
CTE to jeden z tych elementów SQL, który szybko porządkuje złożone zapytania i jednocześnie otwiera drogę do pracy z hierarchiami, rekurencją oraz etapowym przetwarzaniem danych. W praktyce pomaga pisać kod czytelniejszy, łatwiejszy do debugowania i mniej podatny na chaos niż rozbudowane podzapytania w środku jednego bloku. W tym artykule pokazuję, jak działa wspólne wyrażenie tablicowe, kiedy naprawdę się przydaje i gdzie lepiej nie zakładać, że zadziała „magicznie” wydajniej.
Najważniejsze rzeczy, które warto zapamiętać o CTE
- CTE to nazwany, tymczasowy wynik widoczny tylko w obrębie jednej instrukcji SQL.
- Najczęściej używa się go do rozbijania jednego dużego zapytania na logiczne etapy.
- Rekurencyjne CTE sprawdza się przy drzewach, zależnościach nadrzędnych i generowaniu sekwencji.
- Wydajność zależy od silnika bazy, więc CTE nie należy traktować jak automatycznego przyspieszacza.
- CTE nie zastępuje zawsze widoku ani tabeli tymczasowej, bo każde z tych narzędzi rozwiązuje inny problem.
Czym jest CTE i kiedy naprawdę się przydaje
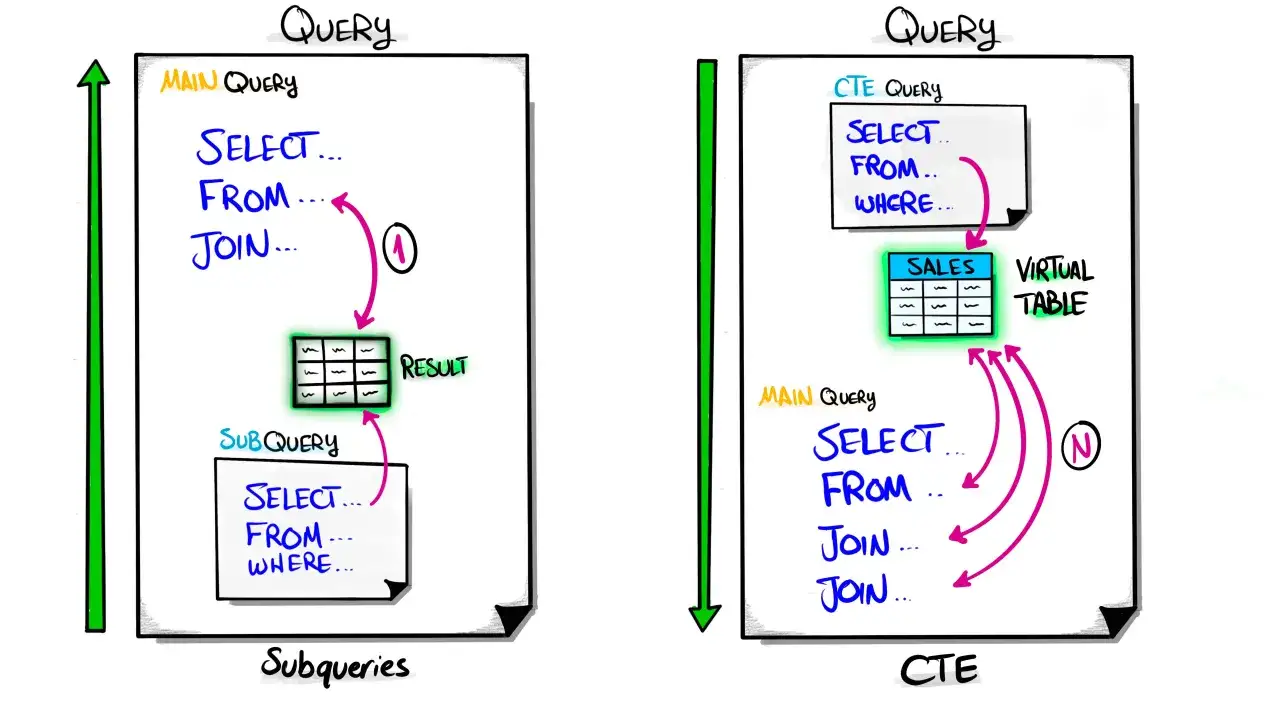
CTE, czyli wspólne wyrażenie tablicowe, to nazwany wynik pośredni zdefiniowany na początku zapytania w klauzuli WITH. Ja najprościej myślę o nim jak o „przystanku” w trakcie wykonywania SQL: najpierw buduję sensowny fragment danych, a dopiero potem używam go w głównej części instrukcji. Dzięki temu zapytanie staje się bardziej liniowe i dużo łatwiejsze do czytania.
W 2026 roku to już standard w większości popularnych silników SQL, ale warto pamiętać o jednej rzeczy: CTE istnieje tylko w obrębie jednego polecenia. Nie tworzy trwałego obiektu w bazie, nie zapisuje danych na później i nie działa jak zwykła tabela. To właśnie dlatego tak dobrze sprawdza się przy analizie danych, raportach i refaktoryzacji długich zapytań, gdzie liczy się przejrzystość, a nie samo „upakowanie” logiki w jeden blok.
W praktyce najczęściej używam CTE wtedy, gdy chcę rozdzielić zapytanie na etapy, na przykład najpierw odfiltrować poprawne rekordy, potem policzyć agregaty, a na końcu posortować wynik. Jeśli jednak problem sprowadza się do prostego filtrowania, zwykłe podzapytanie nadal bywa wystarczające. Kiedy wiesz już, czym CTE jest, czas zobaczyć, jak czytać jego składnię bez zgadywania.
Jak wygląda składnia i jak czytać zapytanie z WITH
Podstawowy wzorzec jest prosty: najpierw pojawia się WITH, potem jedna lub kilka nazwanych definicji, a na końcu główna instrukcja SQL. W wielu bazach można połączyć kilka CTE przecinkami i korzystać z nich po kolei, co świetnie pasuje do zapytań budowanych warstwowo.
WITH aktywni_klienci AS (
SELECT id, imie, miasto
FROM klienci
WHERE status = 'aktywny'
),
zamowienia_klientow AS (
SELECT k.id, k.imie, COUNT(*) AS liczba_zamowien
FROM aktywni_klienci k
JOIN zamowienia z ON z.klient_id = k.id
GROUP BY k.id, k.imie
)
SELECT *
FROM zamowienia_klientow
ORDER BY liczba_zamowien DESC;W tym przykładzie pierwszy CTE odcina niepotrzebne rekordy, a drugi buduje już wynik bardziej biznesowy. To ważne, bo od razu widać, co robi każdy etap. Zamiast szukać logiki w gęstym podzapytaniu, czytam zapytanie jak krótką sekwencję operacji. Ja zwykle właśnie tak zaczynam refaktoryzację: najpierw nazywam etapy, dopiero potem dopracowuję szczegóły.
Warto zapamiętać trzy praktyczne reguły. Po pierwsze, nazwy CTE powinny być jednoznaczne i nie powinny zderzać się z nazwami tabel. Po drugie, w definicji warto trzymać tylko to, co potrzebne na danym etapie, zamiast przepychać cały schemat. Po trzecie, w większości silników CTE nadal działa w ramach jednego zapytania, więc nie traktuj go jak obiektu trwałego. Dalej robi się ciekawiej, bo rekurencja pozwala wyjść poza zwykłe filtrowanie i wejść w struktury drzewiaste.
CTE rekurencyjne krok po kroku
Rekurencyjne CTE jest potrzebne wtedy, gdy wynik ma budować się sam na podstawie własnego poprzedniego kroku. Najczęstszy przypadek to hierarchie, na przykład kategorie produktów, pracownicy i menedżerowie, foldery w systemie plików albo komentarze z odpowiedziami. Drugie typowe zastosowanie to generowanie sekwencji, na przykład liczb lub dat.
Składa się z dwóch części. Część bazowa daje punkt startowy, a część rekurencyjna dokłada kolejne wiersze na podstawie poprzedniego wyniku. Bez warunku zakończenia taka konstrukcja nie ma sensu, bo zapytanie będzie próbowało iść dalej w nieskończoność albo aż do limitu silnika.
WITH RECURSIVE liczby AS (
SELECT 1 AS n
UNION ALL
SELECT n + 1
FROM liczby
WHERE n < 5
)
SELECT n
FROM liczby;Ten prosty przykład dobrze pokazuje logikę działania. Pierwszy krok zwraca 1, a każdy kolejny dodaje jeden do poprzedniej wartości, dopóki warunek n < 5 pozostaje prawdziwy. To nie jest sztuczka akademicka, tylko realny wzorzec, który przydaje się np. przy kalendarzach, raportach dziennych i rekonstrukcji ścieżek zależności.
Przy hierarchiach częściej wygląda to tak:
WITH RECURSIVE drzewo_kategorii AS (
SELECT id, parent_id, nazwa, 0 AS poziom
FROM kategorie
WHERE parent_id IS NULL
UNION ALL
SELECT k.id, k.parent_id, k.nazwa, d.poziom + 1
FROM kategorie k
JOIN drzewo_kategorii d ON k.parent_id = d.id
)
SELECT *
FROM drzewo_kategorii
ORDER BY poziom, nazwa;Tu wynik rośnie poziomami, a dodatkowa kolumna poziom pomaga potem w czytelnym uporządkowaniu danych. W zależności od silnika składnia rekurencji może się trochę różnić, więc jeśli pracujesz między kilkoma bazami, zawsze sprawdzaj szczegóły konkretnej implementacji. Z takim obrazem łatwiej przejść do pytania, czy CTE jest lepsze od podzapytania, widoku albo tabeli tymczasowej.
CTE a podzapytanie, widok i tabela tymczasowa
To porównanie jest ważniejsze niż sama definicja, bo w praktyce wybór narzędzia ma większy wpływ na kod niż nazwa konstrukcji. Ja traktuję CTE jako narzędzie do porządkowania logiki, a nie do automatycznego optymalizowania wydajności. Jeśli ten podział jest jasny, łatwiej wybrać właściwą formę dla konkretnego problemu.
| Konstrukcja | Kiedy wybieram | Co zyskuję | Na co uważać |
|---|---|---|---|
| CTE | Gdy chcę rozbić jedno złożone zapytanie na kroki | Lepszą czytelność i prostsze debugowanie | Nie zakładaj, że wynik będzie zawsze materializowany lub zawsze szybszy |
| Podzapytanie | Gdy potrzebuję krótkiego, lokalnego filtra lub agregacji | Mniej „nazwanego” kodu | Przy kilku warstwach robi się trudne do śledzenia |
| Widok | Gdy logika ma być używana wielokrotnie przez różne zapytania | Stały, wspólny punkt odniesienia w schemacie | To obiekt trwały, więc zmiany trzeba kontrolować ostrożniej |
| Tabela tymczasowa | Gdy wynik trzeba użyć kilka razy albo zindeksować | Większą kontrolę nad etapami i często lepszą praktykę przy dużych danych | Dochodzi koszt tworzenia, czyszczenia i czasem dodatkowego I/O |
Jak opisuje Microsoft Learn, zwykłe CTE w SQL Server nie są materializowane, więc wielokrotne odwołania mogą oznaczać ponowne wykonanie definicji. Z kolei w dokumentacji PostgreSQL znajdziesz rozróżnienie MATERIALIZED i NOT MATERIALIZED, co dobrze pokazuje, że ten sam koncept może być optymalizowany zupełnie inaczej zależnie od bazy.
Najprostszy wniosek jest taki: jeśli zależy Ci głównie na czytelności, CTE jest świetnym wyborem. Jeśli chcesz wielokrotnie używać tego samego wyniku w kilku miejscach, czasem lepsza będzie tabela tymczasowa albo widok. Gdy to rozróżnienie jest już jasne, łatwo wskazać błędy, które najczęściej psują efekt pracy z CTE.
Najczęstsze błędy, które spowalniają pracę z CTE
- Traktowanie CTE jak zawsze materializowanego bufora. To częsty skrót myślowy, ale niebezpieczny. Wydajność zależy od silnika i planu wykonania.
- Budowanie zbyt wielu warstw bez potrzeby. Trzy dobrze nazwane CTE często pomagają, ale siedem kolejnych może już tylko ukrywać logikę zamiast ją porządkować.
- Brak warunku zakończenia w rekurencji. Bez niego zapytanie nie ma bezpiecznego punktu stopu i łatwo kończy się problemami.
- Używanie CTE do wszystkiego. Czasem zwykłe podzapytanie jest po prostu prostsze, a czasem lepiej od razu sięgnąć po tabelę tymczasową.
- Ignorowanie duplikatów i cykli w danych hierarchicznych. W drzewach z błędnymi relacjami rekurencja potrafi zwrócić zaskakujący wynik albo wejść w pętlę logiczną.
- Wpychanie do CTE całego ciężkiego SELECT-a bez selekcji kolumn. Im większy niepotrzebny wynik pośredni, tym trudniej o czytelny plan i sensowną optymalizację.
Ja zwykle sprawdzam dwa pytania jeszcze przed uruchomieniem: czy ten etap naprawdę wnosi nazwę i sens do zapytania oraz czy CTE nie robi tylko tego, co równie dobrze zrobiłby prosty join. Jeśli odpowiedź na drugie pytanie brzmi „tak”, upraszczam. Jeśli nie, zostawiam CTE, ale pilnuję, by było krótkie i jednoznaczne. To prowadzi już do praktyki codziennego użycia, czyli do sytuacji, w których CTE naprawdę daje najwięcej.
Jak wykorzystać je w codziennych zapytaniach bez nadmiaru złożoności
Jeśli mam pod ręką złożony raport, zwykle zaczynam od rozpisania go na dwa albo trzy logiczne kroki. Najpierw filtruję dane źródłowe, potem liczę lub grupuję, a na końcu dopiero robię finalną prezentację wyniku. Taki układ dobrze działa, bo każdy etap ma jedną odpowiedzialność i łatwo sprawdzić, gdzie pojawia się błąd.
W praktyce najlepiej działa prosty zestaw zasad:
- Ograniczaj CTE do jednego sensownego etapu biznesowego, a nie do przypadkowego fragmentu kodu.
- Nazwij je tak, by od razu było widać, co robią, na przykład
aktywni_kliencialbosprzedaz_miesieczna. - Jeśli wynik jest używany wielokrotnie, porównaj CTE z tabelą tymczasową i planem wykonania.
- Przy rekurencji zawsze trzymaj w definicji jasny warunek stopu.
- Nie zakładaj, że CTE przyspieszy zapytanie tylko dlatego, że jest „bardziej eleganckie”.
Moja praktyczna heurystyka jest prosta: jeśli po zamianie podzapytania na CTE kod staje się łatwiejszy do przejrzenia po tygodniu, zmiana miała sens. Jeśli jedyne, co zyskałeś, to dodatkową nazwę bez czytelniejszej logiki, lepiej wrócić do prostszej wersji. CTE ma pomagać w myśleniu o zapytaniu, a nie tworzyć kolejny poziom ozdobnego SQL. Jeśli więc pracujesz nad raportem, analizą albo hierarchią danych, zacznij od małego, dobrze nazwnego CTE i dopiero potem oceniaj, czy potrzebujesz czegoś cięższego.