W SQL i projektowaniu relacyjnych baz normalizacja danych bywa rozumiana dwojako: jako porządkowanie struktury tabel oraz jako ujednolicanie zapisów w kolumnach. W praktyce oba podejścia służą temu samemu celowi: mniej duplikatów, mniej błędów i prostsze zapytania. Poniżej pokazuję, jak rozpoznać właściwy przypadek, jak przejść przez 1NF, 2NF i 3NF oraz kiedy lepiej postawić na czyszczenie wartości niż na przebudowę całego modelu.
Najważniejsze fakty, które warto mieć pod ręką
- W relacyjnych bazach najczęściej chodzi o rozdzielenie danych na logiczne tabele i usunięcie nadmiarowości.
- 1NF usuwa grupy powtarzalne, 2NF eliminuje zależności częściowe, a 3NF usuwa zależności przechodnie.
- W systemach transakcyjnych 3NF jest zwykle rozsądnym punktem startu, a nie ślepym celem absolutnym.
- W SQL da się też ujednolicić wartości w kolumnach: tekst, daty, numery telefonów, kwoty i puste pola.
- Denormalizacja ma sens w raportach i hurtowniach, ale powinna być świadomym kompromisem, nie skrótem z przypadku.
Co naprawdę oznacza normalizacja w bazie danych
Jeżeli patrzę na ten termin w kontekście SQL, to najczęściej oznacza on uporządkowanie modelu relacyjnego tak, aby każda informacja była przechowywana tam, gdzie ma sens biznesowy. Zamiast trzymać w jednej tabeli wszystko naraz, rozdziela się klientów, zamówienia, pozycje zamówień, produkty i inne encje. Dzięki temu jedna zmiana nie rozjeżdża pół bazy.
Warto od razu rozróżnić dwa znaczenia. Pierwsze to klasyczna normalizacja schematu, czyli praca na postaciach normalnych. Drugie to ujednolicanie samych wartości, na przykład zamiana różnych zapisów dat, nazw czy numerów telefonów na jeden format. W praktyce oba tematy spotykają się w jednym projekcie, ale rozwiązują trochę inne problemy.
Ja zwykle tłumaczę to tak: jeśli problemem jest duplikacja i zależności między tabelami, mówimy o normalizacji modelu. Jeśli problemem jest bałagan w pojedynczej kolumnie, chodzi raczej o czyszczenie i standaryzację danych. To rozróżnienie przydaje się od razu, bo od niego zależy, czy piszesz nowe `CREATE TABLE`, czy raczej zapytanie transformujące import. Z tej różnicy wynika też, dlaczego normalizacja nie zawsze wygląda tak samo, więc następny krok to spojrzenie na korzyści i kompromisy.
Dlaczego dobrze zaprojektowane tabele oszczędzają problemy
Największa zaleta normalizacji jest bardzo praktyczna: mniej miejsc, w których można wprowadzić sprzeczne dane. Jeśli adres klienta istnieje tylko w jednej tabeli, nie aktualizujesz go w pięciu rekordach zamówień. Jeśli nazwa produktu jest przechowywana oddzielnie od pozycji zamówienia, nie ryzykujesz literówek w połowie historii sprzedaży.
- Mniej anomalii wstawiania - nie musisz wpisywać danych, których jeszcze nie ma sensu wiązać z transakcją.
- Mniej anomalii aktualizacji - jedna zmiana wystarcza zamiast serii ręcznych poprawek.
- Mniej anomalii usuwania - skasowanie jednego rekordu nie usuwa przypadkiem ważnej informacji o kliencie lub produkcie.
- Lepsza spójność - klucze główne, obce i ograniczenia `UNIQUE` robią realną robotę, a nie tylko „ładnie wyglądają” w diagramie.
Jest jednak druga strona. Im bardziej rozbijasz dane na osobne tabele, tym więcej joinów w zapytaniach i tym większa złożoność modelu. W aplikacjach transakcyjnych to zwykle nie problem, ale w raportach lub widokach analitycznych już tak. Dlatego normalizacja nie jest religią. To kompromis między spójnością, prostotą aktualizacji i wygodą odczytu. Żeby ten kompromis był świadomy, trzeba znać postacie normalne, bo to one wyznaczają granice porządkowania.
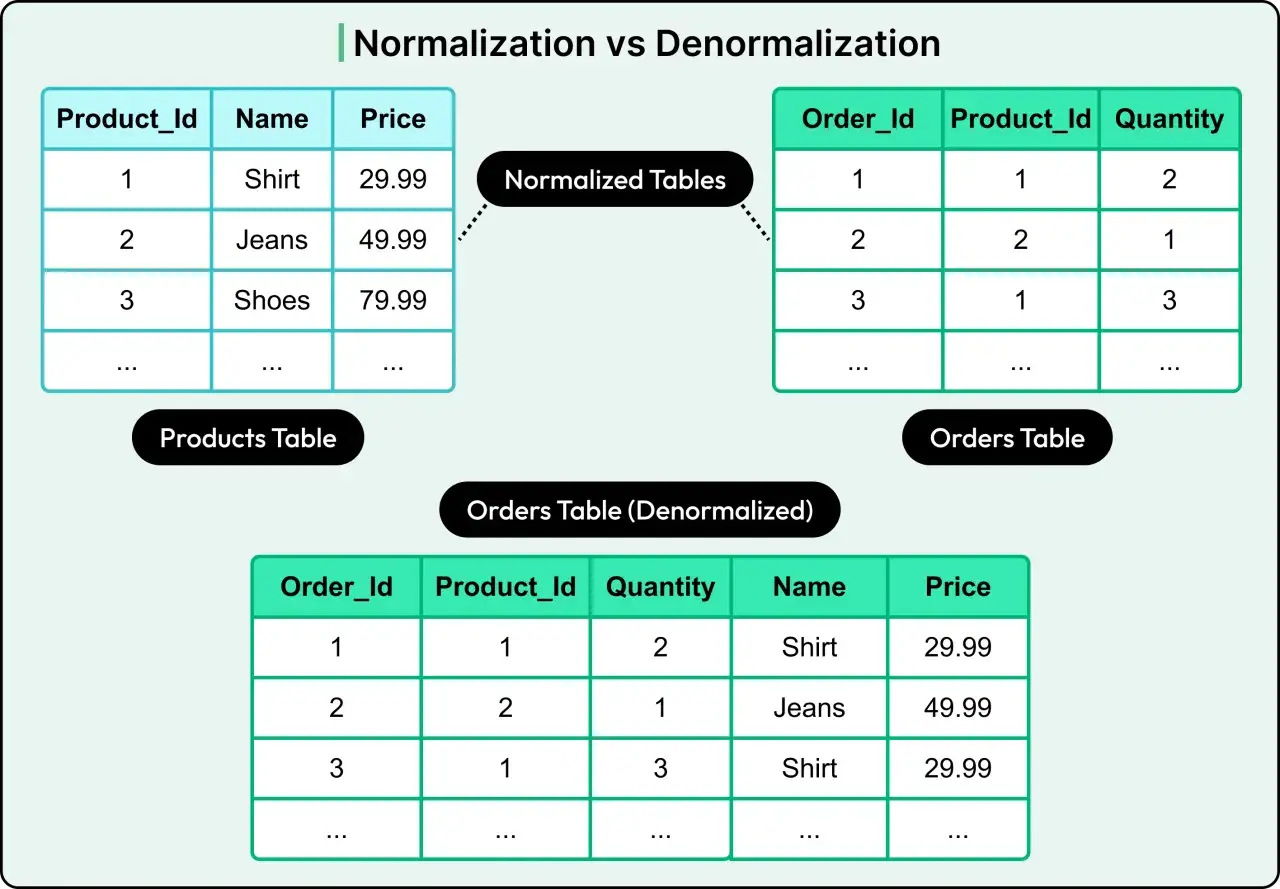
Jak wyglądają 1NF, 2NF i 3NF w praktyce
Najłatwiej zrozumieć ten temat na prostym modelu zamówień. Zanim dojdzie do rozbicia tabel, dobrze jest wiedzieć, co dokładnie poprawia każdy poziom i kiedy można uznać model za wystarczająco uporządkowany.
| Postać normalna | Co porządkuje | Po co to robisz | Na co uważać |
|---|---|---|---|
| 1NF | Każda komórka ma jedną wartość, brak grup powtarzalnych | Tabela staje się czytelna i łatwiejsza do filtrowania | Nie upychaj list w jednej kolumnie |
| 2NF | Atrybuty zależą od całego klucza złożonego | Usuwasz zależności częściowe | Ważne przy tabelach łączących wiele encji |
| 3NF | Atrybuty niekey nie zależą od innych niekey | Usuwasz zależności przechodnie | To najczęstszy rozsądny cel w systemach OLTP |
| BCNF | Każdy wyznacznik jest kandydatem na klucz | Jeszcze mocniej ograniczasz wyjątki | Nie zawsze potrzebna, często wystarcza 3NF |
W praktyce 1NF mówi: jedna komórka, jedna wartość. 2NF dopowiada: jeśli tabela ma klucz złożony, każdy atrybut ma zależeć od całego klucza, a nie tylko od jego części. 3NF usuwa sytuacje, w których jedna kolumna jest pośrednio wyznaczana przez inną niekluczową kolumnę, na przykład adres klienta zależny od nazwy klienta, a nie od samego zamówienia.
Dla aplikacji CRUD i systemów transakcyjnych 3NF jest zwykle dobrym punktem startowym. Nie oznacza to, że trzeba natychmiast rozbijać każdy możliwy byt do granic możliwości. Jeśli model jest już spójny, a zapytania są zrozumiałe, dalsze „dosuszanie” struktury często przynosi mniejszy zysk niż się wydaje. Na tym etapie najlepiej widać to na konkretnym przykładzie SQL, więc przechodzę od teorii do tabel.
Przykład przejścia z tabeli płaskiej do modelu relacyjnego
Załóżmy, że importujesz sprzedaż z arkusza albo z pliku CSV i dostajesz jedną tabelę z wszystkim naraz. Na pierwszy rzut oka jest wygodnie, ale bardzo szybko zaczynają się problemy z powtórzonymi danymi.
CREATE TABLE orders_flat (
order_id INT,
customer_name VARCHAR(200),
customer_email VARCHAR(255),
product_name VARCHAR(200),
quantity INT,
unit_price DECIMAL(10,2),
order_date DATE
);W takim układzie nazwa klienta, adres e-mail i nazwa produktu powtarzają się w wielu wierszach. Jeśli klient zmieni e-mail, musisz poprawić wszystkie rekordy. Jeśli nazwa produktu zostanie wpisana raz jako „Monitor 27”, a raz jako „monitor 27”, raport od razu traci jakość.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
full_name VARCHAR(200) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
CONSTRAINT fk_orders_customers
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
CREATE TABLE order_items (
order_item_id INT PRIMARY KEY,
order_id INT NOT NULL,
product_name VARCHAR(200) NOT NULL,
quantity INT NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
CONSTRAINT fk_order_items_orders
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Ten podział nie jest sztuką dla sztuki. `customers` przechowuje dane osoby, `orders` sam fakt zamówienia, a `order_items` pozycje zamówienia. Dzięki temu e-mail klienta jest zapisany raz, zamówienie ma własną historię, a pozycje mogą być analizowane niezależnie. Gdy potem pobierasz pełny widok, używasz joinów:
SELECT
o.order_id,
c.full_name,
c.email,
o.order_date,
oi.product_name,
oi.quantity,
oi.unit_price
FROM orders o
JOIN customers c ON c.customer_id = o.customer_id
JOIN order_items oi ON oi.order_id = o.order_id;Tu właśnie widać sens normalizacji: model zapisowy jest czystszy, a warstwa odczytu nadal może dać kompletny obraz. Jeżeli jednak problemem nie jest struktura tabel, tylko chaotyczny zapis wartości, trzeba sięgnąć po inny zestaw narzędzi, czyli ujednolicanie danych przy imporcie albo przed zapisem do tabel docelowych.
Jak ujednolicić format danych podczas importu
W wielu projektach to właśnie ten etap robi największą różnicę. Masz surowe dane z wielu źródeł: spacje na początku, różne wielkości liter, przecinki zamiast kropek, puste stringi zamiast `NULL` i numery telefonów zapisane na trzy sposoby. Sam model może być dobry, ale bez standaryzacji wartości zapytania nadal będą dawały przypadkowe wyniki.
Do takiego porządkowania zwykle używa się funkcji, które są dostępne w większości silników SQL, choć szczegóły składni różnią się między PostgreSQL, MySQL, SQL Server czy Oracle. Najczęściej przydają się:
| Cel | Typowe funkcje SQL | Przykład użycia |
|---|---|---|
| Usunięcie zbędnych spacji | `TRIM`, czasem `LTRIM` i `RTRIM` | Imiona, miasta, kody pocztowe |
| Ujednolicenie wielkości liter | `LOWER`, `UPPER` | E-maile, statusy, kategorie |
| Zmiana separatorów i znaków | `REPLACE`, czasem `REGEXP_REPLACE` | Numery telefonów, kwoty, identyfikatory |
| Konwersja typu | `CAST`, `CONVERT` | Tekst na liczbę, tekst na datę |
| Obsługa braków | `NULLIF`, `COALESCE` | Puste stringi, domyślne wartości |
SELECT
TRIM(LOWER(name_raw)) AS name_norm,
TRIM(email_raw) AS email_norm,
REGEXP_REPLACE(phone_raw, '[^0-9+]', '') AS phone_norm,
CAST(REPLACE(amount_raw, ',', '.') AS DECIMAL(10,2)) AS amount_norm,
COALESCE(NULLIF(country_raw, ''), 'PL') AS country_norm
FROM staging_orders;Najważniejsza praktyczna zasada brzmi: czyść dane w warstwie pośredniej, a nie bezpośrednio w tabeli produkcyjnej. Staging pozwala zachować surowy materiał, wrócić do błędnego importu i porównać efekty transformacji. To dużo bezpieczniejsze niż ręczne poprawianie rekordów na żywej bazie. Po takim uporządkowaniu warto jeszcze sprawdzić, gdzie zwykle popełnia się błędy, bo właśnie tam najłatwiej zniszczyć sens całej pracy.
Najczęstsze błędy i kiedy lepsza jest denormalizacja
Najczęstszy błąd to przesada. Ktoś rozdziela tabele tak mocno, że zwykłe pobranie listy zamówień zamienia się w łamigłówkę z pięcioma joinami. Drugi błąd to ignorowanie logiki biznesowej: projekt jest teoretycznie poprawny, ale nikt nie potrafi z niego wygodnie korzystać. Trzeci to mieszanie danych surowych z już oczyszczonymi, przez co nikt nie wie, która wersja jest prawdziwa.
- Za dużo tabel bez potrzeby - model staje się trudny w utrzymaniu, a nie lepszy.
- Przechowywanie danych pochodnych bez reguł - suma, status czy nazwa wyliczana powinny mieć jasne źródło.
- Brak indeksów na kluczach obcych - poprawna struktura nie zrekompensuje słabej wydajności odczytu.
- Pomijanie constraintów - bez `NOT NULL`, `UNIQUE` i `FOREIGN KEY` model szybko traci spójność.
- Brak rozdziału warstw - import, staging i tabela docelowa nie powinny być tym samym miejscem.
Ja traktuję denormalizację jako świadomy kompromis, nie jako antywzorzec. W hurtowniach danych, dashboardach i raportach zbiorczych bywa wręcz rozsądna, bo skraca czas odczytu i upraszcza analitykę. Jeżeli masz miliony wierszy i bardzo częste zapytania agregujące, czasem lepiej przechować gotowe wartości niż liczyć wszystko za każdym razem. Trzeba jednak wiedzieć, dlaczego to robisz, bo bez tego łatwo pomylić przyspieszenie z chaosem. Skoro to już jasne, zostaje praktyczny plan działania na start.
Bezpieczny plan na pierwszy audyt
Jeżeli mam zacząć od zera, nie przebudowuję całej bazy naraz. Najpierw robię mały audyt: sprawdzam, gdzie faktycznie powtarzają się dane, które kolumny są zależne od siebie i które zapytania generują najwięcej problemów. Dopiero potem decyduję, czy chodzi o przebudowę schematu, czy tylko o transformację wartości.
- Wybierz jedną tabelę, która sprawia najwięcej kłopotów.
- Rozpisz encje i usuń powtarzalne grupy danych.
- Sprawdź, czy każda kolumna zależy od właściwego klucza.
- Oddziel dane surowe od danych oczyszczonych.
- Dodaj ograniczenia integralności i sprawdź, czy zapytania dalej działają poprawnie.
- Porównaj liczbę duplikatów, błędów i wyjątków przed oraz po zmianie.
Jeżeli twoim celem jest przede wszystkim normalizacja danych w sensie ujednolicenia wartości, zacznij od stagingu i prostych transformacji SQL. Jeżeli problem leży w strukturze relacyjnej, pracuj przez postacie normalne i nie bój się zostawić denormalizacji tam, gdzie naprawdę służy wydajności. W dobrze prowadzonym projekcie te dwa podejścia nie konkurują ze sobą, tylko rozwiązują różne warstwy tego samego problemu.