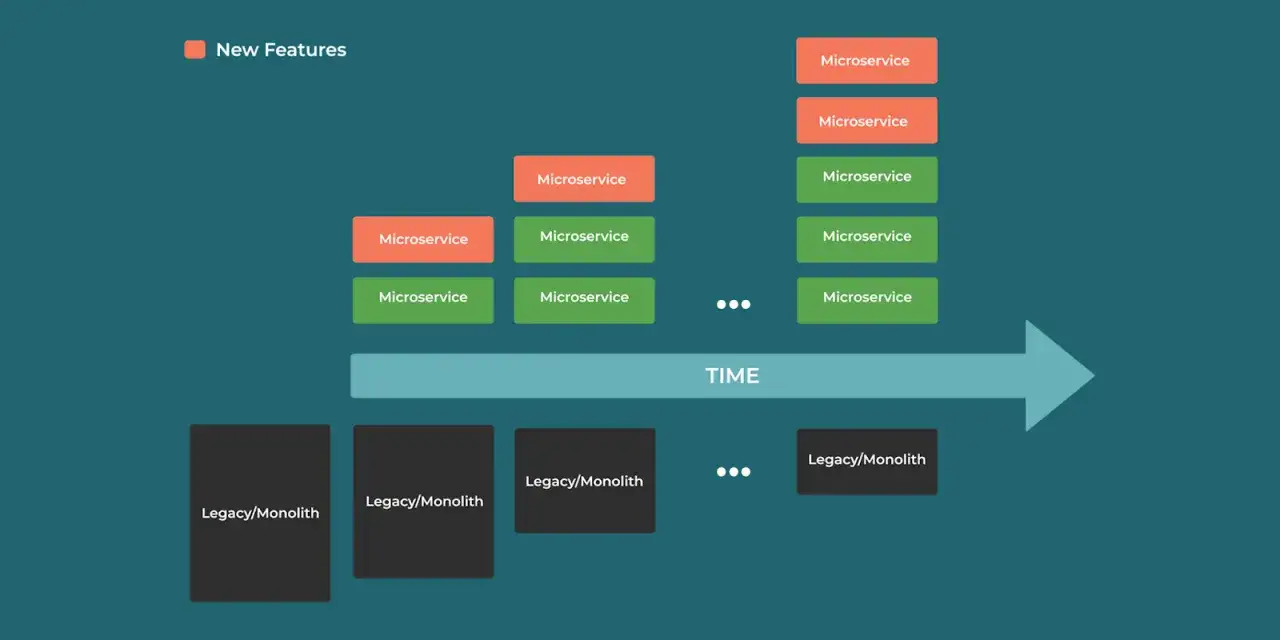
Migracja z monolitu do mikroserwisów rzadko udaje się jednym ruchem. Znacznie bezpieczniej działa podejście, w którym nowe fragmenty systemu przejmują ruch krok po kroku, a stary kod jest wycinany tylko tam, gdzie już został zastąpiony. Właśnie temu służy strangler pattern: pozwala ograniczyć ryzyko, utrzymać produkcję i uporządkować backend oraz DevOps wokół małych, odwracalnych zmian.
Najważniejsze fakty o stopniowej migracji monolitu
- To nie jest pełny rewrite, tylko kontrolowana wymiana funkcji, endpointów i danych.
- Najlepiej sprawdza się w dużych systemach, które muszą działać bez długich przerw.
- Kluczowe są: routing ruchu, obserwowalność, własność danych i plan wyłączenia starego kodu.
- Najczęstsze pułapki to współdzielona baza, brak testów kontraktowych i zbyt duży pierwszy krok.
- Najlepiej zacząć od obszaru o wyraźnej granicy domenowej i realnej wartości biznesowej.
Kiedy ten wzorzec ma sens, a kiedy tylko wydłuża projekt
To podejście ma największy sens wtedy, gdy monolit nadal zarabia, ma ruch produkcyjny i nie można sobie pozwolić na długi przestój. Ja zwykle traktuję je jako strategię dla systemów, których nie da się wyłączyć na kilka miesięcy, żeby „napisać wszystko od nowa”. W takim scenariuszu stopniowa migracja daje biznesowi nową wartość wcześniej, a zespołowi pozwala uczyć się systemu bez skoku w ciemność.
Nie oznacza to jednak, że każdy projekt powinien iść tą drogą. Jeśli aplikacja jest mała, zespół dobrze ją rozumie, a ryzyko operacyjne jest niskie, prostszy refactor albo nawet przepisanie wybranego modułu może być tańsze i szybsze. Wzorzec działa najlepiej tam, gdzie koszt błędu jest wysoki, granice domen są w miarę czytelne, a infrastruktura potrafi przyjąć ruch w modelu etapowym.
| Sytuacja | Stopniowa migracja | Lepsza alternatywa |
|---|---|---|
| Duży monolit z krytycznymi procesami | Tak, zwykle to najlepszy wybór | Rzadko, tylko przy bardzo prostych zmianach |
| Mało ruchu i niewielka złożoność | Często przerost formy nad treścią | Refactor w miejscu albo mniejszy rewrite |
| Brak automatycznych testów i rollbacku | Ryzykowne, bo każda zmiana boli podwójnie | Najpierw platforma, potem migracja |
| Wyraźne granice domenowe | Bardzo dobry sygnał do startu | Nie jest konieczna |
| Wspólna baza danych bez planu rozdzielenia | Możliwe tylko przejściowo | Najpierw model danych i ownership |
Jeśli po takiej ocenie nadal wychodzi, że migracja ma sens, trzeba ją rozbić na małe kroki. I właśnie od tego zależy, czy cały projekt będzie kontrolowany, czy po kilku sprintach zamieni się w wieloletni pół-rewrite. To prowadzi do pytania, jak taki ruch zaplanować technicznie.
Jak wygląda migracja krok po kroku
Ja zwykle zaczynam od wycinka, który jest wystarczająco ważny biznesowo, ale nie tak trudny, żeby od razu utopić zespół. Najlepszy kandydat to obszar z jedną, dobrze zdefiniowaną odpowiedzialnością, na przykład profile użytkownika, katalog, obsługa powiadomień albo prosty fragment procesu zamówienia. Chodzi o to, żeby pierwsze cięcie dało nam nie tylko nową architekturę, ale też praktyczną naukę.
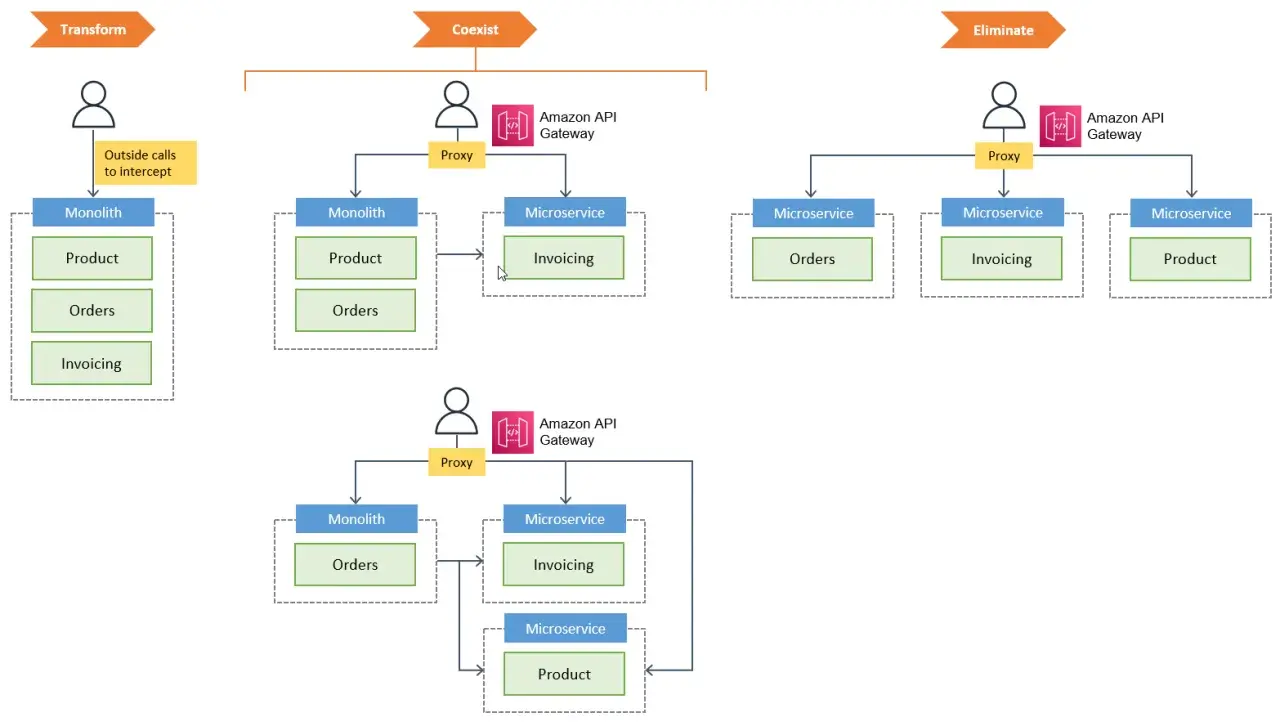
- Wyznacz granicę domeny. Najpierw trzeba ustalić, co dokładnie ma zostać wydzielone i jakie wejścia obsługuje ten fragment systemu.
- Wstaw warstwę przechwytywania ruchu. Może to być reverse proxy, API gateway, ingress albo inny punkt routingu, który pozwoli kierować część żądań do nowego serwisu.
- Uruchom nową implementację równolegle. Nowy serwis powinien obsługiwać ten sam kontrakt albo mieć adapter, który tłumaczy stare wywołania na nowy model.
- Przełącz tylko wybrany ruch. Zamiast migrować cały system naraz, kieruj najpierw pojedynczy endpoint, jedną akcję albo mały procent ruchu.
- Obserwuj metryki przed i po zmianie. Latencja, liczba błędów, timeouty, koszty i biznesowe wskaźniki muszą być widoczne od pierwszego dnia.
- Rozszerzaj zasięg dopiero po stabilizacji. Gdy nowa ścieżka działa przewidywalnie, dokładnie ten sam schemat powtarzasz dla kolejnych fragmentów.
- Usuń stary kod, gdy przestaje być potrzebny. Bez decommissioningu zostaje tylko dodatkowa złożoność, a nie realna modernizacja.
W praktyce bardzo pomaga feature flag, bo pozwala włączać nowe zachowanie dla małej grupy użytkowników albo tylko w środowisku testowym. Jeśli coś nie zagra, wracasz do starej ścieżki bez ręcznego grzebania w serwerach i bez nerwowego rollbacku całej wersji. Po takim pierwszym kroku zespół wie już, gdzie są największe tarcia i co trzeba dopracować dalej.
Jakie elementy techniczne składają się na bezpieczne przejęcie ruchu
Sam pomysł na migrację nie wystarczy, jeśli brakuje warstwy technicznej, która to spina. W backendzie i DevOps ten wzorzec opiera się na kilku klockach, które muszą działać razem: routingu, adapterach, testach, wdrożeniach i obserwowalności. Jeżeli jeden z nich zawiedzie, nowy system szybko zaczyna wyglądać jak kolejny monolit, tylko rozciągnięty między usługami.
| Element | Po co jest | Na co uważać |
|---|---|---|
| Proxy / API gateway | Przełącza ruch między starą i nową ścieżką | Nie może stać się pojedynczym punktem awarii |
| Feature flags | Pozwalają kontrolować dostęp do nowej funkcji | Bez porządku w flagach robi się chaos konfiguracyjny |
| Anti-corruption layer | Tłumaczy stary kontrakt na nowy i chroni nowy model przed starym bałaganem | To nie powinien być wieczny adapter bez planu usunięcia |
| Testy kontraktowe | Sprawdzają, czy stare i nowe API nadal się rozumieją | Bez nich migracja opiera się na nadziei, nie na pewności |
| CI/CD | Umożliwia częste wdrożenia i szybkie cofanie zmian | Ręczne publikowanie wersji spowalnia i zwiększa ryzyko |
| Observability | Daje metryki, logi i tracing dla obu ścieżek | Bez korelacji requestów trudno zrozumieć regresje |
W Pythonie takie przejście często zaczyna się od nowego serwisu w FastAPI albo Django REST Framework, a stary system zostaje jako źródło ruchu, dopóki nie zostanie wycięty. Na poziomie infrastruktury dobrze sprawdzają się też canary deployment i blue-green, bo pozwalają oddzielić wdrożenie od pełnego przełączenia ruchu. Najważniejsze jest jednak to, żeby routing był automatyczny, odwracalny i widoczny w metrykach, a nie ukryty w ręcznej procedurze dla kilku osób z zespołu.
Gdy ruch da się bezpiecznie przekierować, pojawia się trudniejszy temat: dane. I to właśnie dane najczęściej decydują o tym, czy migracja będzie elegancka, czy zamieni się w wieloletni kompromis.
Co dzieje się z danymi, transakcjami i spójnością
Największe problemy zwykle nie leżą w samym kodzie, tylko w tym, jak serwisy czytają i zapisują dane. Wiele zespołów odkrywa to dopiero wtedy, gdy pierwszy mikroserwis działa już poprawnie, ale nadal musi zaglądać do wspólnej bazy albo wykonywać operacje, które mają efekt uboczny w trzech innych miejscach. Wtedy łatwo wpaść w rozproszony monolit, czyli architekturę, która wygląda nowocześnie, ale zachowuje stare sprzężenia.
Własność danych musi być jednoznaczna
Każdy wydzielony serwis powinien mieć jasne prawo do swoich danych. Jeśli nowy moduł nadal czyta i zapisuje wszystko w tej samej bazie bez granic odpowiedzialności, zyskujesz tylko inny adres do tego samego problemu. Przejściowe współdzielenie danych bywa czasem konieczne, ale powinno mieć datę ważności i plan usunięcia.
Synchronizacja zmian wymaga prostych reguł
Jeżeli nowy serwis potrzebuje informacji z monolitu, można użyć zdarzeń, CDC, asynchronicznych kolejek albo warstwy integracyjnej, która kopiuje niezbędny wycinek danych. W praktyce najlepiej działa model, w którym stary system publikuje zmianę, a nowa usługa reaguje na nią we własnym tempie. Do historycznych danych często wystarcza jednorazowa migracja, a do zmian operacyjnych lepiej nadaje się przepływ zdarzeniowy niż ciągłe odpytywanie starej bazy.
Przeczytaj również: REST API w praktyce - Jak budować przewidywalne integracje?
Transakcje między usługami trzeba uprościć
Jeśli jeden biznesowy proces obejmuje kilka usług, nie licz na klasyczną transakcję ACID przez cały system. Zamiast tego używa się zwykle sag, mechanizmów kompensacji i idempotency, czyli odporności na wielokrotne przetworzenie tego samego żądania. Brzmi to mniej wygodnie niż jedna wspólna transakcja, ale w rozproszonym środowisku jest znacznie bliższe realiom produkcyjnym.
Tu właśnie widać różnicę między dojrzałą migracją a chaotycznym przepychaniem kodu. Jeśli zespół nie odpowie sobie jasno na pytanie, kto jest właścicielem danych, kto publikuje zdarzenia i kto cofa błędny zapis, każde kolejne wdrożenie będzie coraz droższe operacyjnie. A gdy ten obszar zaczyna się sypać, zwykle wychodzą na wierzch te same błędy organizacyjne.
Najczęstsze błędy, które psują migrację
- Zaczynanie od najtrudniejszego modułu. Pierwszy wycinek ma nauczyć zespół procesu, a nie spalić budżet na walce z najbardziej splątanym kawałkiem systemu.
- Brak testów kontraktowych i integracyjnych. Bez nich każda zmiana wymaga ręcznej wiary, że stare i nowe API nadal się zgadzają.
- Utrzymanie współdzielonej bazy bez planu rozdzielenia. To jeden z najszybszych sposobów na stworzenie rozproszonego monolitu.
- Za mała obserwowalność. Jeśli nie widzisz, gdzie rośnie latencja i gdzie pojawiają się błędy, trudno ocenić, czy migracja faktycznie działa.
- Brak planu wyłączenia starego kodu. Wtedy nowy serwis dochodzi, ale stary nigdy nie znika, więc rośnie koszt utrzymania.
- Równoległe przebudowywanie domeny, UX i infrastruktury. Im więcej osi zmieniasz naraz, tym trudniej ustalić, co tak naprawdę zepsuło produkcję.
Najbardziej zdradliwe jest to, że każdy z tych błędów da się na początku obronić jako „tymczasowy kompromis”. Problem zaczyna się wtedy, gdy kompromis nie ma daty końcowej i po kwartale staje się nową normą. Żeby tego uniknąć, warto wcześniej sprawdzić, czy zespół i platforma są w ogóle gotowe na taki model pracy.
Jak oceniam gotowość zespołu do takiej migracji
Nie zaczynałbym od wielkich planów architektonicznych, jeśli w organizacji nie ma jeszcze podstaw operacyjnych. W praktyce patrzę na kilka prostych sygnałów: czy wdrożenia są automatyczne, czy rollback naprawdę działa, czy metryki są dostępne od razu po release, i czy ktoś potrafi wskazać właściciela danego obszaru domeny. Bez tego migracja może się udać tylko przypadkiem.
- Masz działający pipeline CI/CD, a nie ręczne publikowanie wersji.
- Potrafisz monitorować błędy, latencję i zachowanie użytkowników po przełączeniu ruchu.
- Wiesz, który fragment monolitu ma wyraźną granicę i da się go wydzielić bez rozrywania połowy systemu.
- Zespół rozumie feature flags, canary release i podstawowe mechanizmy rollbacku.
- Masz przynajmniej minimalny plan dla danych: migracja, synchronizacja, ownership i wycofanie starej ścieżki.
Jeżeli tych elementów jeszcze nie ma, ja najpierw poprawiłbym platformę i praktyki wdrożeniowe, a dopiero potem zabierał się za cięcie monolitu. To nie jest opóźnianie właściwej pracy, tylko przygotowanie gruntu, żeby migracja nie skończyła się serią awarii i nerwowych hotfixów. Gdy fundament jest gotowy, następny krok robi się znacznie bardziej przewidywalny.
Co zostaje po udanej migracji i czego nie warto robić po drodze
Najlepszy efekt tego podejścia nie polega na tym, że masz „więcej mikroserwisów”. Prawdziwy sukces widać wtedy, gdy stary system przestaje obsługiwać ruch, a nowe usługi mają własne dane, własne wdrożenia i własną odpowiedzialność. Dopiero wtedy można powiedzieć, że migracja faktycznie się zamknęła, a nie tylko zmieniła adres.
- Usuń przejściowe adaptery i reguły routingu, które były potrzebne tylko w czasie migracji.
- Zamknij stare endpointy i ścieżki, zanim zaczną być przypadkowo używane przez nowe integracje.
- Przepisz runbooki, diagramy i alerty tak, żeby odpowiadały nowej architekturze.
- Sprawdź, czy nie został żaden martwy kod, flagi ani duplikowane integracje.
- Upewnij się, że ownership danych jest jasny także po stronie DevOps i wsparcia produkcji.
Jeśli miałbym zostawić jedną praktyczną radę, to tę: nie oceniaj tej strategii po liczbie nowych usług, tylko po tym, czy potrafisz bezpiecznie wyłączyć stary system. To właśnie tam wychodzi, czy migracja była dobrze zaplanowana, czy tylko elegancko opakowała ten sam dług techniczny w nową architekturę.