
Najkrócej mówiąc, dobra kolekcja oszczędza czas, pamięć i poprawki w kodzie
- Najpierw patrzę na to, jakie operacje dominują: odczyt, dopisywanie, wyszukiwanie czy usuwanie.
-
listsprawdza się przy prostych sekwencjach,dictprzy parze klucz-wartość, asetprzy unikalności. -
dequejest dobrym wyborem do kolejek i buforów, bo dobrze obsługuje oba końce. - Stos i kolejka to częściej model zachowania niż osobna „magiczna” klasa.
- W Pythonie nie muszę od razu budować własnych konstrukcji, ale muszę umieć rozpoznać, kiedy gotowy typ przestaje wystarczać.
Czym są kolekcje w programowaniu i dlaczego mają znaczenie
Ja zwykle tłumaczę ten temat bardzo prosto: kolekcja to sposób, w jaki program trzyma wiele elementów naraz i decyduje, jak do nich dochodzi. Jedne struktury nadają się do przechodzenia po elementach po kolei, inne do szybkiego odnajdywania po kluczu, a jeszcze inne do pilnowania, żeby nie było duplikatów.
To nie jest tylko teoria o nazwach. Ten sam problem można zapisać na kilka sposobów, ale wybór kolekcji wpływa na czytelność, wydajność i łatwość późniejszej zmiany kodu. Jeśli na starcie pomylisz wzorzec dostępu, później często płacisz za to w trzech miejscach naraz: w logice, w testach i w wydajności.
Dlatego zanim wybiorę typ danych, pytam sam siebie o cztery rzeczy: czy kolejność ma znaczenie, czy elementy mogą się powtarzać, jak często będę je odczytywać i jak często będę je modyfikować. Kiedy widać ten podział, łatwiej przejść do typów, które pojawiają się w praktyce najczęściej.
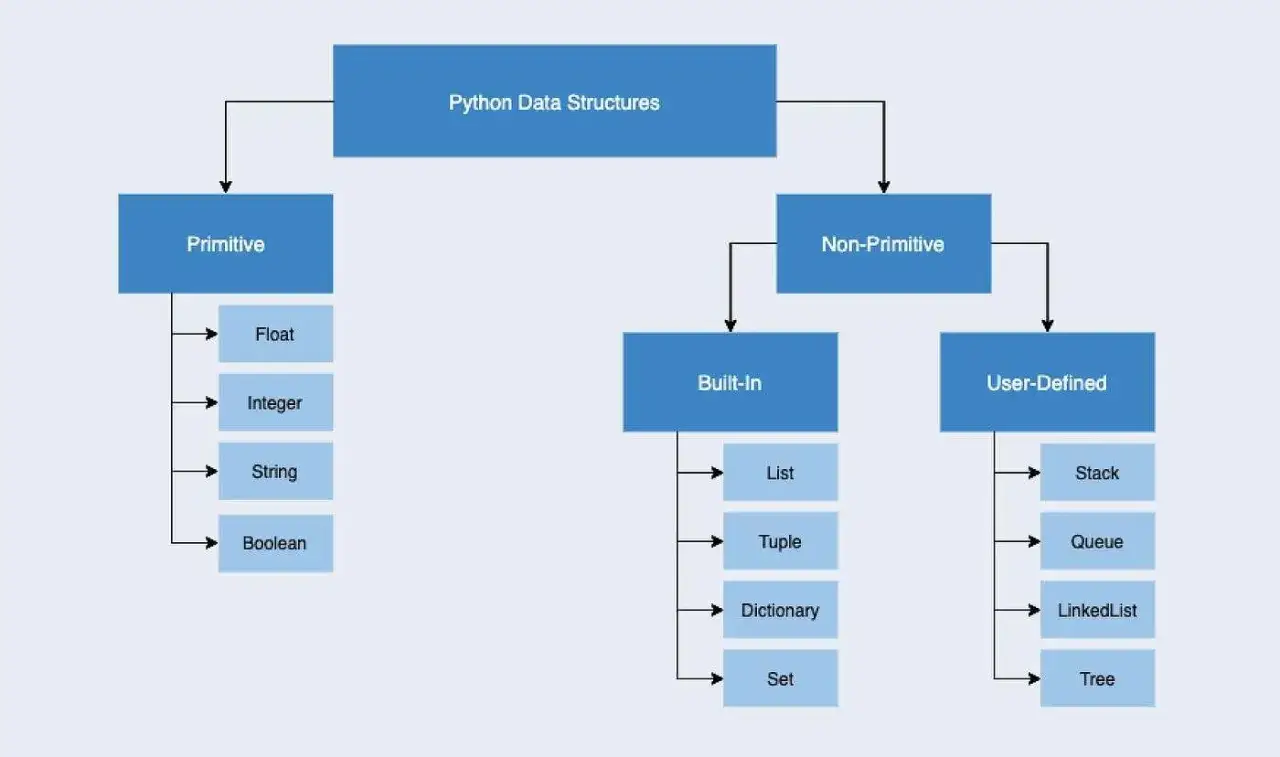
Najważniejsze typy, które warto znać od razu
Na początku nie trzeba znać całej teorii o drzewach, grafach i haszowaniu. Wystarczy kilka podstawowych typów i jasne zrozumienie, co każdy z nich robi najlepiej.
| Typ | Do czego służy | Kiedy wybieram go najczęściej | Ograniczenie, o którym warto pamiętać |
|---|---|---|---|
list |
Uporządkowana sekwencja elementów | Gdy liczy się kolejność, indeks i prosty zapis danych | Wstawianie i usuwanie z początku bywa kosztowne |
tuple |
Uporządkowana, niemutowalna sekwencja | Gdy dane nie powinny się zmieniać po utworzeniu | Nie edytuję jej „w miejscu”, więc nie nadaje się do dynamicznych zmian |
dict |
Mapa klucz-wartość | Gdy chcę szybko znaleźć coś po nazwie, identyfikatorze lub innym kluczu | Klucze muszą być haszowalne, czyli możliwe do jednoznacznego przeliczenia przez interpreter |
set |
Zbiór unikalnych elementów | Gdy chcę usuwać duplikaty albo szybko sprawdzać przynależność | Nie nadaje się do pracy opartej na indeksach i nie służy do porządku, tylko do unikalności |
deque |
Kolejka dwustronna | Gdy dodaję i usuwam elementy z obu końców | Nie zastępuje listy we wszystkich zadaniach, bo nie jest optymalna do przypadkowego dostępu |
array |
Zwarto przechowywane wartości jednego typu | Gdy trzymam dużo liczb i zależy mi na mniejszym narzucie pamięci | Ma mniejszą elastyczność niż lista |
Istotne jest też rozróżnienie ról. Stos i kolejka to przede wszystkim modele działania. Stos działa według zasady LIFO, czyli ostatni wchodzi, pierwszy wychodzi, a kolejka według FIFO, czyli pierwszy wchodzi, pierwszy wychodzi. W Pythonie takie zachowanie najczęściej buduję na bazie listy albo, lepiej, na bazie deque.
Jak podaje dokumentacja Pythona, deque jest zaprojektowane do szybkiego dodawania i usuwania z obu końców, podczas gdy operacje typu pop(0) i insert(0, v) na liście wymagają przesuwania elementów. To ma znaczenie szybciej, niż wielu początkujących zakłada. Sama znajomość nazw nie wystarcza, więc za chwilę rozbijam to na konkretne kryteria wyboru.
Jak dobrać właściwą kolekcję do zadania
Ja wybieram typ nie po tym, jak „wygląda”, tylko po tym, co robi najczęściej. Jeśli większość operacji to odczyt po kluczu, słownik wygrywa niemal od razu. Jeśli najważniejsze jest pilnowanie unikalności, sięgam po zbiór. Jeśli potrzebuję zachować kolejność i wygodnie iterować, zwykle zaczynam od listy.
- Jeśli dane mają naturalną kolejność, wybieram
listalbotuple. - Jeśli potrzebuję szybkiego dostępu po nazwie, identyfikatorze lub innym kluczu, wybieram
dict. - Jeśli chcę sprawdzić, czy element już istnieje, albo usunąć duplikaty, wybieram
set. - Jeśli przetwarzam zadania „po kolei” i dochodzą nowe elementy na obu końcach, wybieram
deque. - Jeśli trzymam dużo jednorodnych wartości liczbowych, rozważam
array, bo bywa oszczędniejszy pamięciowo niż lista.
W praktyce największy błąd polega na tym, że ktoś bierze listę „na wszelki wypadek”, bo zna ją najlepiej. To działa na małych danych, ale przy większych zbiorach potrafi ukryć koszt, który później wybucha przy realnym obciążeniu. Gdy zasady są jasne, najlepiej zobaczyć je na krótkich przykładach w Pythonie.
Jak wygląda to w Pythonie na prostych przykładach
Najbardziej lubię uczyć tego przez małe scenariusze, bo wtedy decyzja przestaje być abstrakcyjna. Zamiast „jaki typ danych wybrać?” pytam: „co mój kod ma robić za minutę, a co za tydzień?”.
# Lista: zachowuję kolejność i mogę dodawać kolejne elementy
zadania = ["nauka", "ćwiczenia", "powtórka"]
zadania.append("projekt")
# Słownik: szybki dostęp po kluczu
profil = {
"imie": "Ala",
"jezyk": "Python",
"poziom": "początkujący"
}
# Zbiór: unikalne wartości i szybkie sprawdzanie przynależności
tagi = {"python", "backend", "python"}
print(tagi) # duplikat znika
# Kolejka dwustronna: wygodne dodawanie i usuwanie z obu końców
from collections import deque
bufor = deque(["zadanie 1", "zadanie 2"])
bufor.append("zadanie 3")
pierwsze = bufor.popleft()W tym przykładzie różnica jest bardzo konkretna. Lista nadaje się do prostego planu działań, słownik przechowuje pary opisowe, zbiór pilnuje unikalności, a deque sprawdza się tam, gdzie liczy się kolejność obsługi. To nie są konkurencyjne narzędzia, tylko różne odpowiedzi na różne pytania.
Jeśli chcesz zobaczyć jeszcze jedną praktyczną granicę, porównaj zachowanie listy i słownika przy odczycie. Lista wymaga przejścia po elementach lub indeksu, a słownik odwołuje się bezpośrednio do klucza. Właśnie dlatego struktura danych wpływa nie tylko na styl kodu, ale też na jego tempo działania. Na tym etapie widać już, gdzie dana kolekcja pomaga, a gdzie tylko komplikuje kod.
Najczęstsze błędy początkujących i jak ich uniknąć
W podstawach programowania powtarza się kilka pomyłek, które są zrozumiałe, ale kosztują czas. Najczęściej widzę pięć rzeczy.
- Używanie listy do wszystkiego, nawet wtedy, gdy lepszy byłby słownik albo zbiór.
- Mylenie kolejności wyświetlania z kolejnością, na której naprawdę trzeba polegać w logice programu.
- Próba ręcznego „dopisywania” zachowania kolekcji, które już jest dostępne w standardowej bibliotece.
- Ignorowanie kosztu operacji, zwłaszcza przy dodawaniu i usuwaniu z początku sekwencji.
- Przekonanie, że bardziej złożona struktura automatycznie da lepszy kod. Zwykle daje tylko więcej miejsc do błędu.
Ja mam prostą zasadę: jeśli nie umiem powiedzieć jednym zdaniem, po co mi dana kolekcja, to jeszcze nie wybrałem jej dobrze. To dobry test szczególnie wtedy, gdy projekt jest mały i łatwo ulec pokusie „na razie to zostawię, potem poprawię”. Potem jednak przychodzi moment, w którym ten tymczasowy wybór staje się architekturą.
Warto też pamiętać o mutowalności. Obiekty zmienne można edytować po utworzeniu, a niemutowalne już nie. To rozróżnienie porządkuje myślenie o błędach, bo wiele problemów w Pythonie nie wynika z samej kolekcji, tylko z tego, że ktoś zmienia ją w miejscu, choć nie powinien. Jeśli te pułapki są znane, łatwiej wejść w bardziej zaawansowane tematy bez chaosu.
Co warto opanować po pierwszym kontakcie z kolekcjami
Jeśli podstawy już „kliknęły”, następny krok nie polega na wkuwaniu kolejnych nazw. Znacznie lepiej działa zrozumienie kilku szerszych pojęć, które spinają temat w całość.
- Złożoność obliczeniowa pokazuje, jak zmienia się koszt operacji wraz z rozmiarem danych.
- Haszowanie pomaga zrozumieć, dlaczego słowniki i zbiory są tak szybkie przy wyszukiwaniu.
- Model LIFO i FIFO wyjaśnia, skąd biorą się stosy i kolejki.
- Drzewa przydają się do hierarchii, na przykład menu, katalogów albo zależności.
- Grafy opisują sieci relacji, czyli coś więcej niż liniowy porządek elementów.
Przy dalszej nauce polecam jedną praktykę, którą sam uważam za najskuteczniejszą: weź jeden realny problem, na przykład listę zadań, magazyn książek albo prosty katalog kontaktów, i rozpisz go najpierw na papierze. Zapisz, czy częściej odczytujesz, dopisujesz, usuwasz czy szukasz po kluczu. Dopiero potem wybierz kolekcję. Taki sposób myślenia daje dużo lepszą intuicję niż samo zapamiętywanie definicji.
Gdy umiesz dobrać listę, słownik, zbiór albo deque do konkretnego zadania, reszta programowania zaczyna układać się znacznie szybciej. To właśnie wtedy podstawy przestają być teorią, a stają się narzędziem do pisania lepszego kodu.