Gdy pytamy, co to jest baza danych, chodzi nie o abstrakcyjną definicję, lecz o coś, co stoi za logowaniem do aplikacji, historią zamówień i każdym systemem, który musi przechowywać dane bez chaosu. W tym artykule pokazuję, czym jest baza danych, jak działa relacyjny model, po co w tym wszystkim SQL i kiedy warto zacząć od SQLite, a kiedy sięgnąć po PostgreSQL lub MySQL.
Najważniejsze informacje w skrócie
- Baza danych to uporządkowany zbiór danych zarządzany przez system DBMS, który pozwala je zapisywać, wyszukiwać, aktualizować i zabezpieczać.
- W relacyjnym modelu dane trafiają do tabel z wierszami i kolumnami, a powiązania między tabelami są kluczowe dla sensownej pracy.
- SQL służy do wykonywania zapytań i operacji na danych, dlatego to podstawowy język w świecie relacyjnych baz danych.
- Dla małych projektów i nauki często wystarcza SQLite, a w aplikacjach produkcyjnych częściej wybiera się PostgreSQL albo MySQL.
- Najczęstsze błędy to duplikowanie danych, brak kluczy, zła struktura tabel i pomijanie indeksów lub kopii zapasowych.
Czym jest baza danych w praktyce
Najprościej mówiąc, baza danych to miejsce, w którym dane są nie tylko przechowywane, ale też porządkowane i chronione przed chaosem. Sama lista rekordów jeszcze nie wystarcza. Potrzebny jest mechanizm, który wie, jak je dodać, jak odszukać konkretny wpis, jak powiązać go z innymi danymi i jak nie dopuścić do tego, żeby kilka osób nadpisało sobie nawzajem te same informacje.
W praktyce baza danych pracuje zawsze razem z systemem zarządzania bazą danych (DBMS). To on pilnuje struktury, uprawnień, transakcji i integralności danych. Jeśli myślisz o aplikacji sklepowej, to baza przechowuje użytkowników, produkty, zamówienia i płatności, a DBMS pilnuje, żeby zamówienie nie istniało bez klienta i bez pozycji w koszyku.
Taki podział ma ogromne znaczenie: dane bez organizacji są tylko zbiorem informacji, a dobrze zaprojektowana baza pozwala z nich szybko korzystać. I właśnie dlatego warto od razu przejść do tego, jak wygląda najpopularniejszy model organizacji danych.
Jak działa relacyjny model danych
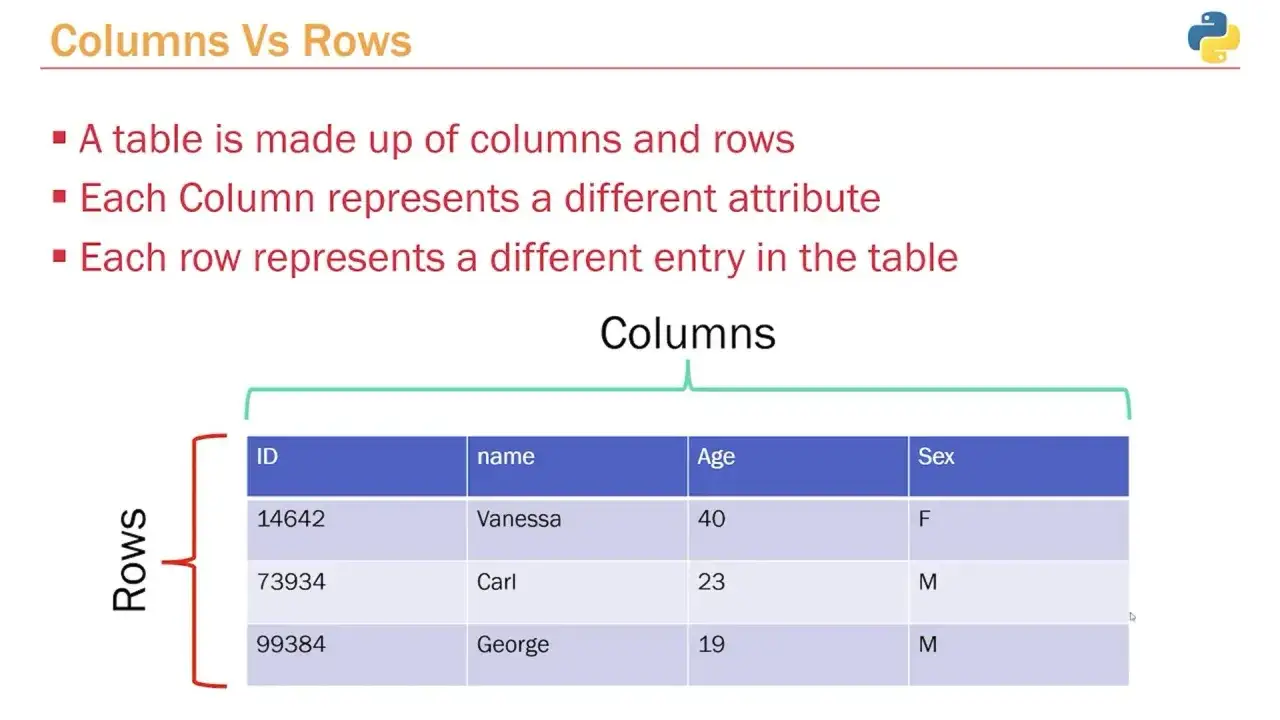
W większości aplikacji spotkasz relacyjną bazę danych. Dane są w niej zapisywane w tabelach, czyli strukturach z wierszami i kolumnami. Każdy wiersz to zwykle jeden rekord, na przykład jeden klient albo jedno zamówienie, a każda kolumna opisuje konkretną cechę, na przykład imię, adres e-mail albo datę zakupu.
To właśnie tu pojawiają się pojęcia, które początkujący często mieszają: klucz główny identyfikuje rekord jednoznacznie, a klucz obcy łączy jedną tabelę z drugą. Dzięki temu nie trzeba kopiować całego opisu klienta do każdego zamówienia. Wystarczy powiązać zamówienie z odpowiednim identyfikatorem klienta. Tak działa normalizacja danych w praktyce: mniej duplikacji, mniej błędów, łatwiejsze aktualizacje.Jeśli masz w głowie arkusz kalkulacyjny, to jest dobry punkt startu, ale relacyjna baza idzie krok dalej. Arkusz dobrze znosi proste listy, natomiast baza danych daje relacje, reguły i kontrolę spójności. Z tego punktu łatwo przejść do pytania, jakie rodzaje baz spotyka się najczęściej.
Jakie są główne typy baz danych i kiedy mają sens
Nie każda baza działa tak samo. W praktyce najczęściej porównuje się rozwiązania relacyjne i nierelacyjne. Różnica nie sprowadza się do mody technologicznej. Chodzi o sposób przechowywania danych, ich elastyczność i to, jak bardzo aplikacja potrzebuje ścisłej struktury.
| Typ bazy | Jak przechowuje dane | Najmocniejsza strona | Kiedy wybieram ją najczęściej |
|---|---|---|---|
| Relacyjna | Tabele, wiersze, kolumny, relacje | Spójność i wygodne zapytania SQL | Aplikacje biznesowe, systemy transakcyjne, e-commerce, panele administracyjne |
| Dokumentowa | Dokumenty, zwykle w formacie JSON | Elastyczny schemat | Projekty, w których struktura danych zmienia się często |
| Klucz-wartość | Pary klucz i wartość | Bardzo szybki dostęp do prostych danych | Cache, sesje, liczniki, proste szybkie odczyty |
| Grafowa | Węzły i połączenia | Relacje złożone i wieloetapowe | Rekomendacje, sieci powiązań, analiza zależności |
Na początku łatwo uznać, że bardziej elastyczna baza jest automatycznie lepsza. W praktyce nie. Jeśli dane są dobrze ustrukturyzowane, relacyjny model zwykle daje mniej problemów, lepszą kontrolę i prostsze raportowanie. Nierelacyjne rozwiązania wygrywają tam, gdzie schemat zmienia się często albo liczy się specyficzny sposób dostępu do danych. To prowadzi naturalnie do pytania o SQL, bo właśnie on najczęściej spina te decyzje w codziennej pracy.
Po co jest SQL i co naprawdę warto umieć na start
SQL to język, którym rozmawia się z relacyjną bazą danych. Nie służy do dekorowania danych, tylko do ich tworzenia, odczytu, aktualizacji i usuwania. Jeśli ktoś zaczyna pracę z bazami, wystarczy zrozumieć cztery podstawowe operacje CRUD: Create, Read, Update i Delete.
- SELECT pobiera dane z tabel.
- INSERT dodaje nowe rekordy.
- UPDATE zmienia istniejące rekordy.
- DELETE usuwa dane, których już nie potrzebujesz.
W praktyce najwięcej wartości daje jednak nie samo zapamiętanie poleceń, lecz zrozumienie, jak pisać zapytania z warunkami, filtrowaniem i łączeniem tabel. To właśnie JOIN odróżnia proste skrypty od sensownej pracy na danych. Dzięki niemu możesz połączyć informacje o klientach z zamówieniami, produktami albo płatnościami bez kopiowania danych do każdej tabeli osobno.
Jeśli pracujesz z Pythonem, to ten etap jest szczególnie ważny. SQLite daje szybki start, PostgreSQL dobrze sprawdza się w aplikacjach rosnących wraz z ruchem, a biblioteki takie jak sqlite3, psycopg2 czy SQLAlchemy pozwalają wygodnie łączyć kod z bazą. Dla kogoś uczącego się backendu to jeden z najbardziej praktycznych obszarów nauki.
Najczęstsze błędy przy projektowaniu i używaniu bazy
Największe problemy nie wynikają z samej technologii, tylko z kiepskiego projektu. Widziałem wiele baz, które na początku działały poprawnie, a po kilku miesiącach zaczynały spowalniać albo produkować błędne dane. Zwykle winne są te same schematy.
- Duplikowanie informacji w wielu tabelach zamiast przechowywania ich w jednym miejscu.
- Brak kluczy i ograniczeń, przez co baza dopuszcza niespójne dane.
- Zbyt szerokie tabele, które mieszają różne obszary biznesowe w jednej strukturze.
- Brak indeksów tam, gdzie zapytań jest dużo i trzeba przyspieszyć odczyt.
- Brak kopii zapasowych, co zamienia zwykłą awarię w kosztowny incydent.
- Traktowanie Excela jak bazy danych w projekcie, który już dawno urósł poza prostą listę.
Ja zawsze powtarzam jedną rzecz: dobra baza danych nie musi być skomplikowana, ale musi być konsekwentna. Nawet niewielki projekt zyska, jeśli od początku zadbasz o spójne nazwy, relacje między tabelami i podstawową walidację danych. To właśnie te detale decydują o tym, czy system da się rozwijać bez ciągłych poprawek, a kiedy są już pod kontrolą, łatwiej wybrać pierwsze narzędzie bez przesadnej komplikacji.
Jak zacząć pracę z bazą danych bez zbędnej komplikacji
Jeśli dopiero uczysz się tematu, nie zaczynaj od najcięższego narzędzia. W małym projekcie albo podczas nauki najlepiej sprawdza się SQLite, bo nie wymaga osobnego serwera i działa bardzo dobrze z Pythonem. Gdy projekt zaczyna obsługiwać wielu użytkowników, rośnie liczba zapisów albo potrzebujesz lepszej kontroli nad uprawnieniami, naturalnym krokiem staje się PostgreSQL lub MySQL.
Ja zwykle polecam taki porządek nauki: najpierw tabele i relacje, potem podstawowe zapytania SQL, następnie indeksy, transakcje i backup. Dopiero na końcu warto wejść głębiej w optymalizację. To oszczędza czas, bo pozwala zbudować solidny model danych, zanim pojawi się presja wydajnościowa.
Jeśli mam zostawić Ci jedną praktyczną wskazówkę, to taką: zanim zapiszesz pierwszą tabelę, narysuj, jakie dane naprawdę muszą być powiązane. Ten prosty krok często ujawnia błędy, które później kosztują najwięcej. A kiedy struktura jest już sensowna, SQL i Python stają się narzędziami do pracy, a nie źródłem frustracji.