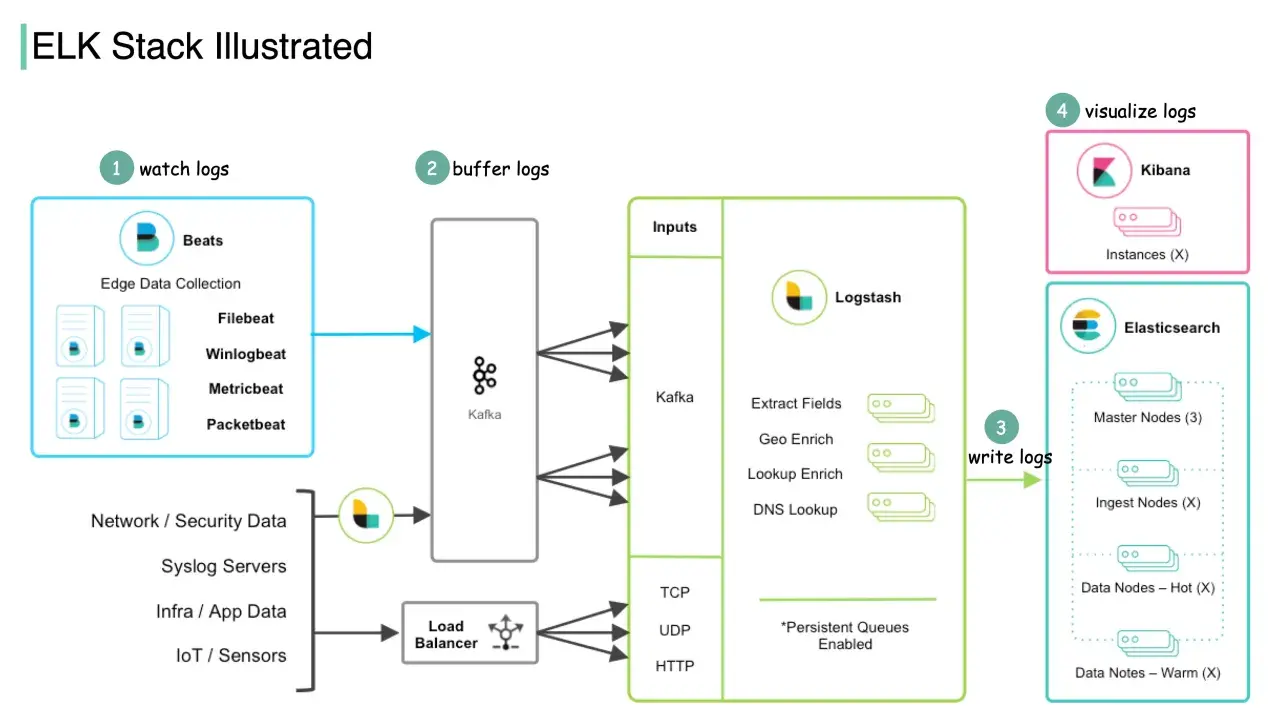
Centralne logowanie przestaje być dodatkiem, gdy backend rośnie, a zespół DevOps musi w kilka minut odpowiedzieć, co dokładnie wydarzyło się przed awarią. W praktyce ELK stack łączy zbieranie, przetwarzanie, wyszukiwanie i wizualizację logów w jeden przepływ, dzięki czemu surowe wpisy z aplikacji stają się danymi, które można sensownie analizować. Nazwa pochodzi od pierwszych liter Elasticsearch, Logstash i Kibana. Poniżej pokazuję, jak ten zestaw działa, kiedy ma sens, jakie daje korzyści i gdzie najłatwiej popełnić kosztowne błędy.
Kluczowe informacje o stosie ELK
- To nie jeden produkt, tylko trzy uzupełniające się role: zbieranie i transformacja, indeksowanie oraz wizualizacja.
- Największa wartość pojawia się wtedy, gdy logi są ustandaryzowane, można je przeszukiwać i łączyć z identyfikatorem żądania.
- Logstash jest bardzo przydatny przy chaotycznych lub tekstowych logach, ale przy prostym JSON-ie bywa opcjonalny.
- Kibana zmienia logi w narzędzie operacyjne: dashboardy, odkrywanie zdarzeń i alerty.
- Najczęstsze problemy to zbyt duża liczba indeksów, brak wspólnego schematu pól i brak polityki retencji.
Czym jest stos ELK i jaki problem rozwiązuje
Ja traktuję ten zestaw jako odpowiedź na bardzo praktyczny problem: logi z aplikacji, serwerów i kontenerów są rozrzucone, mają różny format i szybko przestają pomagać, jeśli trzeba je przeglądać ręcznie. To nie jest pojedyncza aplikacja, tylko zestaw trzech projektów open source, w którym Elasticsearch odpowiada za szybkie indeksowanie i wyszukiwanie, Logstash za pobieranie i przekształcanie danych, a Kibana za analizę, dashboardy i pracę operacyjną na zgromadzonych zdarzeniach.
Najważniejsze nie jest tu samo gromadzenie logów, tylko przejście od "mam tysiące linii tekstu" do "umiem odpowiedzieć, co się stało, gdzie i od kiedy". W dobrze ustawionym środowisku można szukać po nazwie usługi, poziomie logowania, adresie hosta, statusie HTTP albo identyfikatorze żądania, a to skraca diagnozę bardziej niż jakikolwiek ręczny grep.
Warto też pamiętać, że to nie jest narzędzie wyłącznie do logów. Ten sam model pracy dobrze obsługuje dane obserwowalności i zdarzenia operacyjne, ale dla backendu i DevOps najczęściej zaczyna się właśnie od logów aplikacyjnych i infrastrukturalnych.
To prowadzi do pytania ważniejszego niż sama definicja: jak te komponenty faktycznie układają się w przepływ danych.
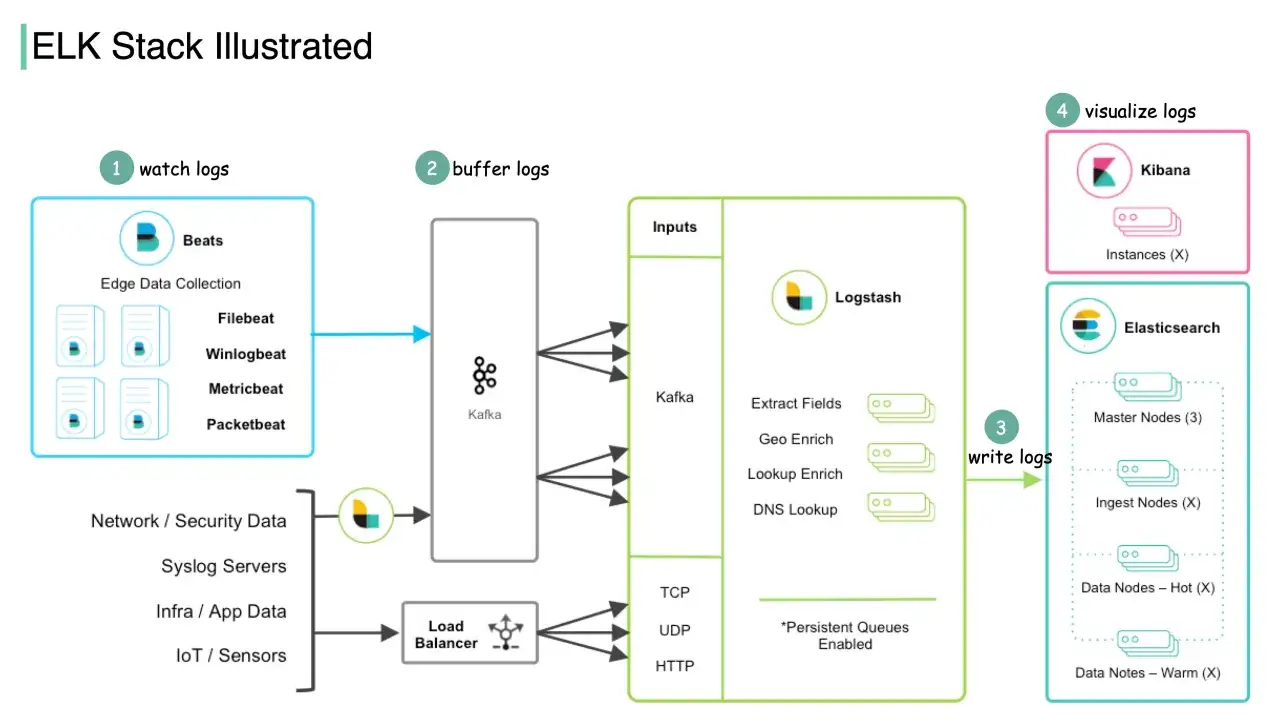
Jak działa przepływ logów w praktyce
W praktyce dane zwykle nie trafiają od razu do panelu. Najpierw trzeba je pobrać z hosta lub kontenera, potem ujednolicić, zindeksować i dopiero na końcu pokazać w interfejsie. I właśnie dlatego ten ekosystem ma sens: każdy etap robi inną, dobrze określoną robotę.
| Etap | Rola | Po co to robię |
|---|---|---|
| Źródło logów | Aplikacja, kontener, serwer, proxy, baza | To tutaj powstaje surowy zapis zdarzeń |
| Agent lub shipper | Zbiera logi z hosta i przekazuje dalej | Zmniejsza ryzyko utraty danych i odciąża aplikację |
| Logstash | Parsuje, filtruje, wzbogaca i normalizuje dane | Pomaga wyciągnąć sens z chaotycznego formatu |
| Elasticsearch | Indeksuje dane i umożliwia szybkie wyszukiwanie | Ułatwia analizę nawet przy dużym wolumenie zdarzeń |
| Kibana | Dashboardy, Discover, alerty, analiza | Przekształca logi w narzędzie do pracy zespołu |
Ja zwykle patrzę na trzy typowe warianty. Przy prostych usługach, które logują do JSON-a, da się często wysyłać dane niemal bezpośrednio do indeksu. Gdy źródła są różne, formaty niespójne albo trzeba maskować dane wrażliwe, Logstash robi się bardzo użyteczny. A jeśli część transformacji da się wykonać bliżej indeksu, architekturę można uprościć i nie budować niepotrzebnie zbyt wielu warstw.
Praktyczna zasada jest prosta: im bardziej chaotyczne logi i im więcej źródeł, tym większy sens ma warstwa pośrednia. Im bardziej strukturalny i przewidywalny format, tym częściej można ciąć złożoność.
To właśnie ta codzienna użyteczność decyduje o tym, czy backend i DevOps faktycznie korzystają z narzędzia, czy tylko je utrzymują.Dlaczego backend i DevOps tak często po to sięgają
W środowisku backendowym i DevOps chodzi przede wszystkim o czas reakcji. Kiedy produkcja zaczyna zwalniać albo zwracać 500, nie chcę przeklikiwać się przez pięć systemów i trzy formaty logów. Chcę szybko zobaczyć, które usługi zgłaszają błędy, na których hostach dzieje się najwięcej i czy problem pojawił się po deployu, po wzroście ruchu, czy po zmianie konfiguracji.
- Szybsza diagnoza incydentów - można filtrować po czasie, usłudze, środowisku i identyfikatorze żądania, więc korelacja zdarzeń jest znacznie prostsza.
- Lepsza obserwowalność aplikacji - dashboardy pokazują trendy, skoki błędów, opóźnienia i nietypowe wzorce, zanim problem urośnie.
- Wygodniejsze debugowanie wdrożeń - po wdrożeniu nowej wersji da się szybko sprawdzić, czy błędy dotyczą konkretnej wersji lub jednej części ruchu.
- Kontrola nad bezpieczeństwem i audytem - centralizacja logów ułatwia wykrywanie prób logowania, anomalii i nietypowych zdarzeń administracyjnych.
- Jedno źródło prawdy dla zespołu - backend, SRE i DevOps patrzą na te same dane, zamiast interpretować różne wycinki z różnych narzędzi.
Najbardziej cenię w tym jedną rzecz: logi przestają być materiałem do ręcznego przeglądania, a stają się podstawą do decyzji. To brzmi banalnie, ale w praktyce potrafi skrócić dochodzenie po incydencie z godzin do minut.
Ten efekt nie pojawia się jednak sam. Żeby naprawdę działało, trzeba dobrać odpowiedni zakres i nie próbować na siłę centralizować wszystkiego.
Kiedy to jest dobry wybór, a kiedy lepiej uprościć
Nie każdy zespół potrzebuje pełnego stosu od pierwszego dnia. Ja zwykle sugeruję go tam, gdzie logów jest już dużo, są rozproszone po wielu usługach albo trzeba je trzymać dłużej i przeszukiwać pod kątem incydentów, audytu lub analizy trendów.
| Sytuacja | ELK ma sens | Lepiej uprościć |
|---|---|---|
| Wiele mikroserwisów i częste wdrożenia | Tak, bo korelacja zdarzeń daje dużą wartość | Rzadko |
| Legacy aplikacja z chaotycznymi logami tekstowymi | Tak, zwłaszcza z Logstashem i wzorcami parsowania | Nie, jeśli nie chcesz trzymać logiki w aplikacji |
| Mały projekt z kilkoma usługami i prostą diagnostyką | Może, ale po lekkim wdrożeniu | Często tak, bo pełny stos bywa zbyt ciężki operacyjnie |
| Potrzeba tylko metryk CPU, RAM i kilku alertów | Niekoniecznie | Lepiej wybrać prostszy monitoring metryk |
| Wymagania audytowe i dłuższa retencja logów | Tak, jeśli polityka przechowywania jest dobrze zaplanowana | Nie, jeśli brak zasobów na utrzymanie indeksów |
W praktyce najczęściej wygrywa nie największy zestaw, tylko ten, który zespół potrafi utrzymać. Jeśli wiesz, że dane będą strukturalne, a potrzeby ograniczają się do jednego czy dwóch źródeł, możesz zacząć skromniej. Jeśli jednak logi mają ci pomóc w diagnozie produkcji, śledzeniu błędów i raportowaniu incydentów, ten ekosystem szybko się broni.
Problem zaczyna się wtedy, gdy wdrożenie jest technicznie poprawne, ale organizacyjnie chaotyczne. To już nie kwestia samego narzędzia, tylko kilku przewidywalnych błędów.
Najczęstsze błędy przy wdrożeniu i jak ich uniknąć
Widziałem kilka razy ten sam schemat: wszystko działa, ale po miesiącu nikt nie ufa danym. Zwykle winne są nie same komponenty, tylko brak decyzji na poziomie modelu logów, retencji i odpowiedzialności.
-
Brak wspólnego schematu pól - jeśli jedna usługa zapisuje
service_name, drugaapp, a trzeciacomponent, wyszukiwanie zamienia się w zgadywanie. Lepiej od początku ustalić jeden zestaw pól i trzymać się go konsekwentnie, najlepiej w duchu ECS, czyli wspólnego schematu nazw i znaczeń pól. - Zbyt dużo drobnych indeksów - małe, rozproszone indeksy potrafią zjadać zasoby szybciej niż same dane. Ja wolę mniej, ale sensowniej pogrupowanych indeksów i jasną politykę retencji.
- Logi tekstowe bez struktury - jeśli aplikacja produkuje tylko niejednoznaczny tekst, parsing staje się koniecznością, a nie wyborem. Przy nowych usługach lepiej logować od razu w JSON, a przy starszych pomóc sobie Logstashem i grokiem, czyli wzorcami do wydobywania pól z tekstu.
- Brak maskowania danych wrażliwych - centralizacja zwiększa ryzyko, jeśli do indeksu trafiają hasła, tokeny albo dane osobowe. Redakcja pól lub anonimizacja powinna być częścią pipeline'u, nie dodatkiem.
- Traktowanie Kibany jak zwykłej przeglądarki logów - dashboard bez alertów i bez zdefiniowanych pytań biznesowych szybko staje się ozdobą. Ja ustawiam choć kilka widoków, które naprawdę odpowiadają na pytanie "co się psuje i od kiedy?".
- Ignorowanie kosztu utrzymania - największy koszt to zwykle dysk, I/O, retencja i operacje na indeksach, a nie samo oprogramowanie. Jeśli nie policzysz tego wcześniej, stack zacznie wyglądać na drogi dokładnie wtedy, gdy najbardziej go potrzebujesz.
Jeśli mam wskazać jedną praktyczną zasadę, to tę: najpierw porządek w danych, potem rozbudowa narzędzi. Dobre logowanie aplikacyjne oszczędza później bardzo dużo pracy w całym pipeline'ie.
Po uporządkowaniu błędów zostaje już tylko jedno pytanie: co ustawić od startu, żeby całość nie zarosła chaosem po kilku sprintach.
Co ustawić od pierwszego dnia, żeby system nie zarósł chaosem
Gdy buduję taki ekosystem, zaczynam od kilku rzeczy, które mają największy wpływ na jakość pracy zespołu, a nie na efekt "wow" w pierwszym tygodniu.
- Wspólny zestaw pól - timestamp, service, environment, level, trace_id lub request_id, host i wersja wdrożenia.
- Jasną retencję - osobno dla danych bieżących, archiwalnych i testowych, zamiast jednego przypadkowego okresu przechowywania.
- Przynajmniej jeden dashboard incydentowy - taki, który od razu pokazuje skoki 5xx, timeouty, błędy autoryzacji i ruch po deployu.
- Reguły alertów - nie na wszystko, tylko na zdarzenia, które rzeczywiście wymagają reakcji człowieka.
- Maskowanie danych wrażliwych - szczególnie tokenów, numerów kont, adresów e-mail i danych użytkowników.
- Test na realnym incydencie - najlepiej na jednym historycznym błędzie, żeby sprawdzić, czy z logów naprawdę da się dojść do przyczyny bez zgadywania.
Jeśli te elementy są na miejscu, stos ELK przestaje być "kolejnym narzędziem do logów", a zaczyna realnie wspierać diagnostykę, bezpieczeństwo i pracę zespołu. Ja właśnie tak oceniam jego wartość: nie po liczbie ekranów, tylko po tym, czy po incydencie szybciej dochodzisz do prawdy.