Baza danych nie jest po prostu zbiorem plików. To uporządkowany sposób przechowywania informacji, który pozwala szybko je wyszukiwać, aktualizować i chronić przed chaosem. W tym tekście pokazuję, jak wyglądają podstawy baz danych, do czego służy SQL i od czego zacząć, jeśli chcesz ćwiczyć to praktycznie, także w Pythonie.
Najważniejsze rzeczy, które warto zapamiętać
- Baza danych porządkuje dane, ale to system zarządzania bazą danych pilnuje zapytań, bezpieczeństwa, transakcji i kopii zapasowych.
- SQL to język do komunikacji z bazą: służy do odczytu, zapisu, zmian struktury i kontroli uprawnień.
- Najpierw projektuje się strukturę danych, a dopiero potem pisze zapytania, bo zła struktura mści się przy każdej zmianie.
- Na starcie najwięcej dają klucze, typy danych, ograniczenia i podstawowe polecenia:
SELECT,JOIN,INSERT,UPDATEorazDELETE. - W Pythonie najlepiej od razu ćwiczyć zapytania parametryzowane, bo to ogranicza ryzyko błędów i SQL injection.
Czym jest baza danych i jak porządkuje informacje
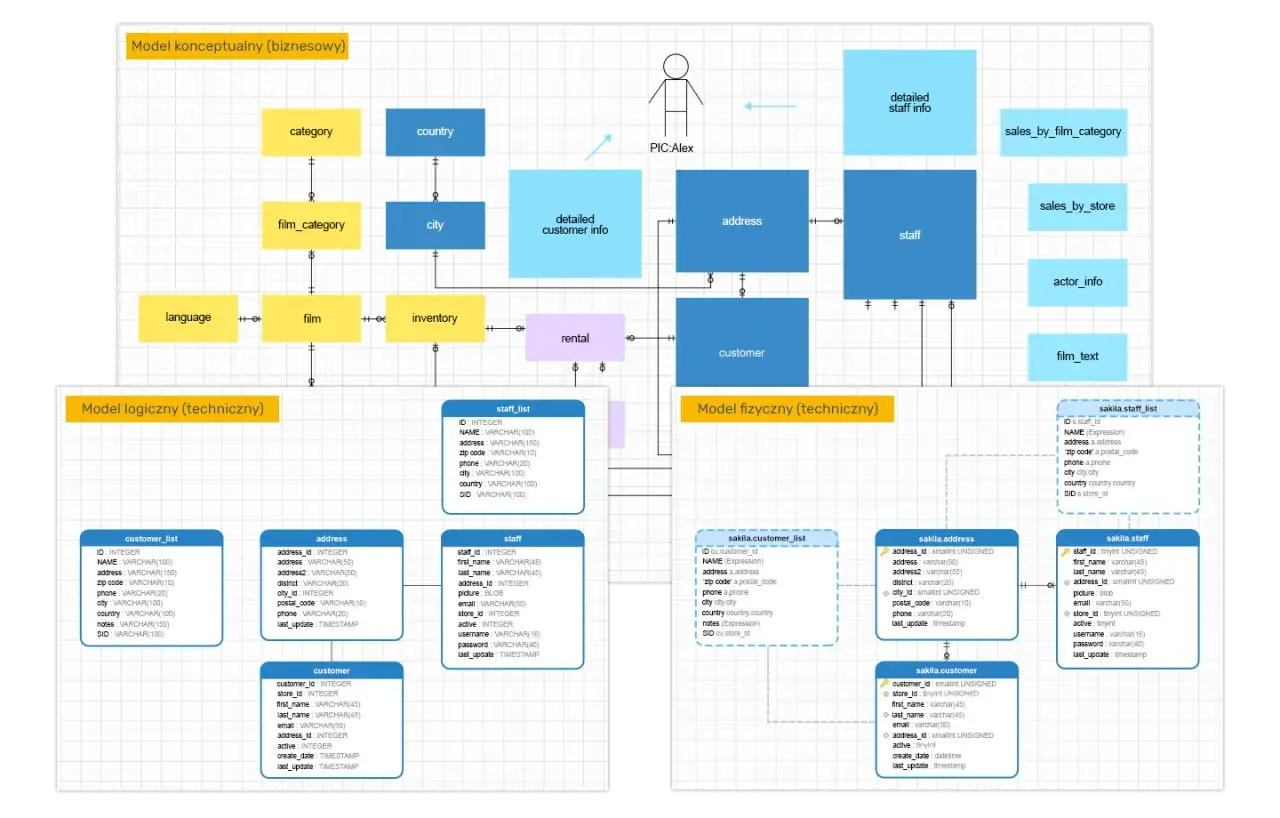
Ja zaczynam od prostego rozróżnienia: dane jeszcze nie są dobrze ułożoną bazą tylko dlatego, że siedzą w jednym pliku. Baza danych staje się użyteczna wtedy, gdy potrafisz rozdzielić informacje na logiczne części, opisać je strukturą i szybko do nich wracać bez ręcznego grzebania w każdym rekordzie.
W modelu relacyjnym wszystko opiera się na tabelach. Każda tabela przechowuje jeden typ obiektów, każdy wiersz opisuje pojedynczy egzemplarz, a każda kolumna odpowiada za konkretną cechę.
| Pojęcie | Znaczenie | Praktyczny sens |
|---|---|---|
| Baza danych | Uporządkowany zbiór danych | Pozwala szybko odczytywać i aktualizować informacje |
| Tabela | Zbiór podobnych rekordów | Oddziela różne typy obiektów, np. użytkowników i zamówienia |
| Rekord | Pojedynczy wiersz | Opisuje jednego klienta, produkt albo zamówienie |
| Kolumna | Cechę obiektu | Przechowuje np. imię, cenę, datę lub status |
| Klucz główny | Unikalny identyfikator | Umożliwia jednoznaczną identyfikację i łączenie danych |
| Schemat | Opis struktury i relacji | Porządkuje całą bazę i ogranicza przypadkowe zmiany |
Relacyjne bazy danych sprawdzają się tam, gdzie dane mają wyraźne zależności i trzeba pilnować spójności: w sklepach internetowych, systemach rezerwacji, panelach administracyjnych czy CRM-ach. Gdy struktura jest bardziej zmienna i mniej przewidywalna, czasem lepiej wypadają rozwiązania NoSQL, ale na poziomie podstaw najważniejsze jest zrozumienie właśnie modelu relacyjnego, bo to na nim opiera się SQL.
Kiedy ten fundament jest jasny, można przejść do narzędzia, które tę strukturę obsługuje na co dzień.
Jak działa system zarządzania bazą danych
System zarządzania bazą danych, czyli DBMS, to warstwa pośrednia między aplikacją a danymi. To on interpretuje polecenia SQL, dba o uprawnienia, kontroluje dostęp wielu użytkowników naraz, zarządza transakcjami i pomaga odzyskać dane po awarii. Do najczęściej spotykanych silników należą PostgreSQL, MySQL, SQLite i SQL Server.
Transakcje i spójność
Transakcja to zestaw operacji, które mają zostać wykonane razem. Jeśli coś się nie uda, można je wycofać przez ROLLBACK; jeśli wszystko jest poprawne, zatwierdza się je przez COMMIT. W praktyce to chroni przed sytuacją, w której część danych zapisze się poprawnie, a część nie.
Tu wchodzi pojęcie ACID, czyli zestaw czterech zasad: atomicity, consistency, isolation i durability. Mówią one w skrócie, że operacja ma być albo wykonana w całości, albo bezpiecznie cofnięta, a zapisane dane mają przetrwać awarię.
Indeksy i wydajność
Indeks działa trochę jak spis treści. Przyspiesza wyszukiwanie, ale zajmuje miejsce i spowalnia zapis, więc nie zakłada się go na każdą kolumnę „na wszelki wypadek”. Ja zwykle dodaję indeks dopiero wtedy, gdy wiem, które filtrowania naprawdę będą powtarzane.
Przeczytaj również: Indeksy w bazie danych - Jak przyspieszyć SQL i unikać błędów?
Uprawnienia i kopie zapasowe
Dobry DBMS pozwala ograniczać dostęp do tabel, przypisywać role i odzyskiwać dane z backupu. To ważniejsze, niż wielu początkujących zakłada, bo nawet niewielka baza testowa potrafi zniknąć po jednym błędnym skrypcie albo nieprzemyślanym usunięciu danych. Kiedy rozumiesz tę warstwę, SQL przestaje wyglądać jak przypadkowa składnia, a staje się językiem konkretnej pracy.
Właśnie dlatego warto zobaczyć, jak ten język jest zorganizowany i czego realnie używa się w codziennych zadaniach.
SQL w praktyce od odczytu do zmiany danych
SQL jest językiem deklaratywnym: opisujesz, co chcesz dostać, a silnik bazy sam wybiera sposób wykonania. To wygodne, ale wymaga jasnego myślenia o danych, bo złe założenia szybko widać w wynikach zapytań.
| Grupa poleceń | Przykłady | Do czego służy |
|---|---|---|
| DDL |
CREATE TABLE, ALTER TABLE, DROP TABLE
|
Definiowanie i zmiana struktury bazy |
| DML |
SELECT, INSERT, UPDATE, DELETE
|
Praca na danych zapisanych w tabelach |
| DCL |
GRANT, REVOKE
|
Zarządzanie uprawnieniami |
| TCL |
BEGIN, COMMIT, ROLLBACK
|
Obsługa transakcji |
Na starcie najczęściej używa się kilku poleceń: SELECT do odczytu, WHERE do filtrowania, ORDER BY do sortowania, JOIN do łączenia tabel oraz INSERT, UPDATE i DELETE do pracy na danych. To wystarczy, żeby zbudować większość prostych aplikacji i zrozumieć logikę działania relacyjnej bazy.
SELECT u.name, o.total
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE o.total > 100
ORDER BY o.total DESC;Jeśli uczysz się równolegle Pythona, od razu ćwicz zapytania parametryzowane. Dzięki temu nie doklejasz wartości użytkownika do stringa i nie otwierasz sobie drzwi do SQL injection.
import sqlite3
conn = sqlite3.connect("app.db")
cur = conn.cursor()
cur.execute("SELECT id, name FROM users WHERE id = ?", (user_id,))
row = cur.fetchone()Kiedy SQL zaczyna być zrozumiały, pojawia się ważniejsze pytanie: jak zaprojektować bazę, żeby później nie naprawiać jej po każdym nowym wymaganiu.
Jak zaprojektować prostą bazę, żeby nie poprawiać jej po tygodniu
Na etapie projektu najłatwiej popełnić błędy, które później odbijają się na każdej zmianie. Ja patrzę wtedy na cztery rzeczy: encje, klucze, typy danych i relacje.
- Wypisz encje – ustal, co jest osobnym obiektem: użytkownik, produkt, zamówienie, płatność.
-
Wybierz klucz główny – każdy wiersz powinien mieć stabilny identyfikator, najczęściej liczbowy
id. - Oddziel dane powtarzalne – jeśli adres klienta pojawia się w wielu rekordach, zwykle lepiej trzymać go w osobnej tabeli albo w dobrze przemyślanej relacji.
-
Dobierz typy i ograniczenia – data ma być datą, cena liczbą, a nie wszystkim naraz jako tekst; warto dodać też
NOT NULL,UNIQUEi klucze obce.
Dobry przykład to prosty sklep: users, orders i order_items. Taki podział pozwala zapisać jednego klienta raz, zamówienie osobno i pozycje zamówienia w tabeli łączącej. Dzięki temu nie duplikujesz danych i nie gubisz spójności, gdy coś się zmienia.
Na tym poziomie wystarczy też rozumieć normalizację jako sposób ograniczania powtórzeń. Nie chodzi o ślepą pogoń za teorią, tylko o to, żeby struktura była logiczna i nie produkowała konfliktów przy aktualizacji. Kiedy ten porządek jest na miejscu, warto przyjrzeć się błędom, które najczęściej psują nawet poprawne z pozoru projekty.
Najczęstsze błędy początkujących
Najwięcej problemów początkujący robią nie w samym SQL-u, tylko w modelu danych i bezpieczeństwie. To są błędy powtarzalne, więc da się ich uniknąć, jeśli wiesz, na co patrzeć.
- Przechowywanie wszystkiego jako tekst – daty, kwoty i liczby powinny mieć właściwe typy, bo inaczej sortowanie i filtrowanie działa źle.
- Brak klucza głównego – bez unikalnego identyfikatora trudno aktualizować rekordy i łączyć tabele.
-
Brak ograniczeń – bez
UNIQUE,NOT NULLi kluczy obcych baza przepuszcza śmieciowe dane. - Sklejanie SQL-a z tekstu – to proszenie się o SQL injection i trudne do znalezienia błędy składni.
- Zbyt wczesne indeksowanie – indeksy są ważne, ale dodane bez potrzeby tylko komplikują zapis i zajmują miejsce.
-
Brak kopii zapasowej – nawet mała baza testowa potrafi zniknąć przez jeden zły skrypt lub przypadkowy
DROP.
Jeśli mam wskazać jedną rzecz, która naprawdę odróżnia „działa” od „da się utrzymać”, to są nią ograniczenia integralności. One pilnują, by baza sama odrzucała złe dane, zamiast liczyć na czujność człowieka. Gdy to już masz, pozostaje sensowny plan nauki, a nie przypadkowe skakanie po hasłach.
Pierwszy sensowny plan nauki na bazach danych
Najlepsza ścieżka na start jest zaskakująco prosta. Zamiast uczyć się wszystkiego naraz, przechodzę zwykle przez pięć kroków:
- Opanuj tabele, wiersze, kolumny, klucze i podstawowe typy danych.
- Ćwicz
SELECT,WHERE,ORDER BYiJOINna małych przykładach. - Zbuduj mini-projekt w SQLite, bo to najłatwiejszy start bez serwera.
- Przenieś ten sam model do PostgreSQL, żeby zobaczyć różnicę między lekkim ćwiczeniem a realnym środowiskiem.
- Dodaj transakcję, indeks i backup, żeby zobaczyć, jak baza zachowuje się pod większym obciążeniem i przy awarii.
Jeśli pracujesz w Pythonie, zacznij od sqlite3, a potem przejdź do sterownika PostgreSQL, na przykład psycopg. W praktyce to właśnie ten etap daje największy zwrot, bo SQL przestaje być suchą składnią, a staje się narzędziem do aplikacji webowych, raportów i automatyzacji. Ja zaczynałbym od małej, ale dobrze zaprojektowanej bazy, bo na niej najszybciej widać, czy rozumiesz relacje, czy tylko pamiętasz komendy.