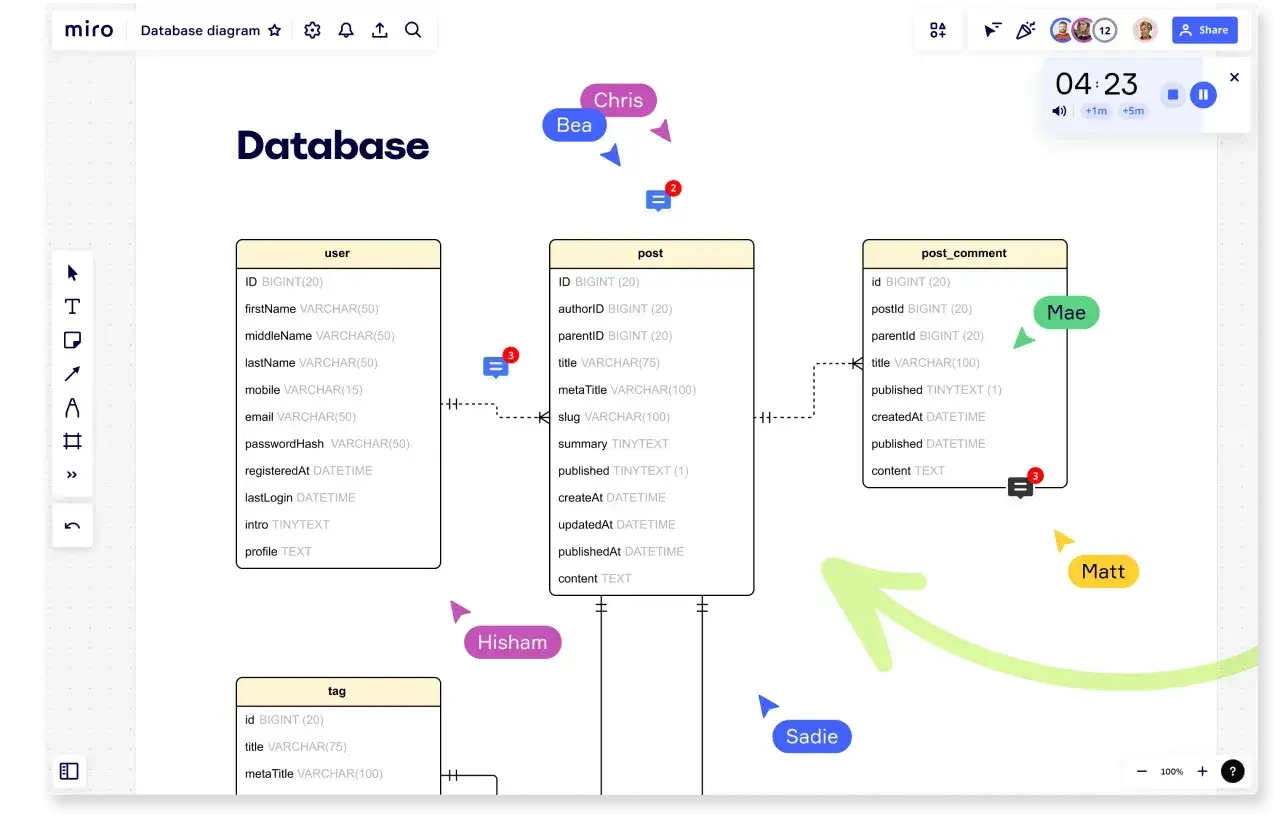
Dobry diagram ERD bazy danych porządkuje to, co w systemach informatycznych najłatwiej się rozjeżdża: nazwy encji, zależności między nimi i reguły biznesowe, które potem trzeba bezbłędnie zamienić na tabele SQL. W tym tekście pokazuję, czym taki model naprawdę jest, jak go czytać i jak przejść od szkicu do sensownego schematu. Dorzucam też praktyczne przykłady, typowe błędy i wskazówki, które pomagają uniknąć kosztownych poprawek na późnym etapie projektu.
Najważniejsze informacje o modelowaniu ERD
- ERD opisuje encje, ich atrybuty i relacje, zanim jeszcze powstanie kod SQL.
- W praktyce najczęściej spotkasz notację crow's foot, bo najlepiej pokazuje krotności i opcjonalność.
- Dobrze przygotowany model upraszcza przejście do tabel, kluczy głównych i obcych.
- Najbardziej problematyczne są relacje wiele-do-wielu, brak reguł obowiązkowości i projektowanie „pod ekran”, a nie pod dane.
- Najlepszy efekt daje diagram zgodny z wymaganiami biznesowymi, a nie tylko estetycznie narysowany.
Czym jest ERD i po co używa się go przy bazach danych
ERD to narzędzie do modelowania danych na poziomie koncepcyjnym i logicznym. Nie rysuję go po to, żeby „było ładnie”, tylko po to, żeby sprawdzić, czy biznesowy opis da się przełożyć na strukturę bazy bez zgadywania. W praktyce dobrze rozróżniam trzy poziomy modelu:
| Poziom modelu | Co pokazuje | Kiedy jest przydatny |
|---|---|---|
| Koncepcyjny | Najważniejsze encje i związki z perspektywy biznesu | Na starcie projektu, gdy dopiero uzgadniasz wymagania |
| Logiczny | Encje, atrybuty, klucze i krotności | Gdy zaczynasz przekładać wymagania na strukturę danych |
| Fizyczny | Realne tabele, typy danych, indeksy i ograniczenia | Przed implementacją w konkretnej bazie, np. PostgreSQL czy MySQL |
Największa różnica między tymi poziomami jest prosta: na wcześniejszych etapach myślę o sensie danych, a dopiero później o ich technicznym zapisie. To właśnie oszczędza najwięcej czasu, kiedy projekt zaczyna się rozrastać. Kiedy ten podział jest jasny, łatwiej wejść w symbole i krotności, bo one mówią już nie tylko o obiektach, ale o ich wzajemnych zależnościach.

Jak czytać encje, atrybuty i krotności
Żeby czytać diagramy ERD bez chaosu, trzeba dobrze rozumieć kilka podstawowych pojęć. Ja zwykle tłumaczę je zespołowi w ten sposób:
| Pojęcie | Znaczenie w praktyce |
|---|---|
| Encja | Obiekt biznesowy, np. klient, zamówienie albo produkt |
| Atrybut | Cechy encji, np. nazwa, e-mail, cena czy data utworzenia |
| Klucz główny | Kolumna albo zestaw kolumn, które jednoznacznie identyfikują rekord |
| Klucz obcy | Pole wskazujące rekord w innej tabeli i spinające relację |
| Krotność | Informacja, ile rekordów może brać udział w relacji po każdej stronie |
| Opcjonalność | Reguła mówiąca, czy związek albo pole mogą pozostać puste |
Najczęściej spotkasz notację crow's foot, bo dobrze pokazuje „jeden”, „wiele” i opcjonalność w sposób bliski temu, jak później wygląda SQL. Notacja Chen też jest poprawna i użyteczna, ale przy codziennej pracy z tabelami bywa mniej wygodna, bo bardziej akcentuje abstrakcyjny model niż samą implementację. Gdy symbole stają się czytelne, można przejść do konkretnego procesu projektowania.
Jak zaprojektować diagram ERD krok po kroku
Ja zaczynam od pytań biznesowych, a dopiero potem zamieniam odpowiedzi na encje i relacje. Dzięki temu diagram nie staje się zbiorem przypadkowych tabel. Sprawdzony porządek pracy wygląda tak:
- Spisz scenariusze użycia. Zastanów się, jakie dane system ma przechowywać, kto z nich korzysta i jakie operacje są naprawdę ważne.
- Wypisz encje. Szukaj rzeczowników opisujących biznes, a nie elementy interfejsu. Klient, zamówienie i produkt są zwykle lepszym początkiem niż przycisk „dodaj do koszyka”.
- Ustal atrybuty i klucze. Każda encja powinna mieć identyfikator, a atrybuty muszą odzwierciedlać to, co rzeczywiście trzeba zapisać.
- Zdefiniuj relacje. Nazwij je prostym zdaniem, np. „klient składa zamówienia” albo „produkt należy do kategorii”. Jeśli zdanie brzmi niejasno, model też będzie niejasny.
- Określ krotności i opcjonalność. To moment, w którym decydujesz, czy relacja jest 1:1, 1:N, czy M:N, a także czy dany rekord może istnieć bez powiązania.
- Przetestuj model na przykładach. Weź kilka realnych przypadków i sprawdź, czy diagram da się nimi opisać bez luk i sztucznych obejść.
Jeśli na którymś etapie nie potrafię opisać relacji jednym zdaniem, wracam do wymagań. To zwykle znak, że model jest jeszcze zbyt ogólny albo że jedna encja próbuje przechwycić zbyt wiele odpowiedzialności. Tak przygotowany szkic dopiero teraz warto zamieniać na strukturę SQL.
Jak przełożyć ERD na tabele SQL bez utraty sensu
Przełożenie ERD na SQL polega przede wszystkim na tym, żeby nie zgubić krotności i reguł obowiązkowości. Tutaj najwięcej osób robi skrót myślowy: widzą relację, ale nie zastanawiają się, gdzie ma trafić klucz obcy i czy nie potrzeba tabeli pośredniej.
| Rodzaj relacji | Jak wygląda w SQL | Na co zwracam uwagę |
|---|---|---|
| 1:1 | Klucz obcy z ograniczeniem `UNIQUE` albo wspólny klucz | Sprawdzam, czy to na pewno osobna encja, a nie tylko nadmiarowy podział danych |
| 1:N | Klucz obcy po stronie „wiele” | Ustalam, czy FK może być pusty, czy musi zawsze wskazywać rekord nadrzędny |
| M:N | Tabela pośrednia z dwoma kluczami obcymi | Dodaję też atrybuty relacji, jeśli sama relacja niesie informację, np. ilość lub cenę |
| Relacja opcjonalna | `NULL` w odpowiednim FK albo dodatkowe ograniczenie biznesowe | Nie mylę „opcjonalne” z „luźne”; to wciąż musi mieć sens biznesowy |
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT NOT NULL,
created_at TIMESTAMP NOT NULL,
FOREIGN KEY (customer_id) REFERENCES customers(id)
);
CREATE TABLE order_items (
order_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
PRIMARY KEY (order_id, product_id),
FOREIGN KEY (order_id) REFERENCES orders(id),
FOREIGN KEY (product_id) REFERENCES products(id)
);W praktyce warto też pamiętać o ograniczeniach: `NOT NULL` wymusza obowiązkowość, `UNIQUE` pilnuje jedyności, a `ON DELETE` decyduje, co się stanie, gdy rekord nadrzędny zniknie. To są drobiazgi na diagramie, ale właśnie one oddzielają model „na pokaz” od modelu, który da się bezpiecznie wdrożyć. Na prostym przykładzie sklepu internetowego widać to najlepiej.
Przykład prostego modelu sklepu internetowego
W sklepie internetowym najczytelniej wychodzą cztery podstawowe encje: klient, zamówienie, pozycja zamówienia i produkt. Ten przykład jest dobry, bo od razu pokazuje zarówno relację 1:N, jak i M:N, którą trzeba rozbić na tabelę pośrednią.
| Encja | Rola w modelu | Dlaczego jest ważna |
|---|---|---|
| customers | Przechowuje dane klienta | Stanowi punkt startowy dla zamówień i historii zakupów |
| orders | Opisuje pojedyncze zamówienie | Łączy klienta z konkretną transakcją i datą złożenia |
| order_items | Przechowuje pozycje zamówienia | Rozwiązuje relację M:N między zamówieniem a produktem i trzyma ilość oraz cenę zakupu |
| products | Opisuje towar w katalogu | Jest źródłem danych o nazwie, cenie i dostępności produktu |
| categories | Grupuje produkty | Pomaga utrzymać porządek w katalogu i uprościć filtrowanie |
Najważniejszy detal to `order_items`: tam trzymam ilość, cenę z chwili zakupu i ewentualny rabat. Gdyby zostawić to tylko w `orders` albo `products`, historia transakcji zaczęłaby się rozjeżdżać przy każdej zmianie ceny. To właśnie taki detal pokazuje, po co w ogóle robi się ERD. Kiedy ten przykład jest już jasny, łatwiej zauważyć, jakie błędy psują model jeszcze przed wdrożeniem.
Najczęstsze błędy, które psują model danych
Najczęstsze błędy przy modelowaniu nie wynikają z braku narzędzia, tylko z pośpiechu. Widziałem to wielokrotnie: diagram powstaje szybko, ale potem trudno z niego cokolwiek sensownego wyegzekwować. Najbardziej kosztują mnie te problemy:
- Modelowanie ekranów zamiast danych biznesowych. Jeśli projekt zaczyna się od formularzy, a nie od obiektów domenowych, model zwykle szybko traci spójność.
- Brak tabeli pośredniej przy relacji M:N. To klasyczny błąd, który prowadzi do duplikacji danych albo do nienaturalnych obejść w kodzie.
- Powtarzające się grupy w jednej tabeli. Kolumny typu `item1`, `item2`, `item3` są sygnałem, że projekt od razu powinien zostać przebudowany.
- Niejasna obowiązkowość relacji. Jeśli nie wiadomo, czy związek jest opcjonalny, implementacja też będzie niejednoznaczna.
- Brak konsekwentnych nazw. Mieszanie `user`, `client`, `customer` i `konto` w jednym modelu utrudnia rozwój bardziej, niż się na początku wydaje.
- Zamazywanie decyzji technicznych z koncepcyjnymi. Jeśli na etapie ERD zaczynasz już walczyć o typy danych, indeksy i silnik bazy, łatwo zgubić logikę biznesową.
Jeśli któryś z tych punktów wygląda znajomo, poprawka zwykle nie polega na „dorysowaniu jednej strzałki”, tylko na cofnięciu się o krok i ponownym sprawdzeniu wymagań. Kiedy ten porządek jest utrzymany, dużo łatwiej wybrać narzędzie, które nie będzie przeszkadzać, tylko wspierać pracę.
Narzędzia i nawyki, które naprawdę ułatwiają pracę
Nie wybieram narzędzia do ERD po samym wyglądzie. Ważniejsze jest to, czy potrafi wspierać realny workflow: od szkicu, przez uzgodnienie modelu, aż po eksport albo synchronizację ze schematem SQL. W praktyce zwracam uwagę na pięć rzeczy:
- import i eksport SQL, żeby diagram dało się zamienić w działający schemat bez ręcznego przepisywania,
- reverse engineering, czyli odtworzenie diagramu z istniejącej bazy, gdy dokumentacja już nie nadąża za kodem,
- współpracę zespołową i komentarze, bo model danych rzadko jest dziełem jednej osoby,
- historię zmian albo przynajmniej wygodny eksport wersji, żeby dało się porównać kolejne decyzje,
- czytelne wsparcie dla krotności, kluczy i ograniczeń, bo bez tego diagram wygląda ładnie, ale ma małą wartość techniczną.
W projektach, w których kod i schemat żyją razem, najlepiej działa zasada: diagram ma być żywym dokumentem, a nie jednorazowym załącznikiem do prezentacji. Jeśli model aktualizuje się razem z migracjami, dużo trudniej o ciche rozjazdy między dokumentacją a bazą. To prowadzi do najważniejszego etapu, czyli sprawdzenia modelu przed wdrożeniem.
Co warto sprawdzić, zanim przełożysz ERD na schemat SQL
Zanim uznam model za gotowy, robię prosty test. Przechodzę po nim pytaniem: czy potrafię z tego diagramu jednoznacznie odczytać, jakie dane wchodzą do systemu, gdzie są relacje 1:N i M:N, które pola mogą być puste i co dzieje się po usunięciu rekordu nadrzędnego. Jeśli na któreś z tych pytań nie ma szybkiej odpowiedzi, diagram jeszcze nie jest gotowy.
- Sprawdź, czy każda encja ma jasną rolę biznesową i nie dubluje innej encji pod inną nazwą.
- Zweryfikuj, czy wszystkie relacje M:N mają tabelę pośrednią i czy ta tabela przechowuje potrzebne atrybuty relacji.
- Upewnij się, że obowiązkowość i opcjonalność są zgodne z regułami procesu, a nie tylko z intuicją osoby projektującej.
- Przetestuj model na kilku scenariuszach użycia, w tym na sytuacjach skrajnych, bo to one najczęściej ujawniają luki.
W dobrze zrobionym modelu ERD nie chodzi o perfekcyjny rysunek, tylko o klarowną decyzję projektową. Im wcześniej wychwycisz niejednoznaczność, tym mniej kosztownych zmian będziesz robić później, gdy baza danych, migracje i kod aplikacji zaczną już działać razem.