ASCII to jeden z najprostszych, a jednocześnie najbardziej wpływowych standardów kodowania tekstu. Dzięki niemu komputer potrafi zapisać litery, cyfry, znaki interpunkcyjne i kilka znaków sterujących w postaci liczb, co ma znaczenie zarówno w nauce programowania, jak i przy pracy z plikami, terminalem czy prostymi protokołami tekstowymi. Dla początkującego programisty znaki ASCII są dobrym punktem startu, bo pomagają zrozumieć, skąd biorą się kody znaków, błędy kodowania i różnice między tekstem a bajtami.
Najważniejsze fakty o ASCII w jednym miejscu
- ASCII to 7-bitowy standard obejmujący 128 kodów, z czego 95 to znaki drukowalne.
- Pierwsze 33 pozycje to znaki sterujące, czyli instrukcje dla urządzeń i programów, a nie litery czy cyfry.
- W Pythonie najczęściej używa się `ord()`, `chr()` oraz kodowania `encode('ascii')`.
- Dla języka polskiego ASCII nie wystarcza, bo nie obejmuje liter z ogonkami i kreskami.
- W praktyce ASCII jest ważne głównie tam, gdzie liczy się prosty, przewidywalny tekst: pliki, sieci, terminale i automatyzacja.
Czym jest ASCII i dlaczego nadal ma znaczenie
ASCII jest standardem zapisu znaków opartym na alfabecie łacińskim i prostym systemie numeracji. Każdemu znakowi przypisuje się konkretną liczbę, dzięki czemu komputer nie musi zgadywać, czy widzi literę, cyfrę, spację czy znak sterujący. W praktyce oznacza to bardzo przewidywalny zestaw znaków: od `A` i `a`, przez cyfry, po podstawową interpunkcję.
Najważniejsza cecha tego standardu to jego prostota. ASCII mieści się w 7 bitach, więc obejmuje 128 kodów, a to nadal wystarcza w wielu miejscach technicznych: w nagłówkach protokołów, prostych plikach konfiguracyjnych, nazwach identyfikatorów czy komunikacji z urządzeniami. Jeśli rozumiesz ten model, dużo łatwiej czytasz też później Unicode, bo jego pierwsze 128 punktów kodowych odpowiada właśnie ASCII.
Warto też pamiętać, że ASCII nie jest tym samym co „wszystkie znaki, które da się wpisać z klawiatury”. To tylko mały, precyzyjny wycinek świata tekstu. I właśnie dlatego dobrze go znać na starcie, zanim wejdzie się w bardziej złożone kodowania i języki znaków. Żeby jednak nie poprzestać na definicji, trzeba zobaczyć, jak ten standard wygląda w tabeli.
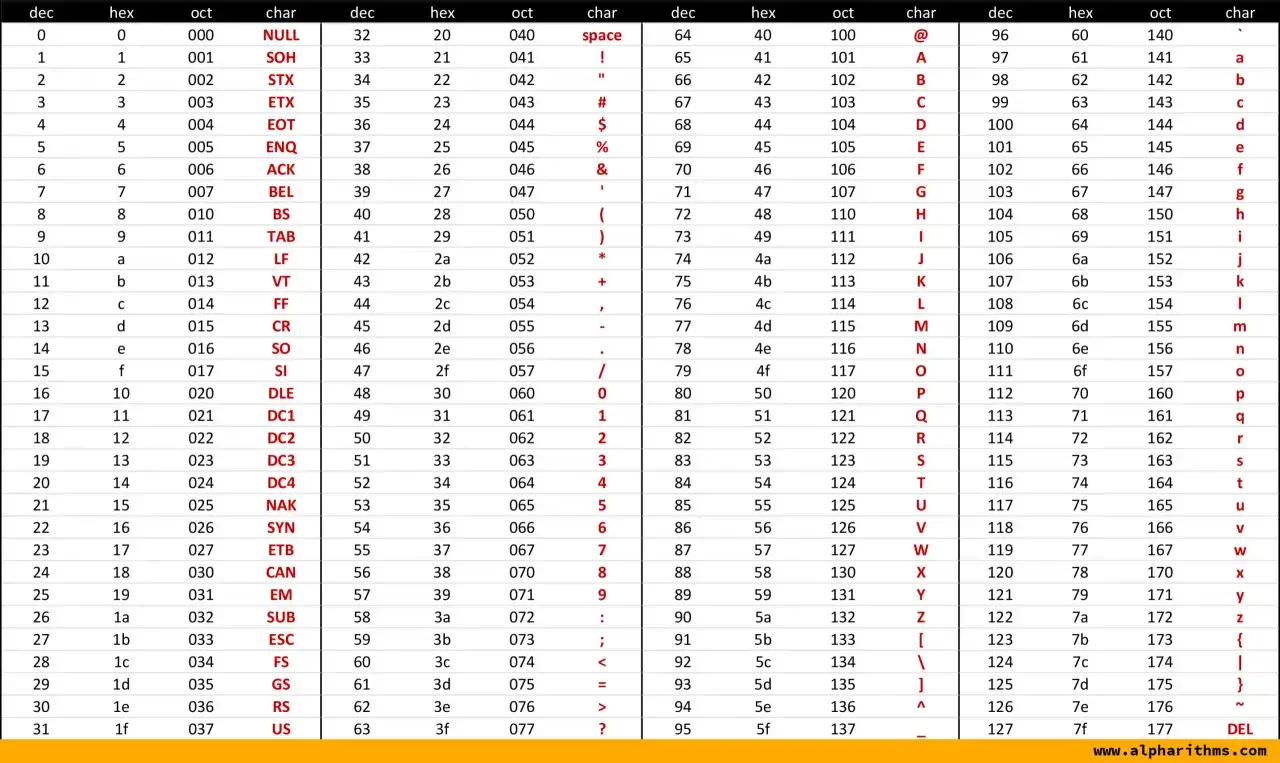
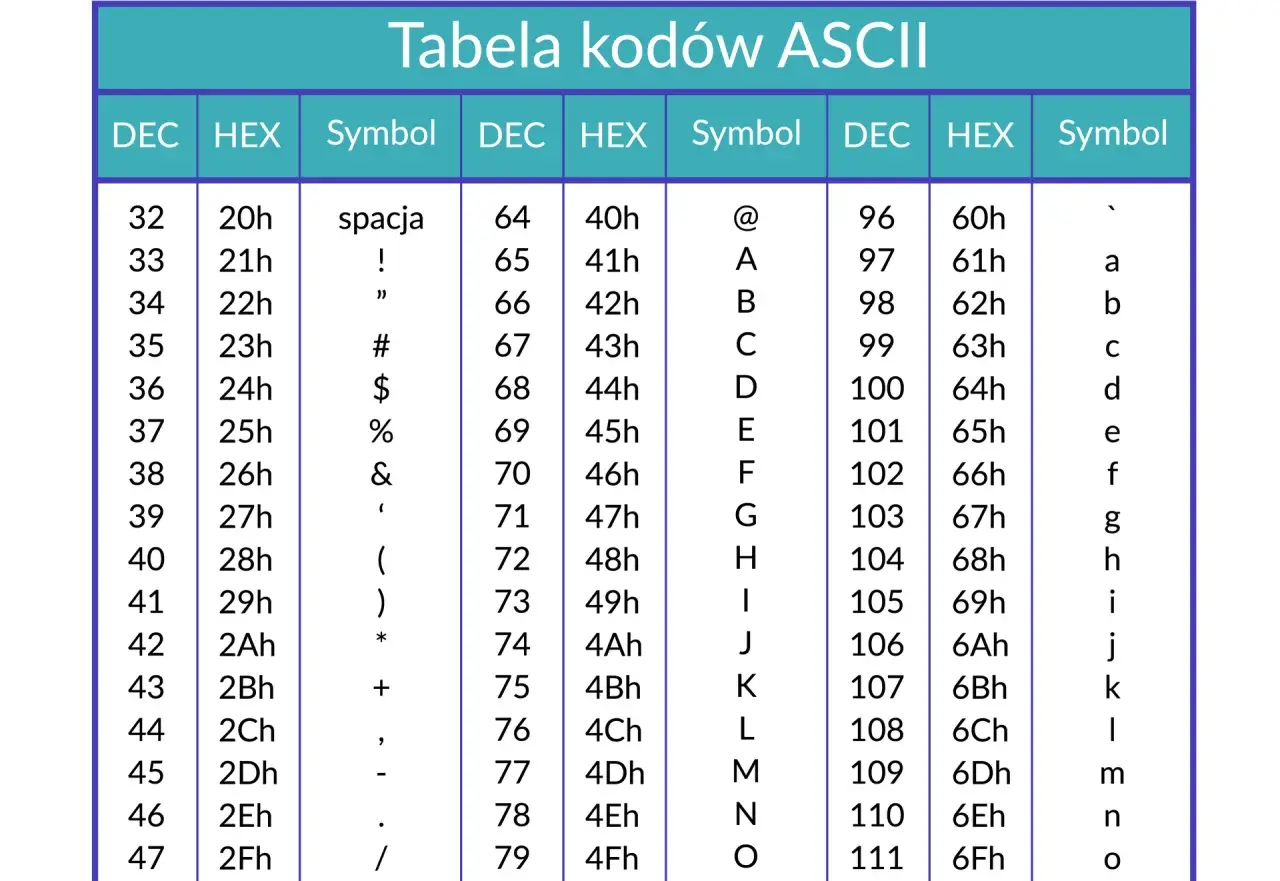
Jak czytać tabelę ASCII
Tabela ASCII dzieli się na dwie wyraźne części: znaki kontrolne i znaki drukowalne. Pierwsza grupa obejmuje kody od 0 do 31 oraz 127, a druga od 32 do 126. Dla osoby uczącej się programowania najpraktyczniejsze jest nie zapamiętywanie wszystkiego na ślepo, tylko zrozumienie układu.
| Zakres | Co zawiera | Przykłady | Po co to ważne |
|---|---|---|---|
| 0–31 | Znaki kontrolne | NUL, TAB, LF, CR | Służą do sterowania tekstem, a nie do wyświetlania liter |
| 32 | Spacja | SPACE | To także znak ASCII, mimo że jest niewidoczny |
| 33–47 | Interpunkcja i symbole | !, ", #, $, %, / | Często pojawiają się w URL-ach, kodzie i formułach |
| 48–57 | Cyfry | 0–9 | Przydatne przy parsowaniu danych i walidacji wejścia |
| 65–90 | Wielkie litery | A–Z | Wiele formatów technicznych używa właśnie tego zakresu |
| 97–122 | Małe litery | a–z | Podstawa dla prostych identyfikatorów i tekstu ASCII |
| 127 | DEL | Delete | Historyczny znak sterujący, dziś rzadko używany bezpośrednio |
Najważniejszy wzorzec jest prosty: liczby i litery tworzą uporządkowane bloki, a symbole wypełniają resztę przestrzeni. Dzięki temu można szybko przewidzieć, dlaczego `A` ma kod 65, a `a` 97, bez uczenia się wszystkiego na pamięć. Taka logika jest szczególnie przydatna wtedy, gdy zaczynasz pisać kod, który porównuje znaki albo przetwarza tekst znak po znaku.
Gdy ten układ jest już jasny, warto przejść do znaków, z którymi naprawdę spotyka się programista najczęściej. To właśnie one pojawiają się w logach, plikach tekstowych i prostych walidacjach wejścia.
Najczęściej używane kody i znaki
W codziennej pracy nie trzeba znać pełnej tabeli, ale kilka kodów naprawdę warto mieć w głowie. Są to przede wszystkim litery, cyfry, spacja i znaki sterujące odpowiedzialne za nową linię albo tabulator. W praktyce właśnie one najczęściej wywołują różnice między „działa u mnie” a „nie działa po przeniesieniu do innego systemu”.
| Znak | Kod dziesiętny | Kod szesnastkowy | Zastosowanie |
|---|---|---|---|
| A | 65 | 41 | Wielka litera, często używana w identyfikatorach i przykładach edukacyjnych |
| a | 97 | 61 | Mała litera, przydatna przy różnicowaniu wielkości znaków |
| 0 | 48 | 30 | Początek zakresu cyfr, ważny przy przekształceniach tekstu na liczby |
| spacja | 32 | 20 | Oddziela wyrazy, ale technicznie też jest znakiem |
| TAB | 9 | 09 | Wyrównywanie tekstu, formatowanie i proste pliki tekstowe |
| LF | 10 | 0A | Nowa linia w wielu systemach Unixowych i w większości narzędzi tekstowych |
| CR | 13 | 0D | W starszych systemach i w kombinacji CRLF na Windows |
| ! | 33 | 21 | Popularny znak interpunkcyjny, często w komunikatach i regexach |
| / | 47 | 2F | Separator ścieżek, częsty w adresach i danych technicznych |
Warto tu zwrócić uwagę na znaki kontrolne. Ich nie widać, ale mają realny wpływ na działanie programu. Na przykład `TAB` i `LF` mogą zmienić sposób, w jaki interpreter czyta plik, a różnica między `LF` a `CRLF` potrafi wywołać drobne, ale irytujące problemy z formatowaniem. To właśnie dlatego znajomość podstawowych kodów tekstowych szybko przestaje być teorią, a zaczyna być praktycznym narzędziem.
Kiedy już wiesz, jak czytać tabelę i które kody są ważne, najłatwiej przejść do Pythona. Tam ASCII staje się bardzo konkretnym narzędziem do sprawdzania, zamiany i kodowania znaków.
Jak pracować z ASCII w Pythonie
W Pythonie najprościej myśleć o ASCII jako o mapowaniu znaków na liczby i z powrotem. Do tego służą przede wszystkim trzy mechanizmy: odczyt kodu znaku, tworzenie znaku z kodu oraz kodowanie tekstu do bajtów. To są podstawy, które naprawdę warto opanować na początku.
Odczytywanie kodu znaku
Funkcja ord() zwraca kod liczbowy znaku. Dzięki niej możesz szybko sprawdzić, jak komputer widzi dany symbol.
print(ord('A')) # 65
print(ord('0')) # 48
print(ord('!')) # 33To przydaje się przy walidacji danych, prostym szyfrowaniu, analizie tekstu i ćwiczeniach z podstaw programowania. Jeśli rozumiesz, że znak ma swoją liczbę, łatwiej też zrozumieć warunki, pętle i przetwarzanie ciągów znaków.
Tworzenie znaku z kodu
Funkcja chr() robi odwrotną rzecz: zamienia liczbę na znak. To wygodne, gdy generujesz sekwencje znaków albo testujesz zakresy kodów.
print(chr(65)) # A
print(chr(97)) # a
print(chr(48)) # 0Na tym etapie wiele osób zauważa, że kodowanie tekstu jest bardziej matematyczne, niż się wydawało. I właśnie o to chodzi: ASCII daje prosty model, który da się łatwo prześledzić krok po kroku.
Przeczytaj również: Model Kaskadowy w IT - Czy to nadal dobry wybór?
Sprawdzanie i kodowanie tekstu
Jeśli chcesz upewnić się, że tekst mieści się w ASCII, możesz użyć metody isascii(). To szybki test, który zwraca True tylko wtedy, gdy wszystkie znaki należą do zakresu ASCII.
tekst = "API_01"
print(tekst.isascii()) # True
inne = "zażółć"
print(inne.isascii()) # FalsePodobnie działa kodowanie encode('ascii'). Dla tekstu zgodnego ze standardem dostaniesz bajty, a dla polskich znaków pojawi się błąd kodowania.
print("Hello".encode("ascii")) # b'Hello'
print("Łódź".encode("ascii")) # UnicodeEncodeErrorTo dobry test diagnostyczny. Jeśli aplikacja ma obsługiwać wyłącznie prosty tekst techniczny, takie sprawdzenie pomaga szybko wychwycić nieprawidłowe dane. Jeśli jednak pracujesz z językiem polskim, lepiej od razu przejść do Unicode i UTF-8. To prowadzi do najważniejszego porównania w całym temacie.
ASCII a Unicode w polskim tekście
ASCII jest wąskim standardem, a Unicode jest jego nowoczesnym rozwinięciem. W praktyce oznacza to, że Unicode obsługuje znacznie więcej znaków, w tym polskie litery, symbole matematyczne, emoji i alfabet większości języków świata. Co ważne, pierwsze 128 punktów kodowych Unicode pokrywa się z ASCII, więc podstawy są wspólne.
| Cecha | ASCII | Unicode / UTF-8 |
|---|---|---|
| Liczba znaków | 128 | Setki tysięcy możliwych punktów kodowych |
| Polskie znaki | Nie | Tak |
| Zakres zastosowań | Tekst techniczny, protokoły, proste pliki | Uniwersalny tekst, strony, aplikacje, dokumenty |
| Zgodność z ASCII | Pełna definicja | Pierwsze 128 znaków jest zgodne z ASCII |
| Typowy wybór dziś | Gdy format wymaga prostego tekstu | Domyślnie, szczególnie w językach naturalnych |
Tu pojawia się najczęstsze nieporozumienie: ktoś słyszy o „rozszerzonym ASCII” i zakłada, że istnieje jeden oficjalny zestaw, który rozwiązuje wszystko. W praktyce to skrót myślowy, a nie jeden standard. Jeśli tekst ma zawierać polskie litery, najbezpieczniej przyjąć, że pracujesz z Unicode i zapisujesz dane w UTF-8.
Z mojego doświadczenia wynika też jedna prosta zasada: ASCII traktuję jako punkt odniesienia, ale nie jako docelowy format dla języka polskiego. Dzięki temu unikam problemów z krzakami w plikach, błędami przy zapisie i nieporozumieniami między systemami. To właśnie te praktyczne pułapki warto poznać na końcu.
Gdy ASCII spotyka pliki, api i terminal
Najwięcej problemów nie bierze się z samego standardu, tylko z tego, że różne narzędzia inaczej interpretują tekst. Jeśli plik był zapisany w UTF-8, a program próbuje czytać go jak czysty ASCII, szybko pojawią się błędy. Jeśli z kolei kod zakłada, że każda linia kończy się tak samo, różnica między LF i CRLF potrafi popsuć parsowanie albo testy.
- Waliduj wejście, jeśli format naprawdę wymaga wyłącznie ASCII.
- Używaj UTF-8, gdy tekst ma zawierać polskie znaki lub inne znaki spoza ASCII.
- Nie myl tekstu z bajtami, bo to dwa różne poziomy pracy z danymi.
- Jeśli widzisz „krzaki”, najpierw sprawdź kodowanie pliku, a dopiero potem logikę programu.
- W protokołach i prostych formatach tekstowych zwracaj uwagę na spacje, tabulatory i znaki końca linii.
W praktyce najlepiej działa podejście warstwowe: ASCII znam jako prostą bazę i narzędzie diagnostyczne, a w normalnych projektach tekstowych stawiam na Unicode z UTF-8. To daje większą elastyczność, mniej błędów i znacznie lepszą kompatybilność z polskim językiem oraz współczesnymi aplikacjami.