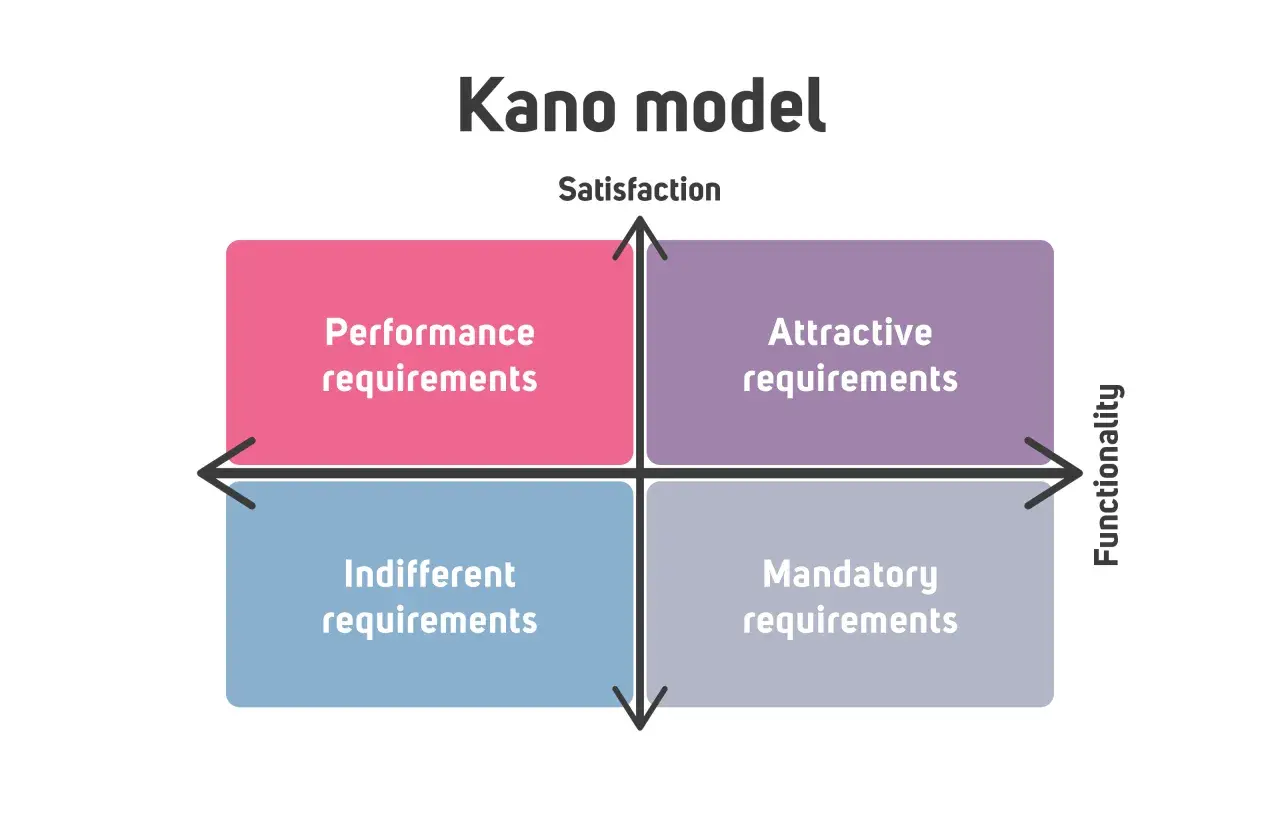
W projektowaniu interfejsów najłatwiej przepalić czas na funkcje, które wyglądają dobrze w roadmapie, ale prawie nie ruszają satysfakcji użytkownika. Model Kano pomaga odróżnić elementy podstawowe, oczekiwane, zachwycające i obojętne, dzięki czemu łatwiej ustawić priorytety w UX/UI, front-endzie i pracy produktowej. W praktyce to bardzo przydatne narzędzie, gdy trzeba zdecydować, co dowieźć najpierw, co dopracować później, a co po prostu wyciąć.
Model Kano porządkuje priorytety w UX i frontendzie
- Nie każda funkcja daje ten sam zwrot. Podstawy usuwają frustrację, a dopiero kolejne poziomy budują przewagę.
- Najlepiej działa przy decyzjach o backlogu. Szczególnie tam, gdzie trzeba wybrać między wydajnością, poprawą UX i efektem wow.
- Badanie opiera się na parach pytań. Dla każdej cechy pytasz o obecność i brak, a potem klasyfikujesz odpowiedzi.
- W interfejsach cyfrowych oczekiwania szybko się zmieniają. To, co kiedyś było zachwytem, dziś bywa podstawą.
- Model nie zastępuje testów użyteczności ani analityki. Dobrze działa jako filtr priorytetów, nie jako jedyne źródło prawdy.
Czym jest model Kano i dlaczego dobrze działa w UX/UI
Ja traktuję go przede wszystkim jako sposób na uporządkowanie rozmowy o produkcie. Nie pyta on tylko „czy użytkownik coś lubi”, ale „jak mocno zmienia się jego odczucie, gdy dana cecha istnieje albo znika”.
To ważne w UX/UI, bo interfejs nie składa się z jednego typu decyzji. Inaczej działa kontrast i dostępność, inaczej prędkość ładowania, a jeszcze inaczej mała animacja potwierdzająca zapis. Właśnie dlatego model dobrze pasuje do front-endu: pomaga rozdzielić bazowe oczekiwania od elementów, które realnie podnoszą satysfakcję.
W praktyce widzę tu trzy poziomy myślenia. Po pierwsze, rzeczy, bez których użytkownik się frustruje. Po drugie, elementy, których jakość rośnie razem z satysfakcją. Po trzecie, detale, które budują przyjemność, ale nie są jeszcze obowiązkowe. Dopiero wtedy widać, które odpowiedzi są naprawdę użyteczne dla zespołu.
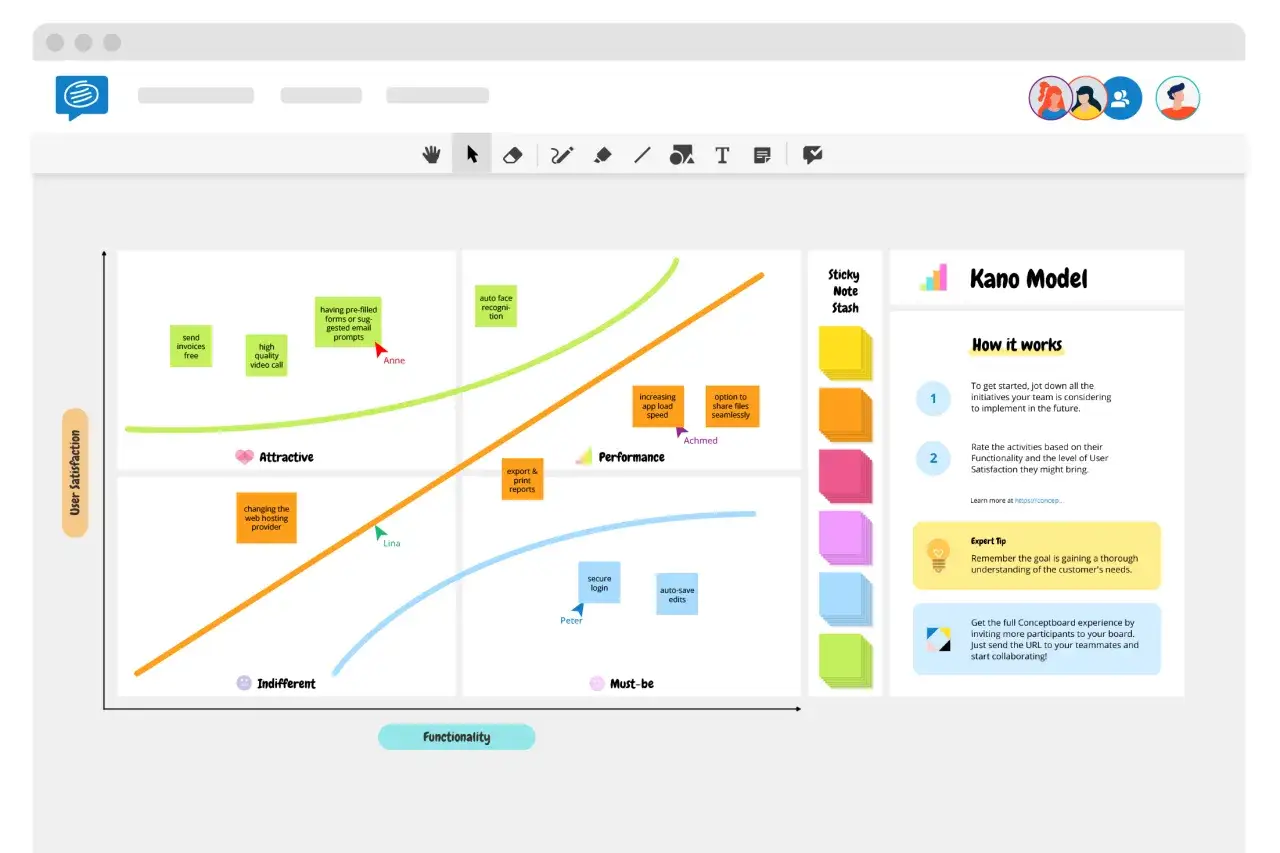
Jak działa klasyfikacja cech w badaniu Kano
Mechanika jest prosta, ale tylko wtedy, gdy pytania są dobrze sformułowane. Dla każdej cechy przygotowuję dwa pytania: jedno o sytuację, w której funkcja istnieje, drugie o sytuację, w której jej nie ma. Dzięki temu badanie nie opiera się na ogólnym wrażeniu, tylko na reakcji na konkretny wariant interfejsu.
Jak formułować pytania
W praktyce pytanie musi być konkretne i jednoznaczne. Zamiast pytać o „lepszy UX”, pytam na przykład: „Jak byś się czuł, gdyby formularz zapisywał szkic automatycznie?” i w parze z nim: „Jak byś się czuł, gdyby formularz nie zapisywał szkicu?”. Tak samo można sprawdzać walidację, podpowiedzi, kolejność kroków, stan pusty czy skróty klawiaturowe.
W odpowiedziach zwykle stosuje się pięciostopniową skalę: lubię to, oczekuję tego, mam neutralny stosunek, mogę to tolerować, nie podoba mi się. Taki zestaw jest prosty, ale daje wystarczająco dużo sygnału, żeby odróżnić brak frustracji od realnego zachwytu.
Przeczytaj również: Badania UX w Frontendzie - Jak naprawdę poprawiają produkt?
Jak czytać odpowiedzi
| Kategoria | Co oznacza | Przykład z interfejsu | Co z tym zrobić |
|---|---|---|---|
| Podstawowa (must-be) | Brak frustruje, obecność jest tylko normalna | walidacja formularza, dostępność klawiaturą, jasny komunikat błędu | najpierw zabezpiecz tę warstwę |
| Wydajnościowa (performance) | Im lepsza, tym większa satysfakcja | szybkość ładowania, precyzja wyszukiwania, płynność filtrowania | optymalizuj konsekwentnie |
| Zachwycająca (attractive) | Pozytywne zaskoczenie, którego użytkownik nie wymaga | autosave szkicu, inteligentna podpowiedź, sprytne skróty | dodawaj dopiero po opanowaniu podstaw |
| Obojętna (indifferent) | Użytkownik prawie nie reaguje | ozdobna animacja bez funkcji, dekoracyjny detal bez wpływu na zadanie | usuń albo zrób tanio |
| Odwrócona (reverse) | Obecność przeszkadza i obniża satysfakcję | autoplay, nachalne wyskakujące okna, zbyt agresywny onboarding | eliminuj bez sentymentu |
| Wątpliwa (questionable) | Odpowiedzi są sprzeczne albo nielogiczne | badani różnie rozumieją pytanie lub kontekst | popraw pytanie, nie wyciągaj wniosku na siłę |
Ten obraz klasyfikacji jest użyteczny tylko wtedy, gdy pytania dotyczą jednego konkretnego zachowania, a nie całego „dobrego UX”. Dopiero taki obraz pozwala sensownie przejść od teorii do pracy nad backlogiem i makietą.
Jak przeprowadzić analizę krok po kroku w zespole frontendowym
W zespole frontendowym analizę prowadzę w sześciu prostych krokach. Najpierw wybieram konkretny obszar: formularz płatności, onboarding, wyszukiwarkę albo panel użytkownika. Potem spisuję 10–15 cech, które naprawdę mogą wpłynąć na odczucia użytkownika. Nie robię z tego listy życzeń bez końca, bo przy zbyt dużej liczbie pytań ankieta szybko traci jakość.
- Wybierz jeden proces, a nie cały produkt. Na start lepszy jest koszyk, zapis danych albo logowanie niż abstrakcyjne „ulepszenie aplikacji”.
- Zapisz cechy jako konkretne zachowania interfejsu. Zamiast „lepsze UX” użyj „automatyczny zapis szkicu”, „czytelna walidacja”, „powrót do poprzedniego kroku bez utraty danych”.
- Przygotuj pary pytań funkcjonalnych i dysfunkcjonalnych. Każda cecha dostaje dwa pytania, żeby widać było reakcję na obecność i brak.
- Dobierz właściwy segment użytkowników. Inne oczekiwania ma osoba początkująca, inne power user, a jeszcze inne klient administrujący systemem.
- Zbierz odpowiedzi i oddziel opinie jakościowe od ilościowych. Do rozmów wstępnych wystarcza mi zwykle 8–12 osób z ważnego segmentu, ale przy ankiecie chcę już widzieć wyraźny trend, więc celuję w kilkadziesiąt odpowiedzi na segment.
- Przełóż wynik na backlog. Najpierw napraw braki podstawowe, potem optymalizuj wydajność, a dopiero później inwestuj w zachwycające dodatki.
Jeśli mam zespół produktowy, zwykle stawiam jedną zasadę: nie dyskutujemy o „ładniejszych” rozwiązaniach, dopóki nie wiemy, czy użytkownik w ogóle ma stabilny, przewidywalny przepływ. Gdy już masz te dane, prawdziwa wartość pojawia się dopiero wtedy, gdy przekładasz je na decyzje priorytetowe.
Jak czytać wyniki i zamieniać je w decyzje produktowe
Wyniki czytam zawsze przez pryzmat decyzji, nie ciekawostek. Podstawowe rzeczy naprawiam najpierw, bo bez nich użytkownik się wykłada. Wydajnościowe poprawiam konsekwentnie, bo tam każda sekunda, kliknięcie albo błąd mają wpływ na satysfakcję. Zachwycające dodatki wybieram ostrożnie, bo łatwo nimi przykryć realne problemy.
- Podstawowe cechy traktuję jak warunek wejścia do rozmowy o produkcie.
- Wydajnościowe cechy optymalizuję tam, gdzie mają wpływ na główne ścieżki użytkownika.
- Zachwycające cechy dokładam wtedy, gdy fundamenty są stabilne.
- Obojętne elementy usuwam z roadmapy albo zostawiam tylko wtedy, gdy są bardzo tanie.
- Odwrócone rozwiązania eliminuję bez wahania, bo psują doświadczenie.
W produktach cyfrowych kategoria „zachwyt” starzeje się szybko. To, co kiedyś było miłym dodatkiem, po kilku iteracjach może stać się oczekiwaniem, a po roku bywa już zwykłą normą. W 2026 roku dobrze widać to choćby na przykładzie trybu ciemnego czy autosave: w jednych segmentach to nadal przewaga, w innych po prostu standard.
Dlatego nie traktuję analizy Kano jak jednorazowej ankiety, tylko jak narzędzie do okresowego odświeżania priorytetów. Jeśli użytkownik przestaje reagować na daną cechę, to nie znaczy, że produkt się pogorszył. Często po prostu zmienił się punkt odniesienia.
Przykłady z interfejsów, które dobrze pokazują różnicę między kategoriami
Najłatwiej zrozumieć to podejście na elementach, które każdy widzi w codziennym użyciu interfejsu.
- Walidacja formularza to zwykle element podstawowy. Użytkownik nie oczekuje fajerwerków, tylko jasnej informacji, co poprawić i dlaczego.
- Szybkie ładowanie ekranów działa jak cecha wydajnościowa. Im mniej czekania, tym lepsza ocena całego produktu.
- Autosave szkicu często daje efekt zachwycający, bo redukuje lęk przed utratą pracy i nie wymaga od użytkownika dodatkowego wysiłku.
- Odzyskiwanie błędu jednym kliknięciem bywa dodatkiem, który mocno wyróżnia narzędzie robocze, ale w częstym użyciu szybko przechodzi do kategorii oczekiwań.
- Ozdobne animacje bez funkcji są często obojętne. Jeśli nie wspierają celu, zwykle nie powinny kosztować zespołu dużo czasu.
- Autoodtwarzanie treści bywa wręcz odwrócone, szczególnie gdy zaburza kontrolę i czytelność.
Tu ważny jest kontekst. Ta sama cecha w aplikacji bankowej, sklepie online i narzędziu do projektowania może wylądować w innej kategorii. Dlatego nie kopiuję cudzych wniosków bez sprawdzenia własnych użytkowników. Najbardziej praktyczna zasada jest prosta: nie zakładaj, że delighter z innego produktu zadziała tak samo u ciebie.
Gdzie metoda pomaga, a gdzie trzeba zachować ostrożność
Model Kano jest użyteczny, ale nie rozwiązuje wszystkiego. Najlepiej działa, gdy zespół ma już zdefiniowaną grupę użytkowników i kilka realnych wariantów do porównania. Słabiej sprawdza się wtedy, gdy produkt dopiero szuka rynku albo gdy pytamy o rzeczy, które są już twardym wymogiem prawnym, technicznym lub dostępnościowym.
- Jeśli cecha wynika z dostępności WCAG, nie traktuję jej jak „miłego dodatku”.
- Jeśli pytanie dotyczy bardzo abstrakcyjnej funkcji, odpowiedzi będą zbyt rozmyte.
- Jeśli grupy użytkowników są mieszane, wynik może zamazać różnice między początkującymi a zaawansowanymi.
- Jeśli produkt zmienia się szybko, analiza sprzed kilku miesięcy może już nie być aktualna.
W praktyce oznacza to jedno: ta metoda dobrze porządkuje decyzje, ale nie powinna zastępować testów użyteczności, analityki zachowań ani audytu technicznego. Ja zwykle łączę ją z obserwacją drop-offów w lejku i krótkimi testami z użytkownikami, bo dopiero wtedy widać nie tylko co wybrać, ale też dlaczego użytkownik się zatrzymuje. Dzięki temu priorytet nie jest zgadywaniem, tylko logiczną konsekwencją danych.
Najczęstsze błędy przy korzystaniu z tej metody
Najczęstszy błąd to zadawanie zbyt ogólnych pytań. „Lepszy UX” niczego nie klasyfikuje, bo użytkownik nie ma czego ocenić. Drugi błąd to mieszanie wielu cech w jednym pytaniu, na przykład szybkości, wyglądu i łatwości obsługi naraz. Wtedy wynik jest ładny tylko na wykresie, a w praktyce bezużyteczny.
- Badanie opinii zespołu zamiast użytkowników daje przewidywalne, ale słabe wyniki.
- Traktowanie każdej nowości jako zachwycającej prowadzi do przeładowanego interfejsu.
- Ignorowanie cech podstawowych kończy się tym, że zespół dopieszcza detale, a użytkownik nadal walczy z formularzem.
- Nieodświeżanie badania sprawia, że roadmapa bazuje na starych oczekiwaniach.
- Projektowanie pod jedną personę pomija różnice między segmentami, które w UX są często kluczowe.
Jeśli miałbym wskazać jedną rzecz, która najbardziej poprawia jakość tej metody, to byłaby nią konkretność. Im bardziej precyzyjna cecha i bardziej jednoznaczny segment, tym lepsza decyzja projektowa. I właśnie dlatego w dobrze prowadzonym procesie Kano nie jest ozdobą warsztatu, tylko narzędziem do cięcia szumu.
Co zabieram z analizy Kano do codziennej pracy nad interfejsem
W praktyce największą wartość daje mi nie sama etykieta kategorii, tylko zmiana sposobu myślenia o backlogu. Najpierw zabezpieczam podstawy: dostępność, czytelność, obsługę błędów, szybkość i przewidywalność interakcji. Dopiero potem szukam elementów, które mogą dać użytkownikowi realną przyjemność albo wyraźnie odróżnić produkt od konkurencji.
Jeśli miałbym to uprościć do jednej reguły, powiedziałbym tak: najpierw zdejmij frustrację, potem popraw komfort, a na końcu dodawaj zachwyt. Taka kolejność zwykle lepiej służy i użytkownikom, i zespołowi, bo zmniejsza ryzyko budowania drobiazgów kosztem rzeczy ważnych.
Model Kano nie jest magiczną receptą, ale w codziennej pracy nad frontendem i UX/UI daje rzadko spotykaną jasność. Pomaga oddzielić to, co konieczne, od tego, co tylko atrakcyjne, i właśnie dzięki temu backlog zaczyna pracować na doświadczenie użytkownika, a nie przeciwko niemu.