
Ład danych, czyli data governance, to nie jest dodatkowy dokument do odhaczenia, tylko sposób, w jaki organizacja decyduje, które informacje są wiarygodne, kto za nie odpowiada i jak wolno ich używać. W praktyce chodzi o dostępność, użyteczność i bezpieczeństwo danych, a więc o fundament pod analitykę, automatyzację i projekty AI. W tym tekście pokazuję, jak odróżnić porządek w danych od samego sprzątania plików, jak wdrożyć sensowny model krok po kroku i jak sprawdzić, czy naprawdę działa.
Co naprawdę decyduje o porządku w danych
- Ład danych ustala role, reguły i odpowiedzialność, ale nie zastępuje pracy operacyjnej nad danymi.
- AI bez wiarygodnych danych szybciej generuje błędy, niż daje przewagę biznesową.
- Najlepiej działają trzy filary: metadane i pochodzenie danych, kontrola dostępu oraz stała jakość.
- Start od jednego obszaru biznesowego jest skuteczniejszy niż próba uporządkowania całej organizacji naraz.
- W UE rośnie znaczenie zasad udostępniania, interoperacyjności i odpowiedzialnego użycia AI, więc porządek w danych staje się wymogiem operacyjnym.
Czym jest ład danych w organizacji
Ja patrzę na ten temat prosto: jeśli w firmie nie da się szybko odpowiedzieć, skąd pochodzi dana wartość, kto ją zatwierdził i kto może jej użyć, to nie ma jeszcze ładu danych, tylko luźny zbiór procesów. To właśnie dlatego ten obszar jest ważniejszy niż kolejny raport czy nowy dashboard - bez wspólnej definicji prawdy każdy zespół zaczyna działać według własnych reguł.
W praktyce ład danych nie jest tym samym co samo przechowywanie danych, ich czyszczenie albo bezpieczeństwo infrastruktury. To warstwa nadrzędna, która mówi:
| Obszar | Co robi | Czego nie robi |
|---|---|---|
| Ład danych | Ustala zasady, własność, dostęp i nadzór. | Nie czyści automatycznie rekordów. |
| Jakość danych | Sprawdza kompletność, spójność i poprawność. | Nie decyduje, kto ma prawo użycia. |
| Bezpieczeństwo danych | Chroni przed nieautoryzowanym dostępem i wyciekiem. | Nie nadaje znaczenia biznesowego danym. |
| Zarządzanie danymi | Obejmuje przechowywanie, integrację i przetwarzanie. | Nie zastępuje polityk i odpowiedzialności. |
W dobrze poukładanej organizacji te elementy działają razem, ale nie mieszają się w jedno hasło. W małej firmie może to oznaczać kilka prostych zasad i jedną odpowiedzialną osobę, w większej - model federacyjny, w którym centralny zespół ustala ramy, a domeny biznesowe pilnują ich w praktyce. To rozróżnienie jest ważne, bo bez niego łatwo wpaść w pułapkę „mamy narzędzie, więc mamy problem z głowy”.
Kiedy ten fundament jest jasny, dopiero wtedy warto uczciwie sprawdzić, dlaczego projekty AI tak mocno od niego zależą.
Dlaczego AI bez ładu danych szybko traci wartość
Modele AI nie naprawiają chaosu, tylko go wzmacniają. Jeśli uczysz model na niepełnych danych sprzedażowych, dostaniesz rekomendacje oparte na lukach. Jeśli chatbot odpowiada na podstawie dokumentów bez wersjonowania, zacznie brzmieć pewnie, ale niekoniecznie poprawnie. Jeśli nie masz pochodzenia danych, trudno będzie później wyjaśnić, dlaczego system podjął akurat taką decyzję.
W projektach typu RAG, czyli takich, które najpierw wyszukują źródła, a dopiero potem generują odpowiedź, jakość katalogu i metadanych decyduje o wyniku bardziej niż efektowny model. To widać od razu w praktyce: jeśli dokumenty są źle opisane, duplikowane albo pozbawione właściciela, system będzie „szukał” po omacku. Właśnie dlatego Komisja Europejska podkreśla, że lepsze zarządzanie i udostępnianie danych ma znaczenie także dla trenowania systemów AI.
Ja lubię też odwoływać się do podejścia NIST AI RMF, bo dobrze porządkuje ono myślenie o ryzyku w całym cyklu życia systemu AI. To ramy dobrowolne, ale bardzo użyteczne: przypominają, że ryzyko nie kończy się na etapie modelu, tylko obejmuje dane wejściowe, użycie, nadzór człowieka i późniejsze zmiany. Innymi słowy, jeśli dane są słabe, to nawet poprawnie wdrożony model będzie miał ograniczoną wartość.
Żeby tego uniknąć, potrzebujesz kilku stałych elementów - i one wcale nie są tak skomplikowane, jak brzmią w prezentacjach.
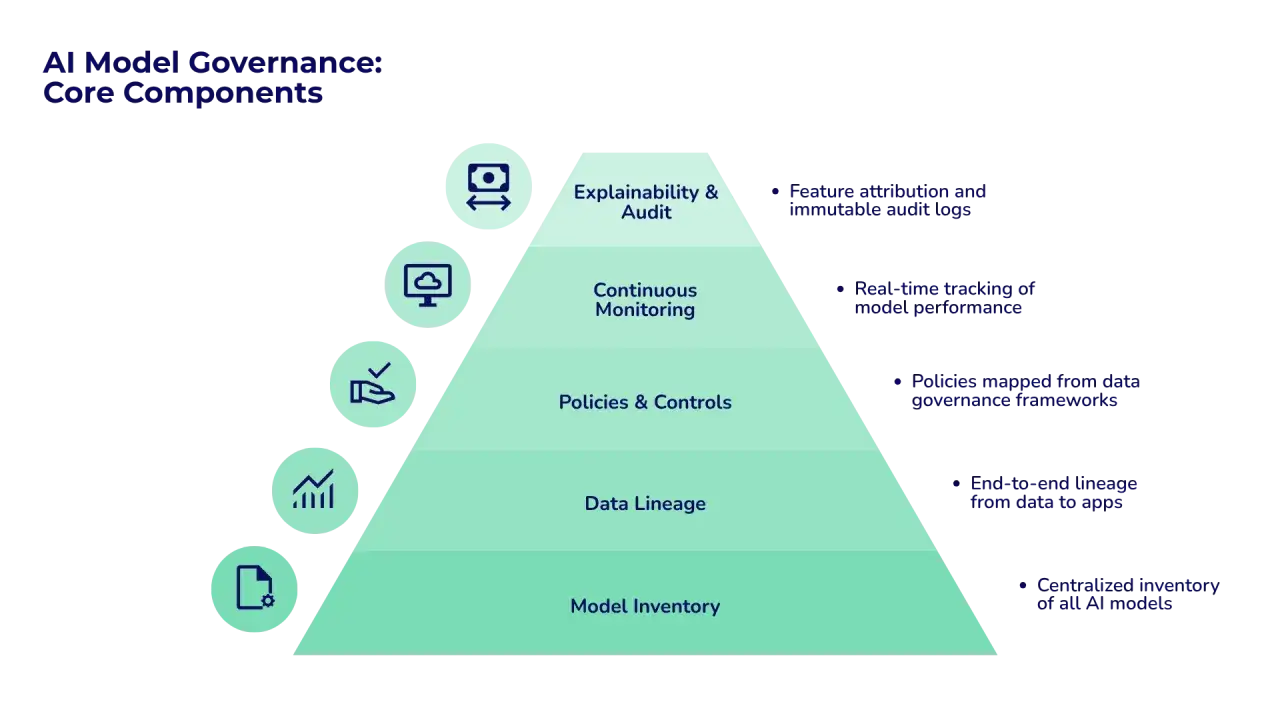
Z czego składa się sprawny model ładu danych
W dobrym modelu nie chodzi o kontrolowanie wszystkiego, tylko o to, by najważniejsze zasoby miały właściciela, opis, zasady i punkt odniesienia. Najlepiej działa tu podejście praktyczne: zaczynasz od danych, które realnie wpływają na decyzje biznesowe, a dopiero później rozszerzasz zasięg.
Role i odpowiedzialności
Najczęściej widzę, że firmy mają problem nie z technologią, tylko z odpowiedzialnością. Dane „należą do wszystkich”, a to zwykle oznacza, że nie odpowiada za nie nikt. W zdrowym modelu każda kluczowa domena ma własnego właściciela danych, stewarda i jasno opisane obowiązki dla zespołu technicznego oraz bezpieczeństwa.
| Rola | Za co odpowiada | Najczęstszy błąd |
|---|---|---|
| Właściciel danych | Decyduje, do czego dane służą i kto ma do nich dostęp. | Ma funkcję tylko na papierze. |
| Steward danych | Dba o definicje, jakość i spójność opisu. | Dostaje tytuł bez czasu na realną pracę. |
| Zespół danych lub platformy | Wdraża katalog, pipeline'y, kontrole i audyt. | Buduje narzędzie bez procesu. |
| Bezpieczeństwo i compliance | Nadaje reguły dla danych wrażliwych i osobowych. | Wchodzi dopiero po incydencie. |
Metadane i pochodzenie danych
Bez metadanych nie wiesz, co oznacza kolumna, skąd przychodzi rekord i czy wolno go użyć w modelu. Pochodzenie danych, czyli lineage, to ślad pokazujący, jak dane przepływają przez systemy, transformacje i raporty. To jeden z tych elementów, które są mało widowiskowe, ale robią największą różnicę, gdy trzeba wyjaśnić błąd albo odtworzyć decyzję.
W praktyce oznacza to katalog danych, słownik biznesowy i opis źródeł, a nie tylko nazwę tabeli. Jeśli ktoś w zespole sprzedaży widzi „aktywny klient”, a ktoś w AI rozumie to inaczej, powstaje klasyczny konflikt definicji. Tego nie naprawi sam model, bo najpierw trzeba zgodzić się co do znaczenia.
Dostęp i klasyfikacja
Nie wszystkie dane muszą mieć tę samą ochronę. Dane publiczne, wewnętrzne, poufne i wrażliwe powinny mieć różne reguły dostępu, retencji i maskowania. To nie jest nadmiar formalności, tylko zwykła higiena operacyjna, szczególnie gdy w grę wchodzą dane osobowe, dane finansowe albo informacje o klientach.
Tu przydaje się prosty podział: kto może zobaczyć dane, kto może je zmienić, kto może je eksportować i kto odpowiada za audyt. Jeśli te cztery pytania nie mają odpowiedzi, to w praktyce każdy „tymczasowy dostęp” zaczyna żyć własnym życiem.
Przeczytaj również: Jak podzielić komórkę w Excelu - 5 metod!
Jakość i cykl życia
Jakość danych to nie jednorazowy cleanup, tylko stały proces. Najważniejsze wymiary to kompletność, spójność, aktualność i poprawność. Do tego dochodzi cykl życia: kiedy dane powstają, gdzie są używane, kiedy tracą wartość i kiedy powinny zostać usunięte albo zarchiwizowane.
Ja zwracam uwagę szczególnie na ten ostatni punkt, bo firmy często inwestują w zbieranie danych, a potem nie wiedzą, co z nimi zrobić po roku czy dwóch. Jeśli nie ma reguł retencji, organizacja płaci za przechowywanie, ryzyko i bałagan jednocześnie.
Kiedy te cztery elementy są nazwane, wdrożenie przestaje być mglistym projektem i da się je rozpisać na konkretny plan.
Jak wdrożyć to krok po kroku bez biurokracji
Najgorszy start to próba uporządkowania całej firmy w jednym ruchu. Zwykle kończy się to dużą prezentacją, kilkoma warsztatami i brakiem efektu po trzech miesiącach. Ja wolę podejście małe, ale widoczne - jedno domenowe wdrożenie, jeden zespół, jeden wyraźny wynik.
- Wybierz obszar o największym wpływie - np. sprzedaż, obsługę klienta, logistyka albo dane używane w modelu AI.
- Spisz krytyczne źródła danych - nie wszystko naraz, tylko te zbiory, które realnie wpływają na decyzje i raporty.
- Przypisz właścicieli i stewardów - bez tego każdy problem będzie odbijany między zespołami.
- Zbuduj prosty słownik pojęć - ustal, co oznaczają podstawowe terminy biznesowe, a co jest tylko techniczną etykietą.
- Dodaj kontrole jakości do pipeline'ów - jeśli przetwarzasz dane w Pythonie, walidację warto uruchamiać już przy wejściu do ETL/ELT, zanim błąd przejdzie dalej.
- Wprowadź klasyfikację i reguły dostępu - określ, co jest publiczne, co wewnętrzne, a co wymaga ograniczeń lub maskowania.
- Zapisuj pochodzenie danych - lineage pomaga później odtworzyć źródło błędu i wyjaśnić, skąd wziął się wynik raportu albo modelu.
- Ustal rytm przeglądu - raz w tygodniu dla operacji, raz w miesiącu dla właścicieli domen i raz na kwartał dla szerszych decyzji.
W tym miejscu często wraca pytanie o narzędzia. Odpowiedź jest prosta: narzędzie ma wspierać proces, a nie go zastępować. Jeśli nie masz ustalonych ról, definicji i reguł, nawet dobry katalog danych stanie się tylko ładnym interfejsem do chaosu.
Gdy podstawy są już ustawione, przepisy przestają być abstrakcją i stają się listą konkretnych rzeczy do dowiezienia.
Co zmieniają unijne przepisy dla firm w Polsce
W polskich firmach to temat bardziej praktyczny, niż często się wydaje. Jeśli pracujesz na danych klientów, urządzeń, procesów operacyjnych albo dokumentów, to unijne regulacje wpływają bezpośrednio na to, jak te dane opisujesz, udostępniasz i archiwizujesz. Nie chodzi wyłącznie o zgodność prawną, ale o realny sposób działania zespołów danych i AI.
Unijny akt o zarządzaniu danymi (DGA) ma zwiększać zaufanie do dobrowolnego współdzielenia informacji i wspierać budowę europejskich przestrzeni danych. Data Act doprecyzowuje z kolei, kto może używać jakich danych i na jakich warunkach, zwłaszcza w kontekście urządzeń połączonych z siecią, chmury i interoperacyjności. To oznacza, że porządek w metadanych, własności i dostępie przestaje być opcją - staje się warunkiem sprawnej wymiany danych.
Do tego dochodzi AI Act, który opiera się na podejściu ryzykowym. W praktyce oznacza to większy nacisk na dokumentację, nadzór człowieka i odpowiedzialność za użycie modeli. Warto tu też pamiętać o AI literacy - czyli o tym, że osoby pracujące z AI muszą rozumieć ograniczenia systemu, kontekst użycia i potencjalne skutki błędów. NIST AI RMF dobrze pokazuje tę logikę: nie wystarczy, że model jest inteligentny; trzeba jeszcze umieć zarządzać ryzykiem na każdym etapie.
Dla mnie najważniejszy wniosek jest taki: przepisy nie robią ładu same, ale wyraźnie pokazują, gdzie nie wolno improwizować. A skoro już wiemy, czego wymaga otoczenie prawne, pozostaje najpraktyczniejsze pytanie - jak rozpoznać, że program naprawdę działa.
Jak sprawdzić, czy program działa w praktyce
Najlepiej mierzyć to, co naprawdę boli zespół. Jeśli analitycy tracą czas na szukanie danych, jeśli raporty różnią się między działami, a jeśli każda korekta wymaga ręcznego grzebania w plikach, to masz do czynienia z problemem ładu danych, nie tylko z problemem narzędzia. Ja zwykle zaczynam od metryk, które da się zobaczyć w codziennej pracy, a nie tylko w rocznym raporcie.
| Wskaźnik | Co pokazuje | Sygnał ostrzegawczy |
|---|---|---|
| Czas znalezienia zbioru danych | Jak szybko użytkownik dociera do właściwego źródła. | Trzeba pytać kilka osób albo przekopywać foldery i czaty. |
| Udział zbiorów z właścicielem i opisem | Czy dane mają przypisaną odpowiedzialność i kontekst. | Duża część zasobów jest „anonimowa”. |
| Odsetek krytycznych pól objętych walidacją | Czy jakości pilnujesz w punkcie wejścia do procesu. | Błędy wychodzą dopiero w raportach lub modelach. |
| Czas realizacji dostępu | Czy polityka uprawnień jest przejrzysta i sprawna. | Każdy wniosek wymaga ręcznych interwencji. |
| Liczba incydentów danych i AI | Czy dane lub modele generują problemy operacyjne. | Powtarzają się te same błędy bez poprawy procesu. |
Najczęstsze błędy są zaskakująco przewidywalne: zbyt szeroki zakres na start, brak właściciela biznesowego, rozjechany słownik pojęć i mierzenie samej liczby polityk zamiast tego, czy ludzie faktycznie z nich korzystają. Jeśli nie widać poprawy w codziennej pracy, program jest tylko formalnością. W takim przypadku lepiej zawęzić obszar, ale doprowadzić go do końca, niż utrzymywać rozległą, mało użyteczną strukturę.
Jeśli któryś z tych wskaźników jest słaby, najlepszym ruchem nie jest wielki audyt, tylko pierwszy mały zakres o wysokiej wartości.
Pierwsze 30 dni, które budują realny efekt
Jeśli miałbym zacząć od zera w średniej firmie, zrobiłbym to tak:
- Wybrałbym jeden proces o wysokiej wartości biznesowej.
- Opisałbym 20 najważniejszych zbiorów danych i przypisał im właścicieli.
- Uzgodniłbym podstawowe definicje w słowniku biznesowym.
- Dodałbym 3-5 reguł jakości do najważniejszych pipeline'ów.
- Ustawiłbym prostą klasyfikację danych i reguły dostępu.
- Włączyłbym przegląd metryk raz w tygodniu, bez rozbudowanej ceremonii.
To wystarcza, by zobaczyć pierwszą różnicę: mniej ręcznego porządkowania, mniej sporów o definicje i większe zaufanie do danych w projektach analitycznych oraz AI. Właśnie tak powinien wyglądać dobry start - mały, ale konkretny, z wyraźnym właścicielem i mierzalnym skutkiem.