Dobry diagram bazy danych porządkuje to, co później trafia do SQL-a, ORM-u i dokumentacji projektu. Pokazuje nie tylko tabele, ale też ich relacje, klucze i ograniczenia, więc pomaga szybciej wyłapać błędy w modelu danych. Dla mnie to jedno z tych narzędzi, które oszczędza czas zarówno przy projektowaniu, jak i przy późniejszych zmianach.
Najpierw relacje, potem szczegóły techniczne
- Schemat ma wyjaśniać strukturę danych, a nie tylko wyglądać „profesjonalnie”.
- Najważniejsze są encje, klucze, krotności i reguły integralności.
- Relacja wiele-do-wielu prawie zawsze wymaga tabeli pośredniej.
- Dobry schemat powinien dać się przełożyć na konkretne zapytania SQL.
- W pracy z Pythonem najlepiej sprawdza się diagram utrzymywany razem z kodem i migracjami.
Czym jest diagram bazy danych i co pokazuje naprawdę
Najprościej: to wizualny model struktury danych, który pokazuje, jakie informacje przechowujesz i jak one się ze sobą łączą. W praktyce widzisz na nim encje, czyli zwykle tabele, ich atrybuty, klucze główne, klucze obce oraz ograniczenia, które narzucają porządek całemu projektowi. Ja traktuję taki schemat jak mapę odpowiedzialności: mówi, gdzie dane powstają, gdzie są przechowywane i kto od kogo zależy.
Warto od razu odróżnić dwa poziomy takiego rysunku. Diagram logiczny opisuje biznes i relacje między obiektami, a diagram fizyczny schodzi niżej i pokazuje już realne nazwy tabel, typy kolumn, indeksy czy ograniczenia techniczne. Pierwszy pomaga myśleć, drugi pomaga wdrażać. Jeśli zaczynasz projekt od samego fizycznego poziomu, łatwo zgubić sens domeny; jeśli zatrzymasz się tylko na poziomie logicznym, SQL później i tak wymusi doprecyzowanie szczegółów.
Najważniejsza korzyść nie polega na „ładnym obrazku”, tylko na tym, że zespół może szybciej odpowiedzieć na pytania: czy dane się duplikują, gdzie powstaje zależność, czy usunięcie rekordu nie rozbije innych tabel i jak będzie wyglądało złączenie w zapytaniu. To właśnie dlatego schemat jest tak użyteczny na etapie projektowania, refaktoryzacji i debugowania. Następny krok to nauczyć się go czytać bez domysłów.
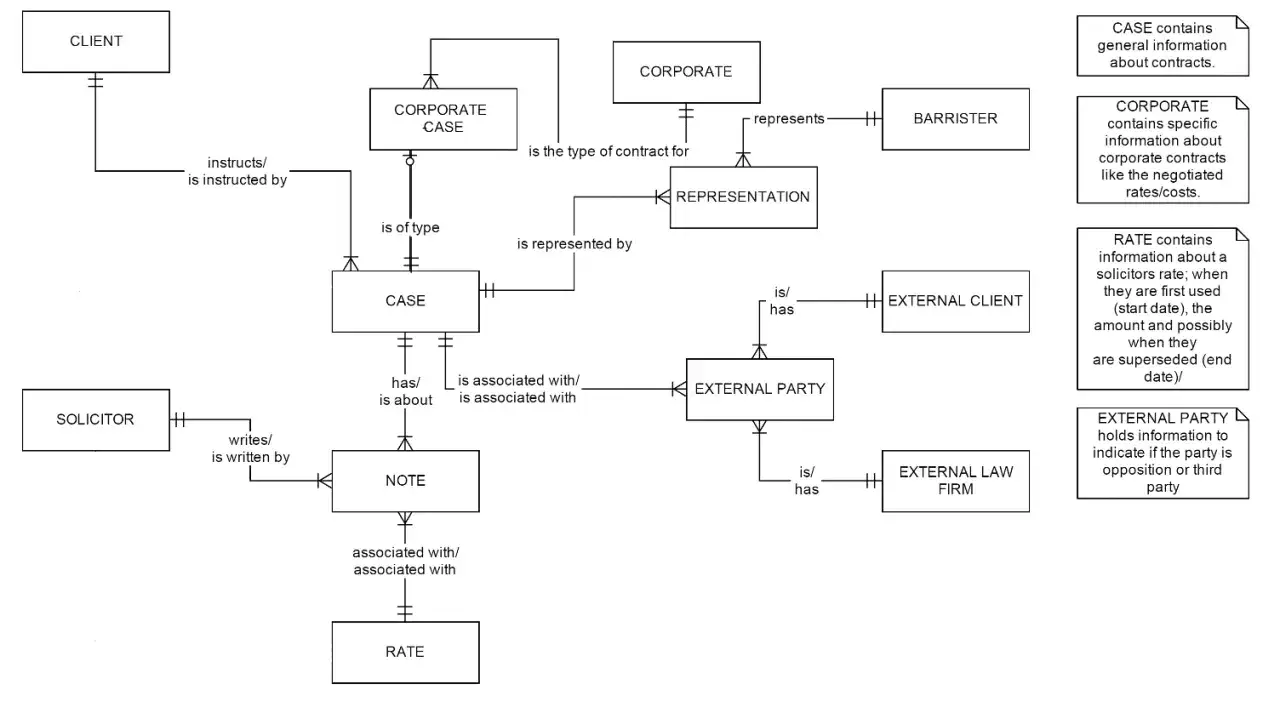
Jak czytać encje, atrybuty i relacje bez zgadywania
W diagramach najczęściej trafisz na trzy główne elementy: encje, atrybuty i relacje. Encja to po prostu byt, który opisujesz w systemie, na przykład użytkownik, zamówienie albo produkt. Atrybuty to jego cechy, czyli kolumny. Relacja pokazuje, jak jeden byt łączy się z drugim. Jeśli chcesz czytać schemat pewnie, nie zaczynaj od dekoracji, tylko od pytania: co jest obiektem, co jest jego cechą, a co zależnością?
| Element | Co oznacza | Na co patrzeć w praktyce |
|---|---|---|
| Encja | Obiekt, który trafia do osobnej tabeli | Czy ma własną tożsamość i cykl życia |
| Atrybut | Pole opisujące encję | Czy powinien być obowiązkowy, unikalny lub opcjonalny |
| Klucz główny | Jednoznaczny identyfikator rekordu | Czy jest stabilny i nie zmienia się bez potrzeby |
| Klucz obcy | Odwołanie do innej tabeli | Czy jasno pokazuje kierunek zależności |
| Krotność | Liczba rekordów po obu stronach relacji | Czy mamy 1:1, 1:N czy N:M |
Najważniejsze są trzy typy relacji. 1:1 pojawia się rzadziej i zwykle oznacza rozdzielenie danych wrażliwych albo opcjonalnych. 1:N to klasyka, na przykład jeden użytkownik ma wiele zamówień. N:M oznacza relację wiele-do-wielu, której nie zostawia się „w powietrzu” - prawie zawsze trzeba ją rozbić na tabelę pośrednią. To właśnie ten moment odróżnia sensowny model od rysunku, który tylko udaje porządek.
Dla przykładu: klient może złożyć wiele zamówień, ale jedno zamówienie należy do jednego klienta. Z kolei zamówienie zawiera wiele produktów, a ten sam produkt może wystąpić w wielu zamówieniach. W takim układzie tabela pośrednia typu `order_items` nie jest dodatkiem, tylko koniecznością. Bez niej nie zapiszesz ilości sztuk, ceny w momencie zakupu ani kolejności pozycji. I właśnie takie szczegóły decydują, czy diagram ma wartość operacyjną.
Jeśli w schemacie nie jesteś w stanie od razu wskazać, gdzie znajduje się klucz obcy i dlaczego ta relacja ma akurat taką krotność, to najpewniej model jest jeszcze niezamknięty. Z takiego czytania bardzo naturalnie przechodzi się do budowania własnego projektu, najlepiej na konkretnym przykładzie.
Jak wygląda sensowny schemat na przykładzie sklepu internetowego
Najczytelniej uczy przykład. W sklepie internetowym zwykle zaczynam od kilku podstawowych encji: `users`, `orders`, `order_items`, `products` i ewentualnie `payments`. Każda z nich ma inną rolę, więc każda powinna odpowiadać na inne pytanie biznesowe. Użytkownik składa zamówienie, zamówienie ma pozycje, pozycje wskazują produkty, a płatność opisuje rozliczenie. To brzmi prosto, ale właśnie taka prostota najczęściej daje najlepszą bazę do rozwoju.
| Tabela | Rola | Relacja | Dlaczego to ma sens |
|---|---|---|---|
| `users` | Przechowuje dane klienta | 1:N do `orders` | Jeden klient może składać wiele zamówień |
| `orders` | Opisuje pojedyncze zamówienie | 1:N do `order_items` | Jedno zamówienie zawiera wiele pozycji |
| `order_items` | Łączy zamówienia z produktami | N:1 do `products` i `orders` | Rozwiązuje relację wiele-do-wielu |
| `products` | Przechowuje ofertę sklepu | 1:N do `order_items` | Ten sam produkt może pojawić się w wielu zamówieniach |
| `payments` | Opisuje płatność | 1:1 lub 1:N do `orders` | Zależy od modelu rozliczeń i zwrotów |
W tym przykładzie ważny jest jeden detal, który początkujący często pomijają: cena produktu w tabeli pozycji zamówienia nie powinna być pobierana wyłącznie z `products`. Jeśli cena zmieni się po tygodniu, historyczne zamówienia muszą zachować stan z momentu zakupu. Dlatego w `order_items` trzymasz nie tylko `product_id`, ale też np. ilość i cenę jednostkową. To nie jest nadmiarowość, tylko zabezpieczenie sensu danych.
Druga rzecz to płatności. W prostym systemie jedno zamówienie ma jedną płatność, ale już przy ratyfikacji, częściach płatności, zwrotach albo korektach relacja może wyglądać inaczej. Schemat powinien odzwierciedlać realny proces, a nie życzeniową wersję procesu. Z takim podejściem można przejść do tworzenia własnego diagramu bez chaosu.
Jak narysować dobry schemat krok po kroku
Ja zaczynam od pytań biznesowych, nie od rysowania pudełek. Jeśli nie wiesz, jakie raporty, formularze i operacje mają korzystać z bazy, bardzo łatwo stworzyć model, który wygląda poprawnie, ale nie wspiera pracy aplikacji. Poniższy porządek sprawdza się w większości projektów:
- Spisz zakres systemu - co dokładnie ma przechowywać baza i czego nie obejmuje.
- Wypisz encje - rzeczowniki z domeny, które mają własny sens biznesowy.
- Dodaj atrybuty - tylko te, które są potrzebne operacyjnie albo analitycznie.
- Ustal klucze - wybierz stabilny identyfikator i oznacz odwołania między tabelami.
- Rozbij relacje wiele-do-wielu - wstaw tabelę pośrednią i opisz jej własne pola.
- Sprawdź ograniczenia - unikalność, obowiązkowość, nullowalność i zachowanie przy usuwaniu.
- Zweryfikuj zapytaniami SQL - jeśli nie umiesz odtworzyć danych przez JOIN, schemat wymaga dopracowania.
Na tym etapie dobrze działa prosta zasada: jeśli model nie da się opisać w kilku konkretnych zapytaniach, to nie jest jeszcze gotowy. Zawsze pytam siebie, czy potrafię bez wahania napisać `SELECT`, który pobiera listę zamówień użytkownika, pozycje zamówienia i ich łączną wartość. Jeśli odpowiedź brzmi „nie do końca”, diagram potrzebuje poprawek. Dopiero potem warto przejść do najczęstszych potknięć, bo tam zwykle kryją się największe koszty.
Najczęstsze błędy, które psują model szybciej niż zła notacja
Najwięcej problemów nie bierze się z samego rysunku, tylko z tego, że schemat ukrywa złe decyzje. W praktyce widzę kilka błędów wyjątkowo często. Każdy z nich da się naprawić, ale tylko wtedy, gdy zauważysz go odpowiednio wcześnie.
| Błąd | Skutek | Jak to naprawić |
|---|---|---|
| Brak tabeli pośredniej dla relacji N:M | Nie da się poprawnie zapisać danych o związku między bytami | Dodaj encję łączącą z własnymi atrybutami |
| Zbyt szerokie tabele | Duplikacja danych i trudniejsze aktualizacje | Rozdziel dane według odpowiedzialności i cyklu życia |
| Niejasne nazwy pól i tabel | Trudniejsze zrozumienie schematu przez zespół | Ustal konsekwentne nazewnictwo i trzymaj się go wszędzie |
| Brak oznaczenia nullowalności i unikalności | Model wygląda dobrze, ale nie wiadomo, co jest obowiązkowe | Zaznacz ograniczenia już na diagramie |
| Mieszanie logiki biznesowej z detalami fizycznymi | Schemat staje się trudny do rozwoju i dyskusji | Oddziel wersję logiczną od implementacyjnej |
| Ignorowanie reguł usuwania i aktualizacji | Ryzyko utraty spójności danych | Świadomie określ zachowanie relacji przy zmianach |
Najbardziej podstępny błąd to udawanie, że diagram jest „tylko dokumentacją”. W rzeczywistości on często decyduje o jakości zapytań, migracji i utrzymania aplikacji. Jeśli schemat nie pokazuje ograniczeń, to zespół i tak będzie je odkrywał później, już w kodzie albo na produkcji. I właśnie dlatego warto zadbać o narzędzie, w którym ten model da się utrzymać razem z resztą projektu.
Jakie narzędzia pomagają pracować z SQL-em i Pythonem
W pracy nad bazą liczy się nie tylko samo rysowanie, ale też to, czy schemat da się aktualizować razem z projektem. Ja wolę narzędzia, które nie blokują mnie przy zmianach: czasem potrzebuję szybkiego szkicu, czasem generowania z istniejącej bazy, a czasem wersji trzymanej obok kodu. Poniżej zestawienie, które dobrze sprawdza się w praktyce.
| Narzędzie | Kiedy ma sens | Mocna strona | Ograniczenie |
|---|---|---|---|
| draw.io | Do szybkich szkiców i dokumentacji | Duża swoboda i brak przywiązania do jednego stacku | Wszystko robisz ręcznie |
| DBeaver | Gdy baza już istnieje | Pomaga odczytać i zrozumieć realną strukturę | Mniej wygodny jako „czyste płótno” do projektowania |
| dbdiagram.io | Gdy chcesz opisywać schemat tekstowo | Szybkie iteracje i dobra czytelność | Nie zastąpi pełnego narzędzia do zarządzania bazą |
| Mermaid | Do dokumentacji blisko repozytorium | Łatwo trzymać diagram obok README i kodu | Mniej wygodny przy bardziej złożonych modelach |
| Lucidchart | W pracy zespołowej i konsultacjach | Łatwe komentowanie i współdzielenie | Może być cięższe niż prosty edytor tekstowy |
W projektach Pythonowych szczególnie dobrze działa podejście, w którym schemat żyje obok modeli ORM, na przykład w SQLAlchemy albo Django ORM. Taki układ zmniejsza rozjazd między tym, co widzi backend, a tym, co faktycznie siedzi w bazie. Jeżeli diagram i migracje zaczynają się rozmijać, w praktyce to znak, że dokumentacja przestała nadążać za kodem. Lepiej wychwycić to wcześniej niż po kilku sprintach.
Co dobrze pamiętać, zanim zaczniesz kolejny projekt
Najlepszy schemat nie jest najbardziej rozbudowany. Najlepszy jest taki, który pomaga podejmować decyzje i daje się utrzymać, kiedy projekt rośnie. Zwykle wygrywa prostota połączona z konsekwencją: jasne nazwy, czytelne krotności, wyraźne ograniczenia i brak relacji „na skróty”.
Jeśli mam zostawić jedną praktyczną wskazówkę, to taką: aktualizuj schemat razem z migracjami, a nie „kiedyś potem”. Wtedy nie staje się martwym obrazkiem, tylko realnym elementem pracy zespołu. A jeśli dopiero zaczynasz, narysuj wersję minimalną, którą da się przeczytać w pół minuty, i dopiero później dodawaj szczegóły, które naprawdę coś wyjaśniają.