
Relacyjne bazy danych wciąż są podstawą większości systemów, które muszą przechowywać uporządkowane informacje, pilnować spójności i pozwalać szybko je odpytywać przez SQL. W tym tekście pokazuję, jak działa model tabelaryczny, po co są klucze i złączenia, kiedy taki wybór ma największy sens oraz gdzie jego granice zaczynają być widoczne. Dorzucam też praktyczny punkt widzenia z perspektywy aplikacji w Pythonie, bo to właśnie tam teoria najczęściej zderza się z codziennym użyciem.
Najważniejsze informacje w skrócie
- Model relacyjny porządkuje dane w tabelach połączonych kluczami i ograniczeniami spójności.
- SQL służy nie tylko do pobierania danych, ale też do ich modyfikacji, agregacji i ochrony integralności.
- Największą przewagę ten model daje tam, gdzie liczą się transakcje, raporty i przewidywalna struktura danych.
- Przy bardzo zmiennych lub zagnieżdżonych danych warto rozważyć inne podejście, czasem hybrydowe.
- W Pythonie dobry start to zwykle SQLite do prototypu i PostgreSQL do poważniejszego wdrożenia.
Na czym polega model relacyjny
Najkrócej mówiąc, w modelu relacyjnym dane trafiają do tabel, a każda tabela opisuje jeden typ informacji: użytkowników, zamówienia, produkty, płatności albo cokolwiek innego, co da się sensownie wydzielić jako osobny byt. Każdy wiersz to pojedynczy rekord, a każda kolumna przechowuje konkretną cechę tego rekordu. Dla mnie to właśnie prostota jest tu największą zaletą: zamiast upychać wszystko w jednym dużym obiekcie, dzielisz dane na logiczne fragmenty.
Tabela, wiersz i kolumna mają konkretne znaczenie
To nie jest tylko wygodny sposób zapisu. Tabela reprezentuje pewną klasę obiektów, wiersz opisuje jeden egzemplarz, a kolumna mówi, jaką właściwość zapisujesz. W praktyce oznacza to, że schemat bazy nie jest przypadkowym zbiorem pól, tylko uporządkowanym modelem rzeczywistości. Jeśli sklep internetowy ma klientów, zamówienia i pozycje zamówień, to zwykle nie mieszam tych danych w jednym miejscu, bo później trudniej je utrzymać i analizować.
Relacje są ważniejsze niż sama tabela
Samo trzymanie danych w tabelach jeszcze nie wystarcza. Sednem modelu są powiązania między tabelami, czyli relacje. Dzięki nim baza wie, które zamówienie należy do którego użytkownika, które produkty znajdują się w koszyku i która faktura odpowiada konkretnej transakcji. To właśnie ta warstwa sprawia, że dane przestają być luźnym zbiorem rekordów, a stają się spójnym systemem.
Jeśli dobrze rozumiesz ten fundament, łatwiej ocenisz, dlaczego klucze i złączenia są tak istotne w codziennej pracy z danymi.
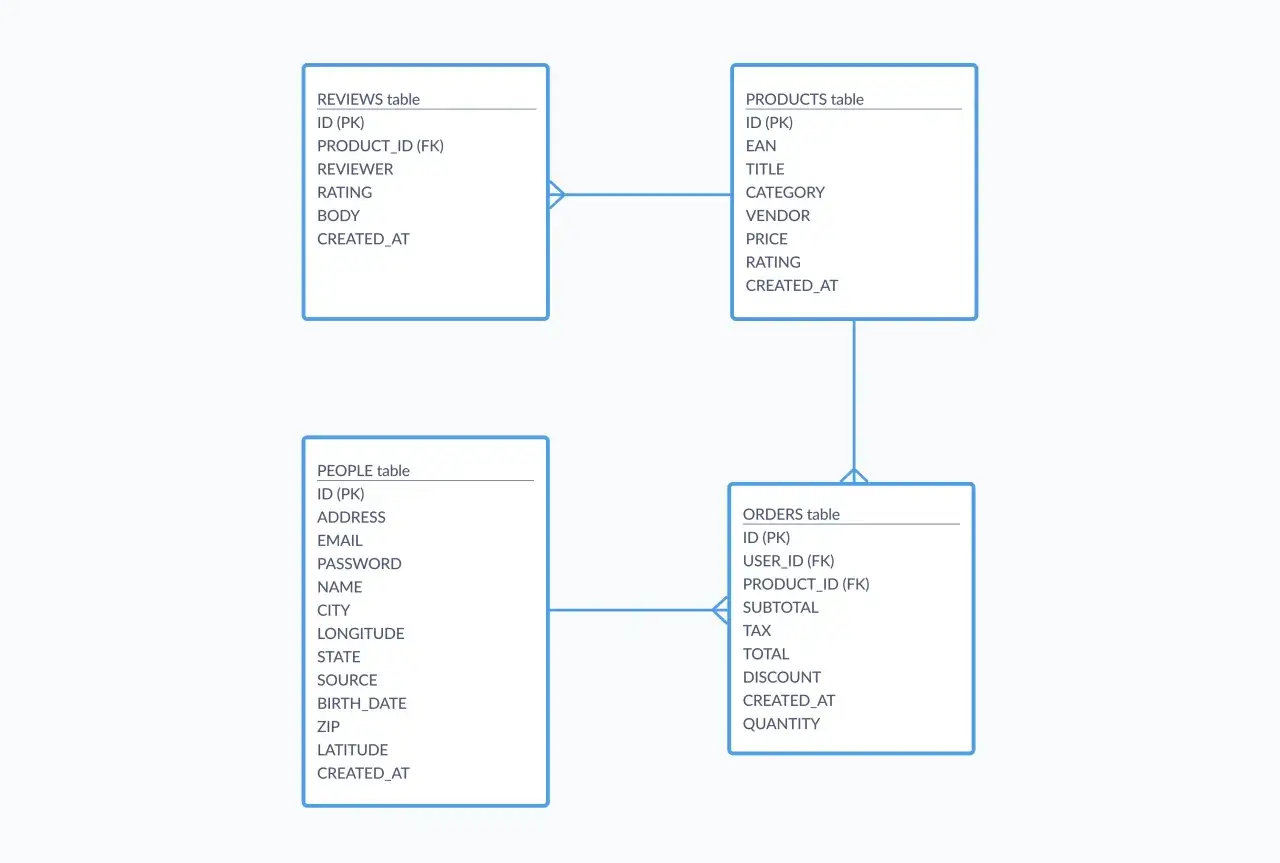
Jak działają klucze i powiązania między tabelami
W relacyjnych systemach zarządzania bazą danych najważniejsze są dwa typy kluczy: klucz główny i klucz obcy. Klucz główny jednoznacznie identyfikuje rekord w tabeli, a klucz obcy wskazuje rekord w innej tabeli. To proste rozwiązanie daje bardzo dużo kontroli nad danymi, bo baza może pilnować, czy powiązania są poprawne, zamiast zostawiać to wyłącznie logice aplikacji.
Klucz główny porządkuje identyfikację
W praktyce klucz główny jest numerem referencyjnym rekordu. Najczęściej spotkasz tutaj identyfikator liczbowy albo UUID. Ważne jest nie to, jak wygląda, tylko to, że nie powtarza się w tej samej tabeli i pozwala szybko wskazać konkretny rekord. Bez tego raporty, złączenia i aktualizacje stają się kruche, a błędy trudniejsze do wykrycia.
Klucz obcy pilnuje spójności
Jeśli tabela zamówień przechowuje `user_id`, to klucz obcy wymusza, żeby ten identyfikator faktycznie istniał w tabeli użytkowników. Dzięki temu nie tworzysz zamówienia „z powietrza”. Właśnie tu najlepiej widać siłę modelu relacyjnego: baza sama broni się przed chaosem, zamiast pozwalać na dowolne wpisy, które później trzeba ręcznie czyścić.
CREATE TABLE users (
id INTEGER PRIMARY KEY,
email TEXT NOT NULL UNIQUE
);
CREATE TABLE orders (
id INTEGER PRIMARY KEY,
user_id INTEGER NOT NULL,
total NUMERIC(10, 2) NOT NULL,
created_at TIMESTAMP NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);JOIN łączy rozproszone dane w jeden wynik
Gdy dane są rozdzielone na kilka tabel, do gry wchodzi JOIN. To operacja, która pozwala pobrać powiązane rekordy jako jeden logiczny wynik. W praktyce właśnie tak buduje się większość sensownych zapytań analitycznych i biznesowych. Ja zwykle traktuję JOIN nie jako „zaawansowany SQL”, ale jako codzienne narzędzie do odzyskiwania pełnego obrazu danych z dobrze zaprojektowanego schematu.
Ta logika prowadzi bezpośrednio do SQL, bo to właśnie język zapytań wyciąga z modelu relacyjnego pełnię możliwości.
Jak SQL wykorzystuje ten model w praktyce
SQL nie jest samą bazą danych, tylko językiem, którym z tą bazą rozmawiasz. Największa zaleta tego podejścia polega na tym, że opisujesz co chcesz dostać, a nie dokładnie jak silnik ma to policzyć. To wygodne, bo baza może dobrać własny plan wykonania i wykorzystać indeksy, statystyki oraz mechanizmy optymalizacji.
SELECT u.email, COUNT(o.id) AS liczba_zamowien
FROM users u
JOIN orders o ON o.user_id = u.id
GROUP BY u.email
ORDER BY liczba_zamowien DESC;W takim zapytaniu widać trzy rzeczy naraz: filtrowanie, łączenie tabel i agregację. To właśnie dlatego SQL tak dobrze pasuje do danych tabelarycznych. Z jednej strony daje czytelność, z drugiej pozwala budować bardzo złożone analizy bez przenoszenia wszystkiego do kodu aplikacji.
Przeczytaj również: Indeksy w bazie danych - Jak przyspieszyć SQL i unikać błędów?
Transakcje nie są dodatkiem, tylko zabezpieczeniem
W systemach biznesowych ogromne znaczenie mają transakcje. Pozwalają wykonać kilka operacji jako jedną całość. Jeśli coś się nie uda, można cofnąć wszystkie zmiany, zamiast zostawiać bazę w połowicznie zapisanym stanie. To ma znaczenie przy płatnościach, magazynie, księgowości czy rezerwacjach.
- Atomowość oznacza, że zmiana przechodzi w całości albo wcale.
- Spójność pilnuje reguł biznesowych i ograniczeń schematu.
- Izolacja ogranicza mieszanie się równoległych operacji.
- Trwałość gwarantuje, że zapisane dane nie znikną po awarii.
Jeżeli te zasady są dobrze ustawione, baza staje się stabilnym fundamentem aplikacji. To z kolei prowadzi do pytania, w jakich projektach taki fundament naprawdę daje przewagę.
Gdzie ten model daje największą przewagę
Najlepiej czuję się z relacyjnym podejściem tam, gdzie dane muszą być dokładne, powiązane i przewidywalne. To nie jest przypadek, że taki model dominuje w systemach finansowych, sprzedażowych i administracyjnych. Tam koszt błędu jest zwykle większy niż koszt utrzymania bardziej rygorystycznego schematu.
- Systemy transakcyjne - zamówienia, płatności, faktury i magazyn potrzebują spójności oraz kontroli zmian.
- Raportowanie i analityka operacyjna - SQL bardzo dobrze radzi sobie z agregacjami, grupowaniem i filtrowaniem danych.
- Dane referencyjne - słowniki, statusy, katalogi i słabo zmieniające się encje świetnie pasują do tabel.
- Aplikacje biznesowe - CRM, systemy HR, ERP i panele administracyjne zwykle korzystają z relacji między encjami.
- Nauka i rozwój w Pythonie - to praktyczne środowisko do ćwiczenia modelowania danych, zapytań i transakcji.
W skrócie: jeśli dane mają sens w relacjach, a nie w luźnych dokumentach, ten model zazwyczaj wygrywa przewidywalnością. Gdy jednak struktura zaczyna się rozjeżdżać, warto spokojnie sprawdzić alternatywy.
Kiedy lepiej rozważyć inne rozwiązanie
Nie każda aplikacja potrzebuje ścisłej struktury tabelarycznej. Czasem dane są zbyt różnorodne, zbyt szybko się zmieniają albo są w dużej części zagnieżdżone. Wtedy relacyjna baza nadal może działać, ale koszt projektowania i utrzymania rośnie, a zyski z rygoru są mniejsze niż w klasycznych systemach transakcyjnych.
| Sytuacja | Model relacyjny | Gdy inne podejście bywa lepsze |
|---|---|---|
| Stała struktura danych | Bardzo dobry wybór, bo schemat ułatwia kontrolę i raportowanie | Rzadko potrzebna jest alternatywa |
| Często zmieniające się pola | Da się to obsłużyć, ale schema potrafi szybko się rozrastać | Dokumenty JSON lub NoSQL bywają wygodniejsze |
| Bardzo duża skala odczytów rozproszonych | Może wymagać solidnego strojenia i skalowania | Niektóre systemy kolumnowe lub dokumentowe lepiej znoszą taki profil |
| Dane zagnieżdżone i półstrukturalne | Możliwe, ale często z mniejszą wygodą modelowania | Model dokumentowy zwykle daje większą swobodę |
W praktyce wiele zespołów nie wybiera jednego obozu na zawsze. Trzyma główny system w modelu relacyjnym, a obok używa cache, wyszukiwarki albo magazynu dokumentów do zadań pobocznych. To rozsądne podejście, bo nie każdy problem trzeba wciskać w jeden typ bazy. Z tego miejsca łatwo przejść do tego, jak ja projektuję taki układ, gdy w grę wchodzi Python.
Jak projektuję schemat w aplikacji Python
Gdy buduję nową aplikację, zaczynam od encji, a nie od technologii. Najpierw pytam, jakie obiekty istnieją w systemie, jak się ze sobą łączą i które pola są krytyczne dla spójności. Dopiero potem decyduję, czy wystarczy SQLite, czy od razu lepiej wejść w PostgreSQL. To podejście oszczędza późniejszych przeróbek, bo schemat powstaje z logiki biznesowej, a nie z przyzwyczajenia do konkretnego narzędzia.
- Wyznacz podstawowe encje i relacje, na przykład użytkownik, zamówienie i pozycja zamówienia.
- Dodaj klucze główne tam, gdzie identyfikacja musi być jednoznaczna.
- Wprowadź klucze obce i ograniczenia `NOT NULL`, `UNIQUE` oraz `CHECK`, jeśli mają sens biznesowy.
- Nie normalizuj na siłę, ale też nie trzymaj kilku bytów w jednej tabeli tylko dlatego, że tak jest szybciej na start.
- Załóż indeksy dla kolumn, po których naprawdę filtrujesz lub łączysz dane.
- Dopiero na końcu wybierz warstwę dostępu z poziomu Pythona.
Jeśli chodzi o narzędzia, najczęściej widzę trzy rozsądne opcje: `sqlite3` do prostych projektów i testów, `psycopg` lub inny lekki driver do pracy z PostgreSQL oraz SQLAlchemy wtedy, gdy ORM faktycznie upraszcza kod, a nie zasłania logikę zapytań. ORM jest wygodny, ale nie zwalnia z rozumienia SQL. Ja traktuję go jako pomoc, nie jako zastępstwo myślenia o danych.
W praktyce bardzo dobrze działa też podejście migracyjne, na przykład z Alembic, bo schemat bazy rzadko pozostaje niezmienny. Gdy aplikacja rośnie, zmiany w tabelach stają się normalne, a nie wyjątkowe. I właśnie wtedy zaczynają wychodzić na jaw typowe błędy projektowe.
Najczęstsze błędy, które psują nawet dobry projekt
Z mojego doświadczenia problemy rzadko wynikają z samego modelu. Najczęściej psuje go sposób użycia. Można mieć świetną bazę i nadal zrobić z niej źródło frustracji, jeśli od początku ignoruje się spójność, indeksy i sensowny podział danych.
- Brak ograniczeń - bez kluczy i walidacji baza przyjmuje dane, których później nie da się łatwo uporządkować.
- Trzymanie list i obiektów w jednej kolumnie - to zwykle sygnał, że schemat jest zbyt luźny albo źle rozcięty na tabele.
- Nadmierna normalizacja - zbyt wiele małych tabel może utrudnić odczyt i niepotrzebnie skomplikować zapytania.
- Indeksowanie wszystkiego - indeks przyspiesza odczyt, ale kosztuje miejsce i spowalnia zapisy.
- Ukrywanie SQL za ORM-em - jeśli nie wiesz, jakie zapytanie naprawdę trafia do bazy, łatwo przegapić powolne joiny i błędne założenia.
Najważniejsze jest więc nie samo narzędzie, ale dyscyplina projektowa. Dobra baza nie musi być przesadnie skomplikowana, ale powinna być konsekwentna. I właśnie ta konsekwencja daje największy zwrot w dłuższym czasie.
Dlaczego dobrze zaprojektowany model danych ułatwia rozwój aplikacji
Jeśli mam wskazać jedną rzecz, która najbardziej pomaga w praktyce, to jest nią połączenie prostego schematu z jasnymi regułami spójności. Taka baza szybciej odpowiada na zapytania, łatwiej się ją utrzymuje i mniej zaskakuje przy rozbudowie aplikacji. To nie jest efekt „magii SQL”, tylko konsekwencja dobrego modelowania.
W projektach, które mają rosnąć, zaczynam od myślenia o danych, a dopiero potem dobieram framework, ORM i resztę infrastruktury. Dzięki temu aplikacja w Pythonie nie walczy z bazą, tylko z niej korzysta. A to zwykle oznacza mniej awarii, prostsze raporty i mniej kosztownych przeróbek w przyszłości.