Najkrótsza droga do zrozumienia regresji liniowej
- To metoda, która opisuje zależność między zmienną objaśnianą a jedną lub wieloma cechami wejściowymi.
- Jej siła leży w prostocie: daje czytelne współczynniki, łatwe do interpretacji w analizie danych i projektach AI.
- Najważniejsze założenia to w przybliżeniu liniowy związek, stabilna wariancja błędów i brak silnych problemów z obserwacjami odstającymi.
- W Pythonie do predykcji zwykle wybiera się `scikit-learn`, a do analizy statystycznej i raportowania parametrów często `statsmodels`.
- Jako punkt odniesienia w projektach AI regresja liniowa świetnie pokazuje, czy bardziej złożony model naprawdę wnosi wartość.
Na czym polega regresja liniowa i kiedy ma sens
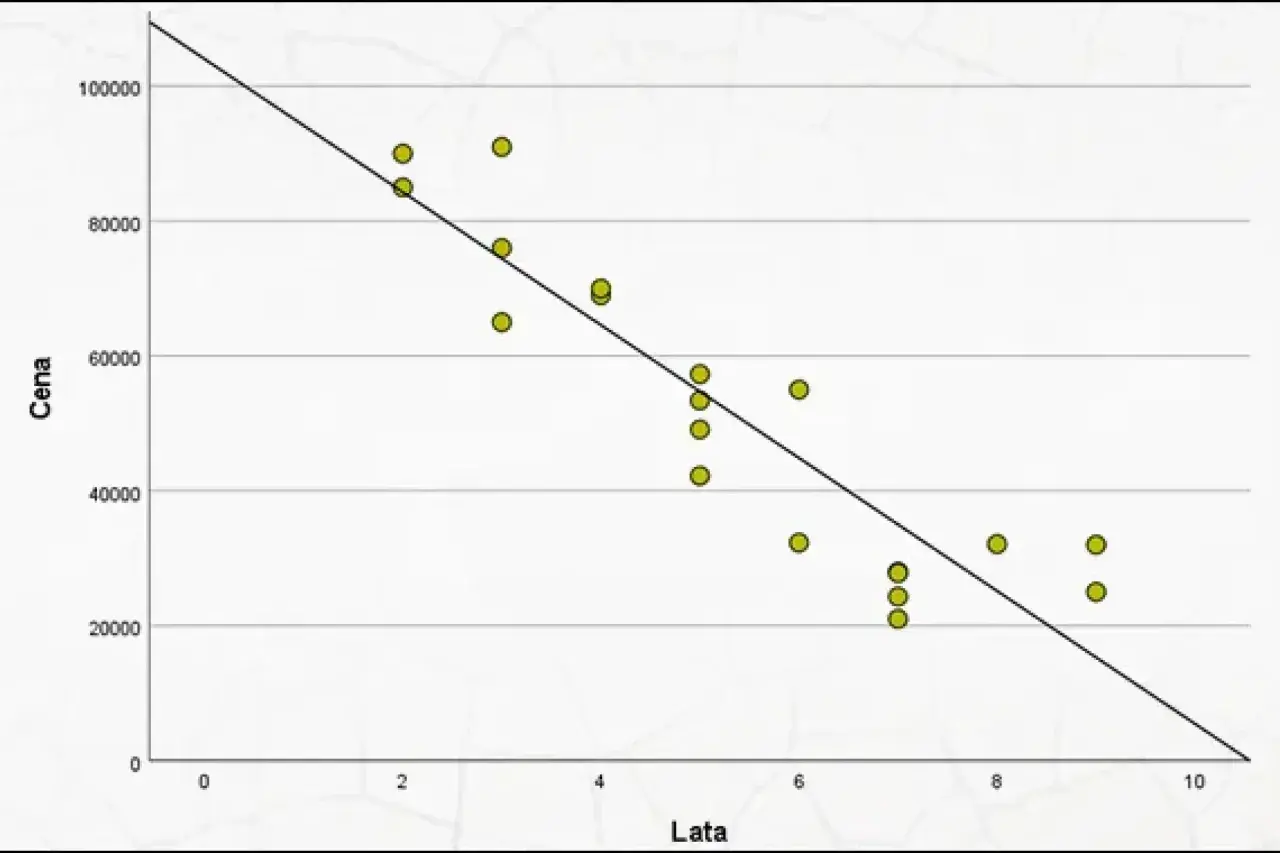
Najkrócej mówiąc, regresja liniowa próbuje opisać zależność w formie prostej funkcji. Jeśli jedna zmienna rośnie, druga też może rosnąć albo maleć, a model stara się uchwycić ten trend możliwie najdokładniej. Dla jednej cechy wejściowej dostajemy regresję prostą, a dla wielu cech - regresję wieloraką, czyli uogólnienie tego samego pomysłu.
W praktyce patrzę na to tak: jeżeli wykres punktowy sugeruje choć w przybliżeniu prostą zależność, ten model bywa bardzo dobrym pierwszym krokiem. Działa szczególnie dobrze wtedy, gdy zależność jest czytelna, dane nie są skrajnie zaszumione, a celem jest szybka, interpretowalna prognoza. To właśnie dlatego regresja liniowa tak często pojawia się na początku pracy z analizą danych i AI - nie dlatego, że jest najpotężniejsza, tylko dlatego, że jest przewidywalna i uczciwa wobec danych.
Matematycznie można to zapisać w uproszczeniu jako y = b0 + b1x1 + b2x2 + ... + e, gdzie model próbuje dobrać współczynniki tak, by błędy predykcji były jak najmniejsze. Gdy ten obraz się zgadza, dopiero wtedy warto przejść do interpretacji współczynników.
Jak czytać wzór i współczynniki
Najwięcej nieporozumień bierze się nie z samego dopasowania, ale z interpretacji wyniku. Sam fakt, że model zwraca liczby, nie znaczy jeszcze, że od razu wiadomo, co one mówią o danych. Ja zawsze rozbijam wynik na kilka prostych elementów:
| Element | Co oznacza | Na co uważać |
|---|---|---|
| Wyraz wolny | Przewidywana wartość, gdy wszystkie cechy mają wartość 0 | Nie zawsze ma sens biznesowy, zwłaszcza gdy „zero” nie występuje naturalnie w danych |
| Współczynnik przy cesze | O ile zmieni się wynik, gdy dana cecha wzrośnie o 1 jednostkę, przy pozostałych cechach stałych | Interpretacja działa sensownie tylko wtedy, gdy cechy nie są mocno ze sobą splecione |
| Reszta | Różnica między wartością rzeczywistą a przewidywaną | Jeśli reszty układają się w wzór, model czegoś nie widzi |
| R² | Jaki fragment zmienności danych wyjaśnia model | Wysokie R² nie gwarantuje, że model dobrze generalizuje poza próbką |
Jeśli pracujesz w `statsmodels`, zobaczysz zwykle także błędy standardowe i wartości `p-value`. To przydatne przy wnioskowaniu statystycznym, ale nie wolno mylić tego z pełną oceną jakości predykcji. Z kolei w projektach stricte predykcyjnych ważniejsze bywa to, czy model dobrze radzi sobie na danych testowych, niż to, jak imponująco wygląda jego tabela wyników.
Właśnie dlatego samo czytanie liczb nie wystarczy, jeśli po drodze łamane są założenia modelu. A to prowadzi do części, którą zbyt wiele osób pomija zbyt wcześnie.
Założenia, które decydują o jakości wniosków
Regresja liniowa nie jest kapryśna, ale ma konkretne warunki działania. Jeśli je ignorujesz, wynik nadal może wyglądać „ładnie”, tylko że przestaje być wiarygodny. Ja najpierw sprawdzam te punkty:
- Liniowość - zależność między cechą a wynikiem powinna być w przybliżeniu prostoliniowa. Jeśli widać krzywiznę, model może systematycznie się mylić.
- Niepodobieństwo reszt do wzoru - błędy powinny rozrzucać się przypadkowo. Jeżeli widać pasma albo łuk, model nie łapie pełnej struktury danych.
- Stała wariancja błędów - rozrzut reszt nie powinien rosnąć wraz z poziomem predykcji. Gdy tak się dzieje, pojawia się heteroscedastyczność.
- Niezależność obserwacji - szczególnie ważna w danych czasowych i szeregach zdarzeń. Jeżeli próbki wpływają na siebie, wyniki mogą być zbyt optymistyczne.
- Brak silnej współliniowości - jeśli cechy mocno się powielają, współczynniki stają się niestabilne i trudne do zaufania.
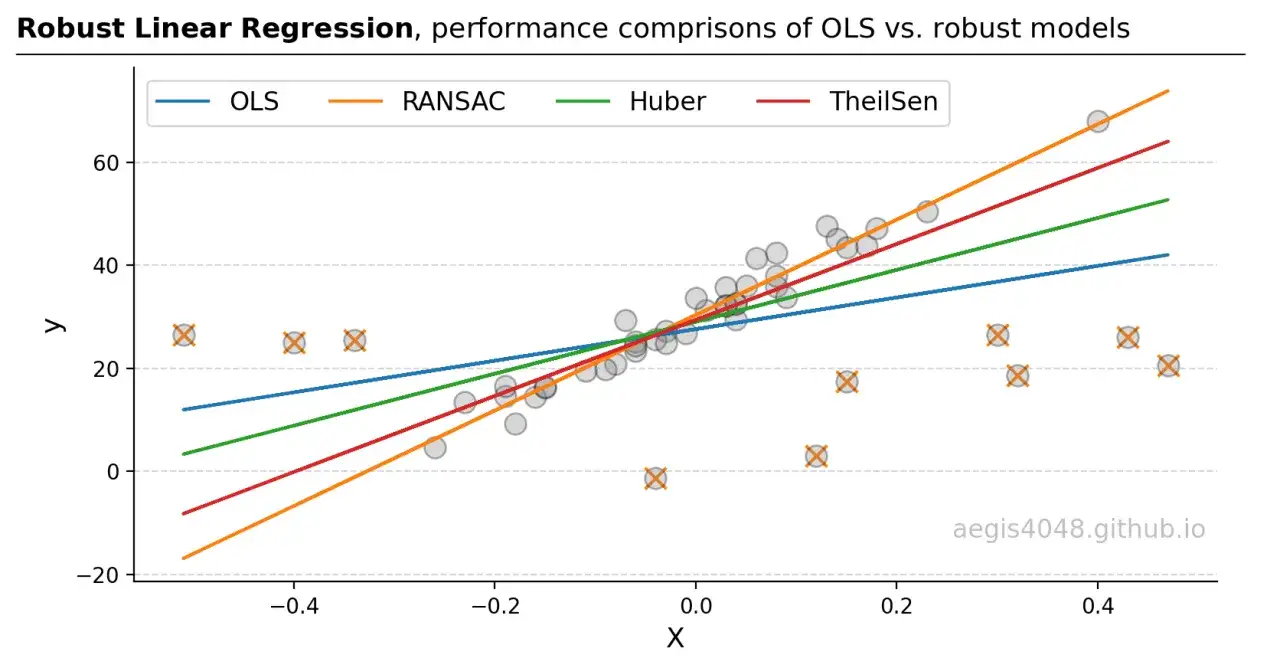
- Umiarkowana liczba obserwacji odstających - pojedyncze ekstremalne punkty potrafią przesunąć prostą bardziej, niż się wydaje.
W praktyce nie każda analiza wymaga perfekcyjnego spełnienia wszystkich założeń. Jeśli celem jest szybka predykcja, część z nich ma znaczenie głównie diagnostyczne. Jeśli jednak chcesz wyciągać wnioski o wpływie zmiennych, rygor rośnie i warto potraktować diagnostykę bardzo serio.
Dopiero po takim sprawdzeniu ma sens przejście do implementacji. W Pythonie różnica między narzędziami jest prostsza, niż zwykle się ją przedstawia.
Jak zbudować taki model w Pythonie
W Pythonie najczęściej wybieram jedno z dwóch podejść. `scikit-learn` daje wygodny workflow do predykcji i walidacji, a `statsmodels` lepiej sprawdza się wtedy, gdy zależy mi na pełnym raporcie statystycznym. To nie jest konflikt narzędzi, tylko różnica celu.
| Narzędzie | Najlepsze zastosowanie | Co dostajesz |
|---|---|---|
| `scikit-learn` | Budowa modeli predykcyjnych, pipeline'y, testy i walidacja krzyżowa | Prosty interfejs `fit` / `predict`, łatwe łączenie z preprocessingiem |
| `statsmodels` | Analiza statystyczna, interpretacja współczynników, testy istotności | Rozbudowane podsumowanie, błędy standardowe, p-value, diagnostyka |
Najprostszy przepływ pracy wygląda tak:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)W praktyce dorzucam jeszcze preprocessing, jeśli cechy mają bardzo różne skale albo jeśli planuję później testować modele regularizowane. Wtedy `Pipeline` i `StandardScaler` są rozsądniejszym wyborem niż ręczne, chaotyczne przetwarzanie danych. Przy `statsmodels` pamiętaj też o stałej - tam często trzeba dodać ją jawnie, bo biblioteka nie zrobi tego za Ciebie automatycznie.
Model już działa, ale dopiero ocena na danych, których wcześniej nie widział, mówi, czy naprawdę nadaje się do użycia. I tutaj warto oprzeć się na kilku metrykach naraz, a nie jednej wygodnej liczbie.
Jak ocenić, czy model naprawdę działa
Jedna metryka rzadko daje pełny obraz. Ja zwykle patrzę równocześnie na błąd, dopasowanie i zachowanie reszt. Przy modelach liniowych to szczególnie ważne, bo ich prostota bywa zaletą tylko wtedy, gdy nie maskuje zbyt dużych uproszczeń.
| Metryka | Co mówi | Kiedy uważać |
|---|---|---|
| MAE | Średni bezwzględny błąd prognozy | Nie pokazuje, jak bardzo model myli się w najgorszych przypadkach |
| RMSE | Silniej karze duże pomyłki | Jest bardziej wrażliwy na outliery niż MAE |
| R² | Pokazuje, ile zmienności danych wyjaśnia model | Nie mówi wprost, czy prognoza jest stabilna poza zbiorem treningowym |
| Walidacja krzyżowa | Sprawdza, czy wynik utrzymuje się na różnych podziałach danych | Przy małych zbiorach pojedynczy split 80/20 może być zbyt losowy |
Jeśli model nie przebija prostego baseline'u, na przykład przewidywania średniej, to sygnał ostrzegawczy. W projektach danych i AI widzę to często: ktoś buduje złożony model, ale nie porównał go z banalnym punktem odniesienia. To błąd strategiczny, bo bez baseline'u nie wiadomo, czy model dodaje cokolwiek ponad przypadkową lub naiwną prognozę.
Na końcu i tak sprowadza się to do pytania: kiedy prosta regresja wygrywa, a kiedy lepiej przejść do czegoś mocniejszego? Tu różnica jest bardzo praktyczna i szybko wychodzi w danych.
Kiedy prosty model wystarcza, a kiedy lepiej wybrać coś innego
Regresja liniowa świetnie sprawdza się wtedy, gdy zależność jest zbliżona do liniowej, a priorytetem jest interpretowalność. To dobry wybór w analizach biznesowych, przy pierwszych wersjach modeli predykcyjnych i jako baseline w projektach AI. Właśnie jako punkt startowy daje najwięcej wartości za najmniejszy koszt obliczeniowy i poznawczy.
| Sytuacja | Jak wypada regresja liniowa | Co rozważyć zamiast niej |
|---|---|---|
| Prosta, prawie liniowa zależność | Bardzo dobry wybór | Nie trzeba od razu komplikować modelu |
| Silne nieliniowości i progi decyzyjne | Bywa zbyt sztywna | Drzewa decyzyjne, random forest, gradient boosting |
| Wiele skorelowanych cech | Współczynniki robią się niestabilne | Ridge lub Lasso |
| Dużo obserwacji odstających | Jest wrażliwa na ekstremalne punkty | Transformacje zmiennych, regresja odporna |
| Potrzeba bardzo dokładnej prognozy z zawiłych danych | Często przegrywa z bardziej elastycznymi metodami | Modele zespołowe albo głębsze podejścia ML |
Ja zwykle zaczynam od prostego modelu nie dlatego, że oczekuję od niego cudu, tylko dlatego, że chcę mieć uczciwy punkt odniesienia. Jeśli prosty wariant już działa dobrze, nie ma sensu dokładać komplikacji dla samej komplikacji. Jeśli nie działa, łatwiej zrozumieć, czy problem leży w danych, w cechach, czy po prostu w zbyt dużym uproszczeniu.
Najważniejsze jest więc nie to, czy metoda brzmi nowocześnie, ale czy daje wynik, który da się obronić na danych, biznesowo i technicznie. Z tego właśnie powodu dobrze dopasowana regresja nadal pozostaje jednym z najpraktyczniejszych narzędzi w analizie danych.
Co sprawdzam, zanim uznam prognozę za gotową
- Sprawdzam wykres rozrzutu i reszt, żeby zobaczyć, czy model nie gubi oczywistego trendu.
- Porównuję wynik z baseline'em, bo dopiero wtedy wiem, czy model rzeczywiście coś wnosi.
- Patrzę na stabilność współczynników, zwłaszcza gdy cechy są podobne do siebie albo mocno skorelowane.
- Weryfikuję, czy cechy mają sens biznesowy, a nie tylko statystyczny.
- Testuję model na danych z innego okresu, jeśli prognoza ma działać w czasie, a nie tylko na jednym zestawie historycznym.
Jeśli te warunki są spełnione, prosty model daje bardzo solidny fundament do dalszej pracy. Jeśli nie są, zwykle nie pomaga kosmetyka, tylko zmiana cech, transformacja danych albo przejście do bardziej elastycznej metody. I właśnie to jest w regresji liniowej najbardziej wartościowe: szybko pokazuje, gdzie kończy się prostota, a zaczyna realny problem danych.