Nowoczesny backend coraz rzadziej projektuje się jako aplikację przywiązaną do jednego serwera i ręcznych wdrożeń. Podejście cloud native zakłada, że system ma korzystać z automatyzacji, kontenerów, skalowania i obserwowalności, a nie tylko „działać w chmurze”. W praktyce chodzi o to, jak budować usługę tak, żeby była odporna na awarie, łatwa do rozwijania i sensownie zarządzana przez DevOps.
Najkrócej mówiąc, chodzi o automatyzację, odporność i przewidywalne wdrożenia
- To nie jest zwykła migracja do chmury, tylko sposób projektowania aplikacji pod środowisko, które zmienia się dynamicznie.
- Najczęściej w grę wchodzą kontenery, orkiestracja, konfiguracja deklaratywna i dobre monitorowanie.
- Największą różnicę robią automatyczne wdrożenia, szybki rollback i jasne granice między usługami.
- Nie każdy system musi od razu iść w mikroserwisy, ale każdy potrzebuje spójnych zasad operacyjnych.
- Bez observability taki model szybko zamienia się w zgadywanie, a nie w inżynierię.
Co to naprawdę znaczy w backendzie i DevOps
Jeśli upraszczam definicję, to nie chodzi o „przeniesienie serwera do chmury”, tylko o zbudowanie systemu, który wykorzystuje jej dynamikę: szybkie uruchamianie instancji, elastyczne skalowanie, deklaratywną konfigurację i łatwą rekonfigurację bez ręcznych operacji. W podejściu natywnym dla chmury aplikacja jest projektowana tak, by środowisko mogło się zmieniać, a nie żeby ono samo było stałe. Jak ujmuje to CNCF, ważne są m.in. kontenery, mikroserwisy, niezmienna infrastruktura i deklaratywne API.
W backendzie daje to bardzo konkretne skutki. Usługa nie zakłada już, że „jej serwer” będzie istnieć wiecznie, więc stan przenosi poza proces, konfigurację wyciąga z obrazu aplikacji, a wdrożenie traktuje jak powtarzalny mechanizm, nie rytuał wykonywany przez jedną osobę z dostępem SSH. Z perspektywy DevOps to zmiana sposobu pracy całego zespołu: mniej ręcznych wyjątków, więcej automatyzacji, testów i kontroli wersji także dla infrastruktury.
Ważne doprecyzowanie: ten model nie wymaga od razu mikroserwisów. Można go sensownie stosować również przy modularnym monolicie, jeśli tylko architektura jest przygotowana na automatyczne wdrażanie, skalowanie i obserwowanie zachowania aplikacji. To prowadzi do pytania, z czego taki system faktycznie się składa.
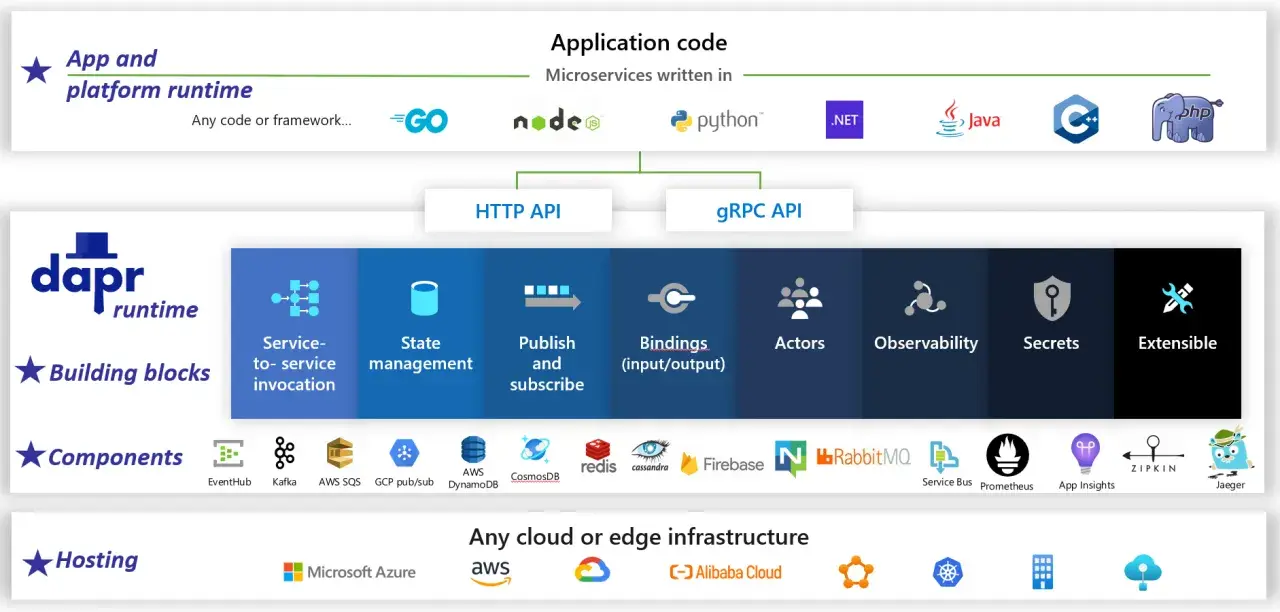
Z czego składa się nowoczesna architektura backendowa
W praktyce widzę zawsze te same klocki, nawet jeśli zespoły nazywają je inaczej. Różni się narzędziownia, ale sens pozostaje ten sam: aplikacja ma być łatwa do uruchomienia, bezpieczna w aktualizacji i widoczna operacyjnie.
Kontenery i niezmienna paczka wdrożeniowa
Kontener zamyka aplikację i jej zależności w jednym artefakcie, który można uruchomić w różnych środowiskach bez niespodzianek. To eliminuje część klasycznych problemów typu „u mnie działa”, bo obraz jest budowany raz, a potem promowany dalej przez pipeline. Sam kontener nie rozwiązuje jednak niczego automatycznie, jeśli w środku wciąż trzymasz konfigurację środowiskową, stan sesji albo ręczne skrypty startowe.
Orkiestracja i automatyczne skalowanie
W większych systemach bardzo często pojawia się Kubernetes, bo automatyzuje rozmieszczenie, restart, aktualizacje i skalowanie usług. Nie traktuję go jako obowiązku, ale jako narzędzie, które robi sens wtedy, gdy zespół naprawdę potrzebuje odporności na awarie i powtarzalności w dużej skali. Bez tego łatwo skończyć z kosztowną platformą, która rozwiązuje problem złożoności, ale jednocześnie sama ją zwiększa.
Konfiguracja i sekrety poza obrazem
Dobry obraz aplikacji nie powinien zawierać haseł, kluczy API ani danych zależnych od środowiska. Konfiguracja trafia do zmiennych środowiskowych, ConfigMap, menedżera sekretów albo innego mechanizmu zarządzania parametrami. Dzięki temu ten sam artefakt działa w testach, stagingu i produkcji, a różnice między środowiskami są jawne i wersjonowalne.
Przeczytaj również: ELK Stack - Jak analizować logi i uniknąć błędów?
Dane i stan, które nie mogą żyć w procesie
Jeśli aplikacja ma być łatwo odtwarzalna, jej stan musi być trzymany poza pojedynczą instancją procesu. Chodzi o bazę danych, cache, kolejki, obiektowe magazyny plików i inne systemy, które przetrwają restart poda. Z mojego doświadczenia to jeden z najczęstszych punktów, w którym projekty się wykładają: zespół buduje nowoczesny deployment, a potem trzyma sesje, pliki tymczasowe i krytyczne dane lokalnie, jakby nic się nie mogło zatrzymać.
Jeśli masz uporządkowane te warstwy, łatwiej przejść do pytania, jak wdrażać taki system bez robienia z zespołu poligonu eksperymentów.
Jak wygląda wdrożenie krok po kroku
Ja zwykle zaczynam od prostego celu: jedna usługa ma dać się zbudować, przetestować i wdrożyć bez ręcznej ingerencji. Dopiero potem dokładam kolejne warstwy, bo w tym obszarze zbyt szybkie „pełne wdrożenie” zwykle kończy się chaosem.
| Warstwa | Po co ją mieć | Co zyskuje zespół |
|---|---|---|
| Konteneryzacja | Jednolity artefakt uruchomieniowy | Mniej różnic między środowiskami |
| CI/CD | Automatyczny build, test i deploy | Szybsze i powtarzalne wydania |
| IaC i GitOps | Infrastruktura opisana w kodzie | Audyt, odtwarzalność i wersjonowanie |
| Observability | Metryki, logi i trace’y | Szybsza diagnoza problemów |
| Strategia wdrożeń | Rolling, blue-green albo canary | Mniejsze ryzyko przy publikacji zmian |
- Wybierz jeden serwis pilotażowy, najlepiej taki, który nie jest krytycznym centrum całego systemu.
- Dodaj health checks. Liveness probe sprawdza, czy proces żyje, a readiness probe mówi, czy aplikacja może przyjmować ruch.
- Ustal limity zasobów i strategię restartów, żeby aplikacja nie „zagłodziła” innych usług i umiała się podnieść po błędzie.
- Zbuduj pipeline, który robi testy, skan obrazu, publikację artefaktu i wdrożenie bez ręcznego klikania.
- Włącz metryki, logi i alerty zanim przełączysz ruch produkcyjny, bo inaczej nie będziesz wiedzieć, co się psuje.
- Przetestuj rollback oraz kontrolowane wdrożenia, zanim wpuścisz tam prawdziwy ruch.
To jest moment, w którym różnica między „ładnie brzmi” a „działa operacyjnie” staje się bardzo wyraźna. Gdy te elementy są spięte razem, sensownie można ocenić, gdzie taki model daje realny zwrot, a gdzie byłby tylko modnym nadmiarem.
Kiedy to daje największą przewagę, a kiedy lepiej nie przesadzać
Największy sens widzę tam, gdzie aplikacja ma częste zmiany, zmienny ruch albo wysokie wymagania dotyczące odporności. Wtedy automatyzacja wdrożeń, skalowanie i dobra telemetria nie są luksusem, tylko oszczędzają czas i ograniczają ryzyko.
| Scenariusz | Mój werdykt | Dlaczego |
|---|---|---|
| Nowy produkt SaaS z częstymi zmianami | Duża przewaga | Szybkie iteracje, łatwiejsze rollouty i lepsze dostosowanie do wzrostu ruchu |
| System z sezonowym lub skokowym ruchem | Bardzo duża przewaga | Skalujesz zasoby wtedy, gdy faktycznie są potrzebne |
| Krytyczny backend z wymaganiami dostępności | Duża przewaga | Lepsza odporność na awarie i prostsze odtwarzanie usług |
| Mały stabilny monolit | Umiarkowana przewaga | Prostszy stos może dać lepszy stosunek efektu do kosztu |
| Lifting istniejącej aplikacji bez zmian w kodzie | Niska przewaga | Przenosisz problem, ale nie zmieniasz modelu pracy systemu |
Najczęstszy błąd to utożsamianie wdrożenia do chmury z automatyczną modernizacją architektury. Możesz mieć aplikację postawioną w chmurze i nadal zarządzać nią jak dawnym serwerem w serwerowni. Z kolei dobrze zaprojektowany system backendowy może działać świetnie nawet wtedy, gdy nie wykorzystuje każdej możliwej funkcji platformy.
Jeśli ktoś pyta mnie, czy zawsze warto iść w mikroserwisy, odpowiadam ostrożnie: nie. Najpierw trzeba mieć powód biznesowy, potem granice domenowe, a dopiero później rozdrabniać system na niezależne usługi. Bez tego koszty komunikacji, obserwacji i wdrożeń rosną szybciej niż korzyści. To prowadzi prosto do typowych błędów, które psują cały projekt.
Najczęstsze błędy, które psują cały projekt
Według Kubernetes obserwowalność opiera się na metrykach, logach i trace’ach. W praktyce oznacza to jedno: jeśli nie widzisz systemu na trzech poziomach naraz, to w sytuacji awarii działa się bardziej na intuicji niż na danych.
- Zaczynanie od narzędzi, a nie od problemu. Zespół bierze Kubernetes, bo „tak się robi”, choć tak naprawdę potrzebuje tylko prostego pipeline’u i jednego porządnego środowiska uruchomieniowego.
- Mylne przekonanie, że kontener to architektura. Kontener jest opakowaniem, nie projektem systemu. Jeśli w środku zostaje chaos, to tylko szybciej go przenosisz.
- Brak obserwowalności od pierwszego dnia. Bez metryk, logów i trace’ów nie da się odróżnić problemu aplikacji od problemu infrastruktury.
- Trzymanie stanu lokalnie. Sesje, pliki tymczasowe i pliki użytkowników nie powinny zależeć od życia pojedynczego procesu.
- Wdrażanie bez planu wycofania. Rolling update bez sprawdzonego rollbacku wygląda dobrze tylko do pierwszej awarii.
- Rozbijanie monolitu za wcześnie. Mikroserwisy bez dojrzałych granic domenowych zwykle zwiększają liczbę problemów, a nie skalowalność.
- Dodawanie service mesh przed potrzebą. To potężna warstwa, ale przy małej skali częściej komplikuje niż pomaga.
Widziałem kilka projektów, w których największy zwrot przyniosło nie wprowadzenie kolejnego narzędzia, tylko uporządkowanie wdrożeń, konfiguracji i monitorowania. To często mniej efektowne niż migrowanie wszystkiego do „nowoczesnej platformy”, ale zwykle dużo skuteczniejsze. Z tego samego powodu sensownie jest zacząć od małych, dobrze dobranych kroków.
Jeśli zespół backendowy ma wejść w ten model bez chaosu, zacząłbym od jednego serwisu, który da się bezpiecznie zautomatyzować end-to-end. Potem dopiero dołożyłbym kolejne elementy i patrzył, gdzie naprawdę pojawia się wartość, a gdzie tylko rośnie złożoność.
Od czego zacząć, żeby zrobić to dobrze już przy pierwszym kroku
Najrozsądniejsza ścieżka to nie wielka rewolucja, tylko uporządkowana modernizacja. Jeśli miałbym rozpisać ją w kolejności, wyglądałaby tak:
- Wybierz jeden serwis o umiarkowanej złożoności i zrób z niego wzorzec dla reszty zespołu.
- Spisz granice odpowiedzialności: co jest stanem, co konfiguracją, a co logiką biznesową.
- Zamknij aplikację w kontenerze i doprowadź do tego, żeby uruchamiała się tak samo lokalnie, w testach i na produkcji.
- Ustaw pipeline z testami, publikacją artefaktu i automatycznym wdrożeniem.
- Dodaj metryki, logi i trace’y zanim ruch użytkowników stanie się realnym obciążeniem.
- Na końcu wybierz strategię wdrożeń: rolling, canary albo blue-green, zależnie od ryzyka i dojrzałości zespołu.
Jeśli miałbym wskazać jeden punkt startowy, wybrałbym automatyzację wdrożeń połączoną z dobrą obserwowalnością. To właśnie te dwa elementy najszybciej pokazują, czy system jest naprawdę gotowy na pracę w chmurze, czy tylko został tam przeniesiony. Reszta, choć ważna, ma sens dopiero wtedy, gdy fundament operacyjny jest już uporządkowany.