Dobra analiza ankiety nie zaczyna się od wykresu, tylko od pytania, co te odpowiedzi naprawdę mają powiedzieć o badanej grupie. W tym artykule pokazuję, jak porządkować dane kwestionariuszowe, jak czytać wyniki bez mylenia korelacji z przyczyną oraz gdzie AI faktycznie przyspiesza pracę, a gdzie tylko robi wrażenie. To praktyczny przewodnik dla osób, które chcą wyciągać wnioski z danych, a nie tylko wypełniać tabelki.
Najpierw porządkuj dane, potem interpretuj liczby, a AI traktuj jako wsparcie przy kodowaniu i raporcie
- Najważniejsze decyzje zapadają jeszcze przed liczeniem wyników: liczy się cel badania, jakość próby i sposób zadania pytań.
- Surowy plik z ankiety trzeba oczyścić, ujednolicić i opisać, bo drobne błędy potrafią zniekształcić cały obraz.
- W pytaniach zamkniętych lepiej patrzeć na rozkład odpowiedzi i segmenty niż na pojedynczą średnią bez kontekstu.
- W pytaniach otwartych AI świetnie wspiera kodowanie i grupowanie tematów, ale człowiek nadal musi zatwierdzić sens wniosków.
- Python przyspiesza powtarzalną analizę, automatyzuje wykresy i pozwala utrzymać spójny proces między kolejnymi badaniami.
- Najlepszy raport nie tylko opisuje dane, ale prowadzi do decyzji: co zmienić, dla kogo i z jakim priorytetem.
Co trzeba ustalić, zanim zaczniesz interpretację wyników
Ja zawsze zaczynam od trzech pytań: kto odpowiadał, po co zebrano dane i czy pytania naprawdę mierzyły to, co miały mierzyć. Bez tego nawet elegancko wyglądający dashboard może prowadzić do fałszywych wniosków. Inaczej czyta się ankietę satysfakcji klientów, inaczej badanie pracowników, a jeszcze inaczej prosty formularz opinii po wydarzeniu.
Najczęstszy błąd to traktowanie każdego zbioru odpowiedzi jak materiału reprezentatywnego dla całej populacji. Jeśli ankieta była rozsyłana do osób, które same zdecydowały się odpowiedzieć, wyniki mówią przede wszystkim o tych, którzy kliknęli i dokończyli formularz. To nie dyskwalifikuje badania, ale zmienia sposób interpretacji. W praktyce oznacza to, że trzeba rozróżnić opis próby od wniosków o szerszej grupie.
- Jeśli celem była diagnoza problemu, szukam wzorców odpowiedzi, a nie wyłącznie procentów.
- Jeśli celem było porównanie grup, sprawdzam, czy podział ma sens i czy podgrupy nie są zbyt małe.
- Jeśli pytanie było wieloznaczne, nie interpretuję wyniku zbyt dosłownie, bo problem często leży w konstrukcji pytania.
- Jeśli ankieta miała skalę czasu lub intensywności, patrzę na rozkład odpowiedzi, a nie tylko na sumę punktów.
Gdy ten kontekst jest jasny, dopiero wtedy warto wejść w sam plik z danymi i zacząć porządkowanie odpowiedzi. To właśnie tam rozstrzyga się, czy dalej pracuję na rzetelnym materiale, czy na zbiorze pełnym szumu.
Jak uporządkować dane, żeby nie psuły interpretacji
Surowe odpowiedzi prawie nigdy nie są gotowe do analizy. Pojawiają się duplikaty, brakujące wartości, literówki w kategoriach, odmienne zapisy tej samej odpowiedzi i pytania wielokrotnego wyboru zakodowane w sposób, który utrudnia dalszą pracę. Jeśli pracuję w Pythonie, zwykle robię to w pandas, bo łatwo sprawdzić brakujące pola, znormalizować wartości i szybko policzyć podstawowe rozkłady.
W praktyce przygotowanie danych wygląda jak seria małych porządków, które razem robią ogromną różnicę. Najpierw usuwam oczywiste duplikaty, potem ujednolicam nazwy kategorii, a następnie osobno opisuję pytania zamknięte, wielokrotnego wyboru i otwarte. Ważne jest też zapisanie słownika kodów, bo bez niego po kilku dniach trudno odtworzyć, dlaczego dana odpowiedź trafiła do konkretnej kategorii.
| Problem w danych | Co robię | Dlaczego to ważne |
|---|---|---|
| Duplikaty odpowiedzi | Sprawdzam identyfikator, czas wypełnienia i powtarzające się rekordy | Jedna osoba nie powinna liczyć się dwa razy bez uzasadnienia |
| Różne zapisy tej samej kategorii | Ujednolicam nazwy i mapuję je do jednego kodu | Unikam sztucznego rozbijania jednej odpowiedzi na kilka wariantów |
| Braki danych | Oznaczam puste pola zamiast wypełniać je na siłę | Nie zaniżam jakości badania i nie tworzę fałszywych wartości |
| Pytania otwarte | Tworzę wstępne kategorie i przypisuję odpowiedzi do tematów | Dzięki temu da się je porównać, a nie tylko przeczytać pojedynczo |
| Pytania wielokrotnego wyboru | Rozbijam je na osobne flagi binarne | Łatwiej policzyć odsetki i zrobić tabele krzyżowe |
Tu warto być bezlitosnym dla własnego pliku. Czasem jedna źle zakodowana kolumna potrafi zniszczyć cały wniosek, a błąd nie jest widoczny od razu, tylko dopiero po zrobieniu wykresu. Dlatego porządek danych traktuję jako część interpretacji, nie jako nudny wstęp do właściwej pracy.
Jak czytać odpowiedzi zamknięte, skale i segmenty
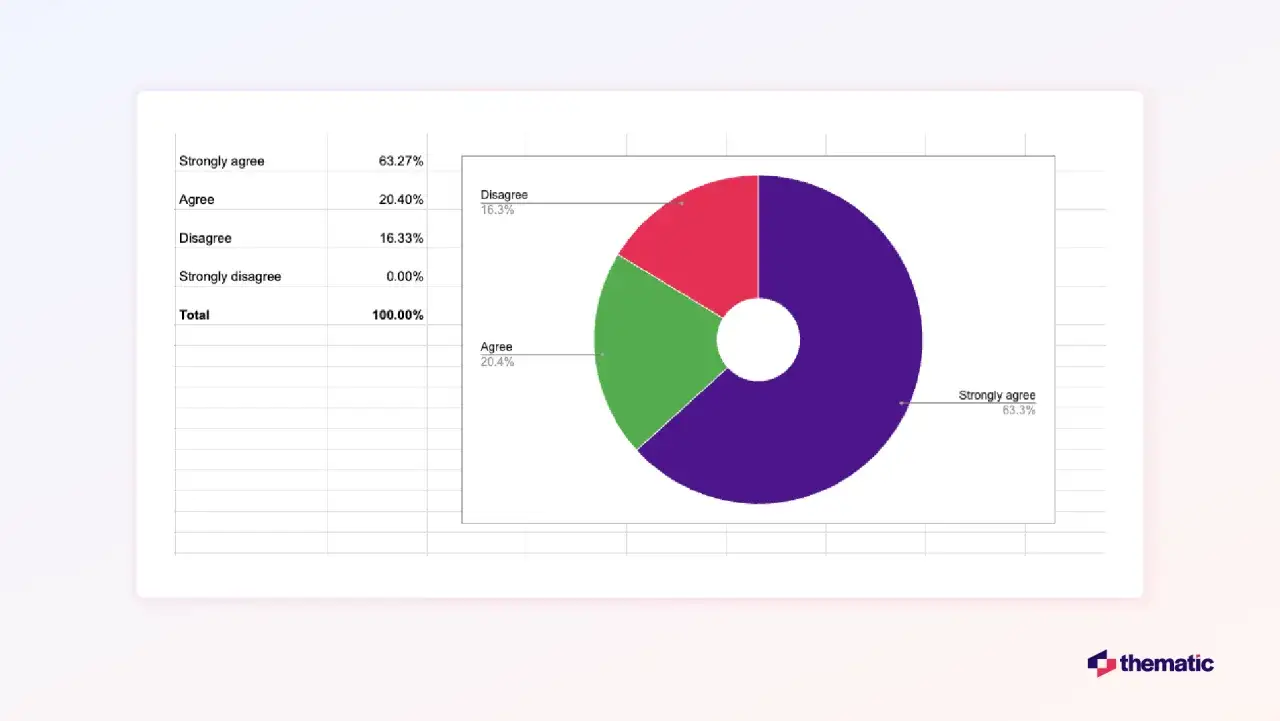
W pytaniach zamkniętych najłatwiej wpaść w pułapkę jednej liczby. Średnia wygląda elegancko, ale nie zawsze coś mówi. Jeśli odpowiedzi są mocno rozjechane, mediana bywa uczciwsza. Jeśli pytanie dotyczy wyboru jednej opcji, ważniejszy będzie odsetek odpowiedzi niż średnia. A jeśli mówimy o skali Likerta, sam wynik zbiorczy bez rozkładu odpowiedzi potrafi ukryć konflikt między grupami.
Ja zwykle patrzę na trzy poziomy naraz: odpowiedź łączną, segmenty i kontekst metryczki. To właśnie segmenty pokazują, gdzie wynik naprawdę się zmienia. Czasem ogólny poziom zadowolenia wygląda stabilnie, ale po rozbiciu na wiek, staż lub typ klienta okazuje się, że jedna grupa jest wyraźnie niezadowolona. Taki detal jest dużo cenniejszy niż ładny ogólny procent.
| Miara | Kiedy ją stosuję | Na co uważam |
|---|---|---|
| Średnia | Przy skali liczbowej, gdy rozkład nie jest skrajnie skośny | Może być zawyżona przez kilka bardzo wysokich lub bardzo niskich ocen |
| Mediana | Gdy chcę pokazać typową odpowiedź | Nie pokazuje pełnego rozkładu, więc nie wystarcza sama |
| Odsetek | Przy pytaniach jednokrotnego wyboru i skali zgodności | Nie mówi nic o intensywności odpowiedzi |
| Tabela krzyżowa | Gdy porównuję grupy według wieku, roli, lokalizacji lub stażu | W małych podgrupach łatwo przeczytać wynik zbyt dosłownie |
Jeśli w podgrupie mam mniej niż 30 odpowiedzi, traktuję procenty ostrożnie. Przy tak małym n rozbieżność kilku punktów procentowych może być zwykłym szumem, a nie realną różnicą. To nie znaczy, że wynik jest bezużyteczny. Oznacza tylko, że trzeba go opisać jako sygnał, nie jako twardy fakt.
Warto też pamiętać, że skale ocen nie zawsze są symetryczne w odbiorze. Dla części osób 3 na 5 oznacza neutralność, dla innych umiarkowane zadowolenie. Dlatego przy interpretacji nie zatrzymuję się na jednej statystyce, tylko patrzę, jak odpowiedzi rozkładają się wokół środka. Wtedy widać, czy wynik jest naprawdę stabilny, czy tylko wygląda dobrze na papierze.
Kiedy liczby są już przeczytane we właściwy sposób, można przejść do odpowiedzi opisowych. I tu właśnie AI zaczyna mieć największy sens, ale tylko wtedy, gdy jest dobrze użyta.
Pytania otwarte i gdzie AI daje realną przewagę
W pytaniach otwartych nie interesuje mnie pojedynczy cytat, tylko powtarzające się tematy. To obszar, w którym AI naprawdę może pomóc, bo świetnie radzi sobie z grupowaniem podobnych wypowiedzi, skracaniem długich komentarzy i wyłapywaniem powtarzalnych motywów. Nie ufam jej jednak w roli arbitra prawdy. Model może zaproponować sensowną kategorię, ale to człowiek decyduje, czy ta kategoria rzeczywiście jest spójna z badaniem.
Mój sprawdzony układ pracy wygląda tak: najpierw anonimowo zapisuję odpowiedzi, potem przeglądam pierwsze 30-50 komentarzy i buduję wstępny słownik kodów, a dopiero później proszę model o przypisywanie kolejnych wypowiedzi do tematów. Na końcu sprawdzam losową próbkę, zwykle 10-20% materiału, żeby zobaczyć, czy model nie zaczął nadużywać jednego kodu albo nie zignorował niuansów językowych.
| Podejście | Plusy | Minusy | Kiedy ma sens |
|---|---|---|---|
| Ręczne kodowanie | Największa kontrola nad znaczeniem odpowiedzi | Powolne i męczące przy większym zbiorze | Przy małych ankietach i bardzo wrażliwych tematach |
| AI wspierająca kodowanie | Szybkie grupowanie podobnych wypowiedzi | Ryzyko błędnych etykiet i zbyt gładkich uogólnień | Przy setkach odpowiedzi otwartych, gdy potrzebna jest szybkość |
| Podejście hybrydowe | Łączy tempo AI z kontrolą człowieka | Wymaga procesu i dyscypliny | W większości projektów, zwłaszcza cyklicznych |
Największe ryzyko po stronie AI to nie tylko błąd klasyfikacji, ale też zbyt pewny ton odpowiedzi. Model potrafi brzmieć przekonująco nawet wtedy, gdy robi skrót myślowy, którego nie da się obronić na danych. Dlatego każdą automatyczną etykietę traktuję jak propozycję, nie jak decyzję. Druga rzecz to prywatność: przed przekazaniem danych do modelu trzeba usunąć imiona, numery, adresy i wszystko, co może identyfikować respondenta.
Jeśli pytania otwarte zawierają ironię, skróty myślowe albo emocjonalne uwagi, AI bywa lepsza w grupowaniu niż w interpretacji tonu. Na przykład komentarz „super, jeśli ktoś lubi czekać tydzień na odpowiedź” może zostać uznany za pozytywny, jeśli model nie złapie ironii. Tego typu pułapki najlepiej wychodzą dopiero przy ręcznej kontroli próbki.

Jak Python i automatyzacja przyspieszają pracę analityczną
W ekosystemie Pythona analizę ankiet można zorganizować naprawdę sensownie. pandas świetnie nadaje się do czyszczenia i agregacji danych, seaborn i plotly pomagają budować czytelne wykresy, a scikit-learn przydaje się wtedy, gdy chcę grupować odpowiedzi lub szukać podobieństw między komentarzami. Do analizy tekstu dochodzą też narzędzia NLP, na przykład do prostego tokenizowania, lematyzacji i liczenia częstości słów.
Największa przewaga nie leży jednak w samych bibliotekach, tylko w powtarzalności procesu. Jeśli badanie wraca co miesiąc albo co kwartał, dobrze napisany notebook lub skrypt może za każdym razem wygenerować te same tabele, te same wykresy i ten sam układ raportu. Dzięki temu nie muszę ręcznie odtwarzać pracy od zera. Zamiast tego aktualizuję tylko dane wejściowe i kontroluję wyjątki.
- Do czyszczenia danych używam pandas, bo najłatwiej wychwycić duplikaty, braki i literówki.
- Do wizualizacji wybieram wykresy słupkowe, liniowe i heatmapy, bo najszybciej pokazują różnice między grupami.
- Do automatycznego streszczania odpowiedzi otwartych mogę użyć modelu AI, ale tylko na danych zanonimizowanych.
- Do cyklicznych raportów warto zapisać cały proces w notebooku albo skrypcie, zamiast klikać wszystko ręcznie.
Tu dobrze widać, że AI i Python się uzupełniają, ale nie zastępują. Python utrzymuje porządek w procesie, a model językowy przyspiesza pracę nad tekstem i wspiera wstępne porządkowanie sensów. Jeśli ktoś próbuje oddać modelowi pełną odpowiedzialność za wnioski, zwykle kończy z ładnym raportem i słabą obroną metodologiczną.
W praktyce najbardziej cenię rozwiązania, które dają ślad audytowy: wiadomo, skąd pochodzi każdy wynik, jaką miał postać przed obróbką i kto zatwierdził końcową interpretację. To jest szczególnie ważne, gdy raport trafia do zespołu produktowego, zarządu albo do publikacji.
Jak przełożyć wyniki na raport, który da się obronić
Dobre raportowanie nie polega na zrzuceniu wykresów do prezentacji. Ja układam wnioski w schemat: co wyszło, dlaczego to ważne i co z tego wynika dla decyzji. Taki porządek sprawia, że odbiorca nie musi samodzielnie zgadywać, które obserwacje są istotne, a które są tylko ozdobą.
Najlepiej działają wnioski zapisane jako krótkie, konkretne zdania. Na przykład: „Najmniej zadowolona grupa to nowi użytkownicy, bo wskazują na trudny start” jest dużo lepsze niż ogólne „wyniki są zróżnicowane”. W pierwszym zdaniu widać problem, interpretację i kierunek działania. W drugim nie ma właściwie nic poza sygnałem, że coś trzeba jeszcze przeczytać.
- Najpierw pokazuję rozkład odpowiedzi i najważniejsze segmenty.
- Potem tłumaczę, co z tego wynika dla procesu, produktu albo komunikacji.
- Na końcu zapisuję rekomendację z priorytetem, właścicielem i zakresem działania.
Wizualizacje też muszą pracować na wniosek, a nie przeciwko niemu. Jeśli wykres jest zbyt ozdobny, odbiorca traci sens danych. Jeśli ma zbyt wiele kategorii, trzeba go uprościć. Jeśli pokazuję porównanie grup, oś i skala muszą być uczciwe. Nie lubię wykresów, które wyglądają efektownie, ale zmieniają odbiór różnic przez nietrafioną skalę albo przypadkowy układ legendy.
W raporcie dobrze działa też krótka sekcja „co dalej”. To może być lista działań na 2-4 tygodnie, a nie ogólna obietnica poprawy. Im bardziej konkretne są rekomendacje, tym większa szansa, że ktoś naprawdę je wykorzysta. Bez tego nawet trafna interpretacja rozmywa się po pierwszym spotkaniu.
Na co sprawdzam jeszcze przed oddaniem wniosków
Zanim zamknę raport, robię ostatni przegląd metodologiczny. Sprawdzam, czy każda interpretacja wynika z danych, czy tylko dobrze brzmi, czy małe podgrupy nie zostały potraktowane jak cały rynek i czy AI nie wygładziła zbyt mocno języka wniosków. Dobra analiza ankiety nie kończy się na tabelach, tylko na decyzjach, które da się obronić przed zespołem i przed samym sobą.
- Czy wnioski wynikają z danych, a nie z intuicji autora?
- Czy nie pomyliłem korelacji z przyczyną?
- Czy małe segmenty są opisane ostrożnie i bez nadmiernej pewności?
- Czy odpowiedzi otwarte zachowały sens po kodowaniu i skracaniu?
- Czy raport jasno pokazuje, co należy zrobić jako następny krok?
Jeśli odpowiedź na te pytania brzmi „tak”, materiał jest gotowy do użycia. Jeśli nie, wolę poprawić go od razu, zamiast później tłumaczyć się z wniosku, który wyglądał dobrze tylko na pierwszym slajdzie. Przy powtarzalnych badaniach największą przewagę daje prosty, konsekwentny proces: czyszczenie danych, kontrola jakości, interpretacja, a dopiero potem automatyzacja i AI. To właśnie taki układ sprawia, że kolejne badania są szybsze i bardziej wiarygodne.