
Baza działająca w RAM potrafi radykalnie skrócić czas odpowiedzi aplikacji, ale nie każdy projekt naprawdę tego potrzebuje. W praktyce in memory database sprawdza się tam, gdzie liczą się niskie opóźnienia, duża liczba operacji na sekundę i rozsądny model odzyskiwania danych po awarii. Poniżej rozkładam temat na konkretne decyzje: kiedy taki silnik ma sens, jak działa z SQL, czym różni się od cache i na co zwrócić uwagę przed wdrożeniem.
Najważniejsze fakty, które pomagają szybko ocenić to rozwiązanie
- Dane są przechowywane w RAM, więc odczyt i zapis omijają wolniejszą warstwę dysku.
- In-memory nie musi oznaczać ulotności - wiele silników korzysta ze snapshotów, logów transakcyjnych i replikacji.
- Najlepiej działa na danych gorących: sesjach, rankingach, licznikach, telemetrii i szybkich transakcjach OLTP.
- SQL bywa pełnoprawny w rozwiązaniach takich jak SAP HANA, Oracle TimesTen czy SingleStore.
- Największe ryzyko to źle oszacowany rozmiar danych, zbyt mały bufor pamięci i brak planu odzyskiwania po restarcie.
Na czym polega baza trzymana w RAM
Najprościej mówiąc, taki silnik trzyma aktywne dane w pamięci operacyjnej, a nie na dysku. To robi ogromną różnicę, bo dostęp do RAM jest dużo szybszy niż do nośnika trwałego, więc zapytania nie czekają na kosztowne operacje I/O. Ja patrzę na to jak na przesunięcie ciężaru z magazynu na stół roboczy: wszystko, co jest potrzebne „teraz”, leży pod ręką.
W praktyce sam fakt, że dane siedzą w pamięci, nie rozwiązuje wszystkiego. Nadal potrzebujesz indeksów, planu zapytań, transakcji i mechanizmu, który zabezpieczy system po awarii. Dlatego nowoczesne silniki in-memory zwykle łączą kilka warstw: szybką pamięć operacyjną, log transakcyjny, checkpointy i replikację. Dzięki temu baza może być jednocześnie szybka i odporna na restart, a nie tylko „błyskawiczna do pierwszego zaniku zasilania”. To prowadzi do kolejnego pytania: kiedy taki model naprawdę daje przewagę, a kiedy jest przerostem formy nad treścią?
Gdzie taki silnik wygrywa, a gdzie przegrywa
Ja najczęściej rozpoznaję dobry przypadek po tym, że aplikacja ma niewielki, ale bardzo często używany zestaw danych. Jeśli te rekordy są odczytywane i aktualizowane bez przerwy, a użytkownik odczuwa każdą dodatkową dziesiątkę milisekundy, baza w RAM potrafi zrobić różnicę, której klasyczny storage nie nadrobi samą optymalizacją SQL.
| Scenariusz | Czy ma sens | Dlaczego |
|---|---|---|
| Sesje użytkowników, tokeny, koszyki | Tak | Dane są małe, często odczytywane i wymagają bardzo niskiej latencji. |
| Liczniki, rankingi, leaderboardy | Tak | Wartość zmienia się często, a szybki zapis i odczyt są ważniejsze niż tani storage. |
| Systemy OLTP z krótkimi transakcjami | Tak | Duża liczba małych operacji korzysta z szybkiego dostępu do aktywnych rekordów. |
| Analiza ad hoc na dużych tabelach historycznych | Raczej nie | Jeśli dominują pełne skany i ciężkie agregacje, sama pamięć nie rozwiąże problemu modelu danych. |
| Archiwum i raporty miesięczne | Raczej nie | Tu zwykle ważniejsza jest trwałość, kompresja i niższy koszt przechowywania. |
| Duże pliki i binarne załączniki | Nie | Takie dane szybko zjadają RAM, a zysk z przetwarzania nie rekompensuje kosztu pamięci. |
Jeżeli twoje dane są „gorące”, zmieniają się często i mają krótki czas życia w aplikacji, taki wybór ma sens. Jeżeli rosną szybciej niż budżet na pamięć albo potrzebujesz długiej historii w niskiej cenie, lepiej zostać przy klasycznym podejściu albo rozdzielić warstwy: RAM dla aktywnych rekordów, dysk dla reszty. To z kolei prowadzi do najważniejszego pytania: jak w takim środowisku wygląda trwałość danych i SQL?
SQL, transakcje i trwałość danych w praktyce
Wiele osób myli bazę w RAM z nietrwałym cachem. To nie to samo. Cache przyspiesza odczyt, ale zwykle nie jest źródłem prawdy, natomiast pełnoprawny silnik in-memory potrafi obsługiwać transakcje ACID, czyli atomiczność, spójność, izolację i trwałość. W praktyce oznacza to, że zapis nie kończy się na „zostało w pamięci”, tylko trafia do mechanizmów, które pozwalają odtworzyć stan po awarii.
Najczęściej spotkasz cztery podejścia do zabezpieczania danych:
| Mechanizm | Co daje | Jaki ma koszt |
|---|---|---|
| Snapshot | Okresową kopię stanu pamięci, z której można odtworzyć bazę po restarcie. | Możesz stracić zmiany wykonane po ostatnim zapisie migawkowym. |
| Log transakcyjny | Ślad operacji zapisujących, który pozwala odtworzyć bazę niemal do ostatniego momentu. | Więcej I/O, więcej miejsca i dłuższy czas odtwarzania. |
| Replikacja | Kopię danych na innym węźle, co poprawia dostępność. | Większa złożoność architektury i dodatkowy ruch sieciowy. |
| Brak trwałości | Maksymalną prostotę i szybkość działania. | Po restarcie tracisz dane, więc to ma sens tylko w bardzo ograniczonych scenariuszach. |
Jeśli projekt ma być naprawdę krytyczny, sama szybkość nie wystarczy. Trzeba jeszcze sprawdzić, czy silnik wspiera SQL w pełnym zakresie, jak obsługuje blokady, jak szybko robi checkpointy i jaki jest czas odtworzenia po awarii. To właśnie tutaj wiele wdrożeń rozbija się o złe założenia: ktoś widzi RAM i zakłada, że trwałość „jakoś się dogra później”. W praktyce trzeba ją zaprojektować od początku, a nie dopinać na końcu. Skoro to mamy ustalone, porównajmy teraz konkretne podejścia, bo pod nazwą „in-memory” kryje się kilka różnych klas rozwiązań.
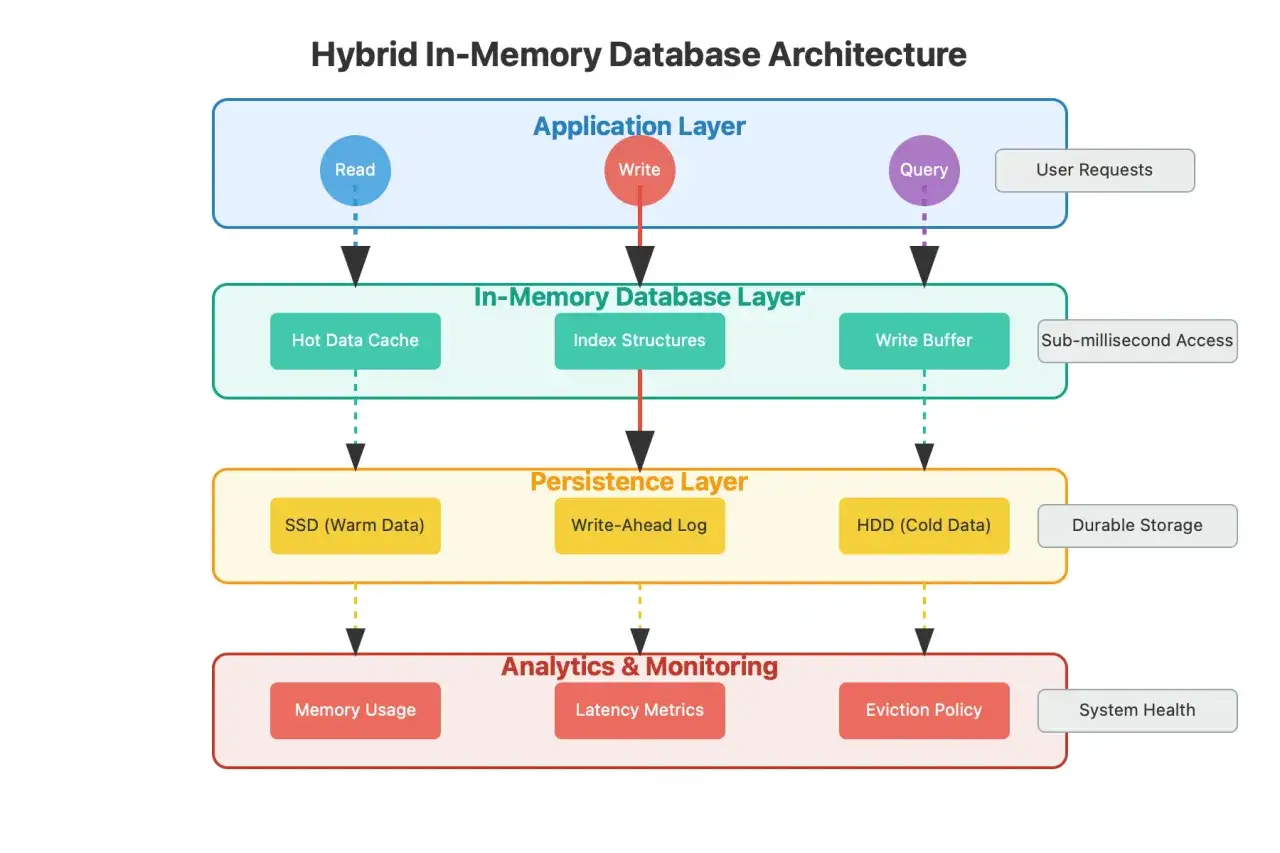
Jak odróżnić rozwiązanie SQL od cache i od hybrydy
W tym miejscu zwykle robię porządek w nazewnictwie, bo rynek lubi mieszać pojęcia. Jedne systemy są przede wszystkim cache’em danych, inne są pełnoprawnymi relacyjnymi bazami SQL, a jeszcze inne łączą pamięć i dysk w jednym silniku. Dla czytelnika najważniejsze jest to, czy potrzebuje przede wszystkim ultra niskiej latencji, czy jednak relacyjnego modelu pracy z danymi.
| System | Model danych | SQL | Kiedy pasuje | Na co uważać |
|---|---|---|---|---|
| Redis | Struktury danych i podejście NoSQL | Nie jako główny model | Sesje, cache, kolejki, rankingi, szybkie liczniki | To raczej szybka warstwa danych niż klasyczna baza relacyjna. |
| SAP HANA | Relacyjny silnik in-memory | Tak | Analityka, OLTP, scenariusze mieszane, duże wdrożenia biznesowe | Wymaga solidnego planu pamięci i sensownego zarządzania zasobami. |
| Oracle TimesTen | Relacyjna baza w pamięci | Tak | Bardzo szybkie transakcje OLTP i systemy o krytycznej latencji | Świetny do szybkich operacji, ale trzeba świadomie zaplanować trwałość i replikację. |
| SingleStore | Hybrydowy SQL z in-memory rowstore i dyskowym columnstore | Tak | HTAP, dane operacyjne i analityczne w jednym środowisku | Nie każdy typ tabeli będzie trzymany wyłącznie w RAM, więc trzeba znać model storage. |
Jeśli SQL jest dla ciebie warunkiem, a nie dodatkiem, zwykle zaczynam od TimesTen, SAP HANA albo SingleStore. Redis traktuję częściej jako osobną warstwę przyspieszającą aplikację niż jako zamiennik relacyjnej bazy. Taka decyzja nie jest ideologiczna, tylko praktyczna: chodzi o to, czy priorytetem jest model danych, czy po prostu maksymalna szybkość obsługi najgorętszych operacji. Po wyborze technologii zostaje już tylko wdrożenie, a tam najwięcej problemów rodzi nie sam silnik, lecz sposób jego użycia.
Na co zwracam uwagę przy wdrożeniu
W projektach produkcyjnych najbardziej liczy się chłodna kalkulacja. Ja zawsze sprawdzam najpierw, ile danych naprawdę musi siedzieć w pamięci, a dopiero potem patrzę na benchmarki. Sama deklaracja „mieści się w RAM” nic nie znaczy, jeśli nie uwzględniasz indeksów, bufora na operacje, logów transakcyjnych i marginesu na wzrost ruchu.
- Working set, nie cały zbiór danych - w pamięci powinno lądować to, co jest faktycznie gorące, a nie każdy rekord z pięciu lat historii.
- Indeksy mają koszt - szybkie wyszukiwanie zwykle wymaga dodatkowej pamięci, więc sam rozmiar tabeli nie wystarcza do wyceny.
- Plan odzyskiwania musi istnieć od startu - snapshot, log transakcyjny i replikacja nie są dodatkiem, tylko częścią projektu.
- Monitoring p95 i p99 - średnia latencja potrafi wyglądać dobrze, a ogon zapytań już nie.
- Warm-up po restarcie - jeśli aplikacja po awarii potrzebuje czasu, żeby ponownie „rozgrzać” dane, musisz to uwzględnić w SLA.
- Granica kosztowa - RAM jest szybszy, ale też droższy od dysku, więc opłacalność trzeba liczyć na realnym obciążeniu, nie na intuicji.
W praktyce najczęstszy błąd wygląda tak samo: zespół zakłada, że skoro system jest szybki, to można po prostu wrzucić do niego całą bazę i problem z głowy. Nie można. Gdy aktywny zestaw danych rośnie, trzeba zdecydować, co zostaje w pamięci, co trafia na dysk i jak szybko system ma się podnieść po awarii. To właśnie ten etap odróżnia udane wdrożenie od kosztownego eksperymentu. I to prowadzi do ostatniej rzeczy, którą naprawdę warto zapamiętać.
Co naprawdę decyduje o tym, czy to się opłaci
Najuczciwsza reguła jest prosta: jeśli aktywne dane mieszczą się w pamięci, a aplikacja potrzebuje bardzo krótkich i powtarzalnych odpowiedzi, rozwiązanie in-memory daje realną przewagę. Jeśli jednak projekt wymaga długiej historii, taniego przechowywania i pełnej odporności na wzrost zbioru danych bez nieustannego dokładania RAM-u, lepiej pozostać przy klasycznej bazie dyskowej albo zbudować hybrydę. Ja traktuję te silniki jako narzędzie do konkretnego zadania, a nie jako uniwersalny zamiennik wszystkiego.
Najlepsze wdrożenia zwykle nie próbują wygrać wszystkiego naraz. Trzymają w RAM tylko to, co krytyczne dla czasu reakcji, a resztę odkładają tam, gdzie koszt i trwałość mają większy sens. Jeśli chcesz dobrze dobrać taki system, zacznij nie od nazwy produktu, tylko od odpowiedzi na dwa pytania: ile danych naprawdę musi być „na już” i co stanie się z aplikacją po restarcie. To właśnie od tych dwóch odpowiedzi zależy, czy pamięć operacyjna będzie przewagą, czy tylko drogim luksusem.