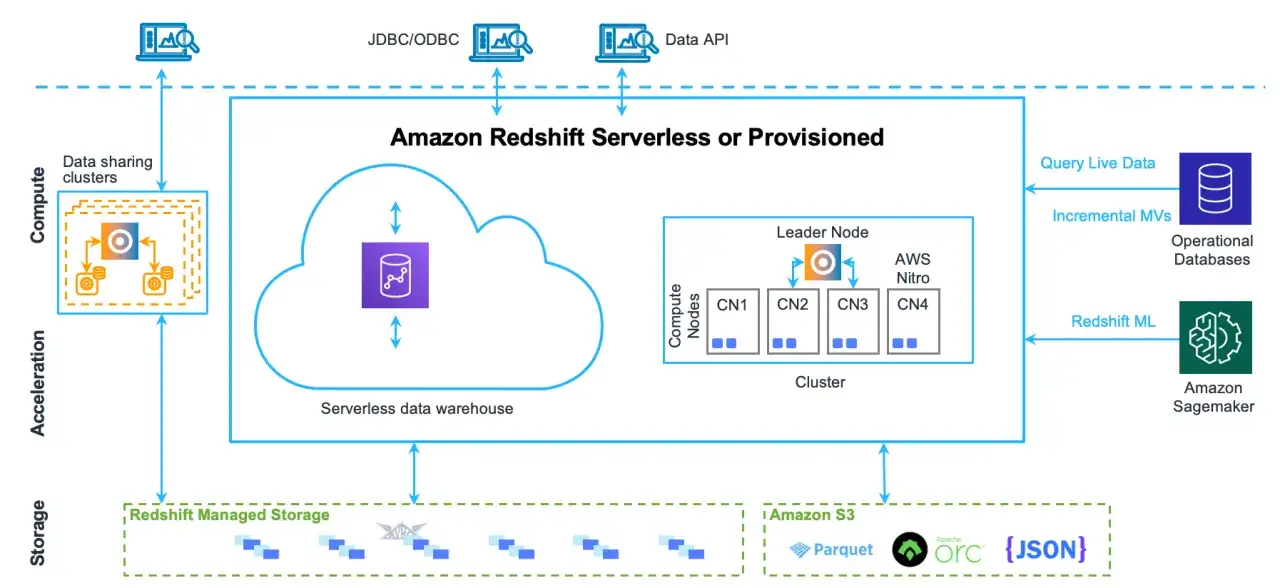
Jak działa architektura i dlaczego zapytania są szybkie
To, co odróżnia Redshift od zwykłej bazy relacyjnej, to sposób przechowywania i przetwarzania danych. Usługa łączy massively parallel processing, kolumnowe składowanie i agresywną kompresję, dzięki czemu czyta tylko te fragmenty danych, które są potrzebne do konkretnego zapytania. Mniej odczytów z dysku oznacza mniej I/O, a mniej I/O zwykle oznacza krótszy czas odpowiedzi.
Najważniejsze elementy tej układanki są proste, ale robią różnicę:
- Kolumnowe składowanie sprawia, że zapytanie analizujące kilka pól nie musi ładować całych wierszy.
- MPP rozdziela pracę między wiele węzłów, więc duże agregacje nie czekają na jeden procesor.
- Kompresja zmniejsza rozmiar danych i przyspiesza odczyt, bo mniej informacji trzeba pobrać z pamięci masowej.
- Ładowanie równoległe pozwala zasysać dane z plików w S3 szybciej niż przy ręcznych, liniowych importach.
W dokumentacji AWS wprost widać, że Redshift został zaprojektowany do analityki, a nie do drobnych transakcji. To wyjaśnia, dlaczego raport miesięczny liczony na milionach wierszy potrafi działać zaskakująco sprawnie, podczas gdy próba użycia go jak aplikacyjnej bazy operacyjnej zwykle kończy się frustracją. I właśnie stąd już bardzo blisko do pytania, w jakim trybie pracy najlepiej go uruchomić.
Serverless czy klaster provisioned
To jest moment, w którym wiele zespołów podejmuje złą decyzję, bo wybiera tryb uruchomienia pod wpływem wygody, a nie pod wpływem charakteru obciążenia. Ja upraszczam to tak: Serverless biorę wtedy, gdy ruch faluje i nie chcę myśleć o pojemności, a provisioned wtedy, gdy obciążenie jest stałe i potrzebuję większej kontroli nad środowiskiem.
| Cecha | Serverless | Provisioned |
|---|---|---|
| Obsługa infrastruktury | Automatycznie przydziela i skaluje moc obliczeniową w kilka sekund | Sam wybierasz rozmiar klastra i zarządzasz nim świadomie |
| Rozliczanie | Płacisz tylko wtedy, gdy hurtownia jest używana | Płacisz za działający klaster niezależnie od chwilowego ruchu |
| Najlepsze zastosowanie | Zmienne obciążenie, ad hoc analityka, nieregularne dashboardy | Stały ruch, przewidywalne raporty, większa potrzeba strojenia |
| Jednostka i kontrola | Praca opiera się o RPUs; 1 RPU to 16 GB pamięci | Większa kontrola nad wielkością i parametrami klastra |
| Odzyskiwanie | Punkty odzyskiwania są tworzone co 30 minut i przechowywane 24 godziny | Typowe mechanizmy backupu i zarządzania klastrem |
Serverless lubię za niski próg wejścia, ale nie traktuję go jak magicznie tańszej opcji. AWS podaje, że rezerwacje Serverless mogą obniżyć koszty compute nawet o 24%, więc przy bardziej stabilnym wykorzystaniu też da się to sensownie zoptymalizować. Provisioned z kolei wygrywa tam, gdzie ważna jest przewidywalność, a zespół chce mieć pełną świadomość, ile mocy ma do dyspozycji każdego dnia.
Gdy już wiadomo, jaką formę pracy wybrać, trzeba zobaczyć, jak wygląda codzienna praca z SQL i danymi. I tu Redshift jest bliższy temu, co zna większość analityków, niż mogłoby się wydawać.
Jak wygląda praca z SQL i danymi w praktyce
Najwygodniejsze w Redshift jest to, że nie wymaga nauki zupełnie nowego języka. To nadal SQL, tylko zoptymalizowany pod analitykę, więc typowy zespół BI albo data team może wejść w tę usługę bez przebudowy całego sposobu pracy. Z mojej perspektywy największa wartość pojawia się wtedy, gdy od razu ustalam prosty model: dane surowe lądują w strefie wejściowej, potem są przekształcane, a na końcu trafiają do warstwy raportowej.
SELECT date_trunc('month', order_date) AS miesiac,
SUM(revenue) AS przychod
FROM fact_orders
GROUP BY 1
ORDER BY 1;To przykład zwykłej agregacji, ale właśnie takie zapytania stanowią większość analitycznej pracy. W Redshift dobrze działają zestawienia po czasie, porównania segmentów klientów, rankingi produktów i raporty łączące wiele tabel wymiarów z tabelami faktów.
W praktyce najczęściej korzysta się z trzech dróg pracy z danymi:
- ładowanie wsadowe z plików w Amazon S3 przez komendę COPY,
- zapytania do data lake w S3 bez przenoszenia wszystkiego do tabel wewnętrznych,
- łączenie klasycznych tabel z danymi półstrukturalnymi, gdy źródła generują JSON lub podobne formaty.
Warto też pamiętać, że Redshift dobrze współpracuje z narzędziami BI i typowymi driverami do SQL, więc nie trzeba budować osobnego ekosystemu tylko po to, by uruchomić dashboardy. Największa praktyczna przewaga pojawia się jednak wtedy, gdy dane nie są trzymane w jednej sztywnej strukturze, lecz możesz sięgać do szerszego data lake. I właśnie tutaj warto uczciwie spojrzeć na koszty oraz ograniczenia.
Koszty, ograniczenia i typowe błędy, które widzę najczęściej
Najdroższe błędy przy wdrożeniach analitycznych rzadko wynikają z samej usługi. Zwykle problemem jest złe założenie: ktoś zakłada, że hurtownia danych będzie zachowywać się jak baza operacyjna, albo że billing będzie prosty, bo „przecież to tylko SQL”. W praktyce warto patrzeć na koszt jak na sumę kilku składników, a nie jak na jedną etykietę cenową.
| Co podnosi koszt | Jak to kontrolować |
|---|---|
| Zbyt duża moc obliczeniowa na start | Startuj od realnego minimum i mierz zachowanie najważniejszych zapytań |
| Skoki ruchu w dashboardach | Rozważ Serverless albo świadomie konfiguruj skalowanie współbieżności |
| Ładowanie danych bez porządku i modelu | Ustal strefy danych, role tabel i prosty standard nazw |
| Próba używania hurtowni jak bazy transakcyjnej | Trzymaj OLTP w osobnym systemie, a Redshift zostaw do analityki |
| Dane i bucket S3 w różnych regionach | Sprawdź ograniczenia regionalne, zwłaszcza przy Spectrum i COPY |
Jest też kilka ograniczeń, które potrafią zaskoczyć dopiero po starcie. Dla przykładu, Redshift Spectrum działa w tym samym regionie co bucket S3, a przy niektórych scenariuszach concurrency scaling nie obsłuży wszystkich typów zapytań i tabel. Do tego dochodzi prosta zasada, którą powtarzam zespołom: jeśli koszt ma być przewidywalny, to trzeba przewidywalnie projektować też model danych, a nie tylko sam klaster.
Najczęstsze pomyłki sprowadzają się do czterech rzeczy: zbyt szybkiego wyboru trybu pracy, braku monitoringu kosztów, mieszania analityki z operacjami oraz zbyt luźnego podejścia do struktury danych. To prowadzi już wprost do pytania, jak przygotować pierwsze wdrożenie tak, żeby nie wpaść w te same pułapki.
Jak przygotować pierwsze wdrożenie, żeby nie przepalić budżetu
Gdybym miał zacząć od zera, najpierw nie wybierałbym narzędzia, tylko spisałbym sposób użycia. Zanim uruchomisz środowisko, odpowiedz sobie na pięć prostych pytań: ile danych masz dziś, jak szybko rosną, które zapytania są krytyczne biznesowo, ile osób będzie równocześnie korzystać z raportów i czy ruch jest równy, czy raczej falujący.
Potem robię bardzo praktyczną checklistę:
- ustalam, które dane mają trafiać do hurtowni, a które zostają w systemach operacyjnych,
- rozróżniam raporty cykliczne od analiz ad hoc, bo one obciążają platformę inaczej,
- decyduję, czy lepszy będzie model Serverless, czy provisioned,
- przygotowuję prostą strefę lądowania danych w S3 i zasady nazewnictwa,
- ustawiam monitoring zużycia, czasu odpowiedzi i kolejki zapytań.
Jeśli zespół pracuje w Pythonie, Redshift dobrze wpisuje się w pipeline’y ETL i walidację danych, bo SQL może zostać warstwą analityczną, a Python warstwą przygotowania i automatyzacji. To zwykle daje lepszy efekt niż próba zrobienia wszystkiego jednym narzędziem. Dla mnie najważniejszy wniosek jest prosty: ta hurtownia ma sens wtedy, gdy traktujesz ją jak platformę do analityki, a nie jak kolejną zwykłą bazę, i gdy od początku pilnujesz modelu danych, kosztów oraz charakteru obciążenia.