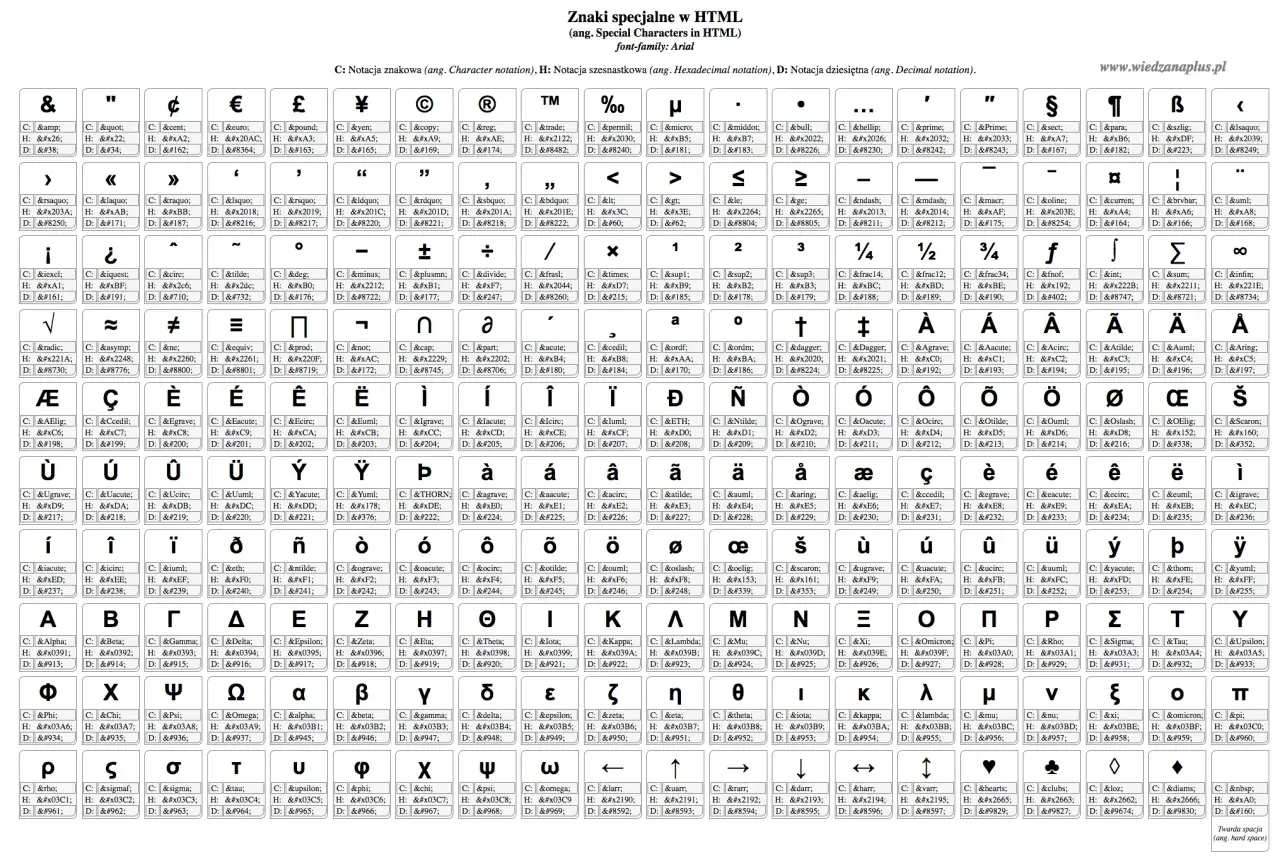
W HTML najwięcej problemów sprawiają nie same symbole, tylko sytuacje, w których parser traktuje je jako część składni. Dlatego w praktyce trzeba wiedzieć, kiedy znak zapisać literalnie, kiedy zamienić go na encję i jak uniknąć błędów w atrybutach, treści artykułu oraz interfejsie. Poniżej zbieram zasady i najczęściej używane zapisy tak, żeby dało się z nich korzystać od razu w pracy frontendowej.
Najkrótsza droga do poprawnego zapisu znaków w HTML
-
Escapuj zawsze znaki
<,>,&oraz cudzysłowy w miejscach, gdzie HTML może je zinterpretować jak składnię. - W UTF-8 większość zwykłych symboli możesz zostawić bez encji, bo przeglądarka wyświetli je poprawnie.
-
Do codziennej pracy najwygodniejsze są nazwy encji, np.
©,€i -
W atrybutach szczególnie pilnuj
&, bo niezamknięty ampersand potrafi zmienić znaczenie adresu lub parametru. -
Które znaki w HTML wymagają ucieczki i dlaczego
Najważniejsza zasada jest prosta: tylko część znaków w HTML ma znaczenie składniowe. Chodzi przede wszystkim o <, >, &, a w atrybutach także o cudzysłów i apostrof, jeśli używasz ich jako ograniczników wartości. Jeśli wpiszesz 2 < 3, przeglądarka pokaże zwykły tekst. Jeśli wpiszesz 2 < 3 bez ucieczki w miejscu, gdzie parser oczekuje HTML, kod zacznie się rozjeżdżać.
W praktyce patrzę na to tak: jeśli znak może zostać odczytany jako początek tagu, separator atrybutu albo początek encji, to nie ryzykuję i zapisuję go jawnie. To oszczędza czasu przy debugowaniu i od razu zmniejsza liczbę błędów w treści, zwłaszcza wtedy, gdy tekst pochodzi z CMS-a, tłumaczenia albo generatora treści. Gdy ten mechanizm jest już jasny, najwygodniej przejść do gotowej ściągi najczęstszych encji.

Najczęściej używane encje w codziennej pracy
W praktyce nie trzeba znać setek nazw z pamięci. Wystarcza mały zestaw, który pokrywa większość sytuacji w treściach, komponentach i opisach produktów. To właśnie ten zestaw najczęściej ratuje układ strony, gdy tekst ma przejść przez edytor, CMS albo ręcznie pisany fragment HTML.
| Znak | Encja | Kiedy używam |
|---|---|---|
< |
< |
Gdy pokazuję fragment kodu, porównanie lub zapis wyglądający jak tag. |
> |
> |
Gdy znak mógłby zostać odczytany jako część składni albo chcę zachować symetrię w przykładach. |
& |
& |
W treści, linkach i parametrach, szczególnie gdy tekst przechodzi przez atrybut href lub title. |
" |
" |
W atrybutach zamkniętych podwójnym cudzysłowem oraz w cytatach, które mają zostać zapisane dosłownie. |
' |
' |
Gdy warto zachować apostrof w sposób jednoznaczny, zwłaszcza w treściach lub atrybutach z pojedynczymi cudzysłowami. |
| spacja nierozdzielająca | |
Gdy nie chcę, aby liczba, skrót albo krótka fraza rozbiła się na dwie linie. |
© |
© |
W stopkach, notach prawnych i oznaczeniach praw autorskich. |
® |
® |
Przy nazwach zastrzeżonych znaków towarowych. |
™ |
™ |
W opisach marek i materiałach marketingowych. |
€ |
€ |
W cenach i walutach, gdy chcesz zachować spójność albo pracujesz z treścią generowaną automatycznie. |
– |
– |
Do zakresów, na przykład 10–12 min, kiedy zależy mi na poprawnej typografii. |
— |
— |
W tekstach redakcyjnych i w interfejsach, gdzie myślnik ma pełnić funkcję pauzy. |
° |
° |
W temperaturach, kątach i danych technicznych. |
Ten zestaw nie wyczerpuje tematu, ale w 90 procentach przypadków wystarcza. Gdy wiesz już, które symbole najczęściej pojawiają się w treści, sensownie jest przejść do pytania, jakim zapisem najlepiej je przedstawiać.
Trzy sposoby zapisu i kiedy wybrać każdy z nich
HTML pozwala zapisać ten sam znak na trzy sposoby: nazwą, zapisem dziesiętnym i zapisem szesnastkowym. Wszystkie działają, ale nie są równie wygodne w czytaniu. Ja zwykle wybieram nazwę encji wtedy, gdy zależy mi na przejrzystości kodu, a wersję liczbową wtedy, gdy treść jest generowana z danych albo chcę odwołać się bezpośrednio do punktu kodowego Unicode.
| Rodzaj zapisu | Przykład | Plus | Minus |
|---|---|---|---|
| Named entity | © |
Najbardziej czytelna dla ludzi i najłatwiejsza w utrzymaniu. | Trzeba znać nazwę albo zajrzeć do ściągi. |
| Zapis dziesiętny | © |
Dobrze działa w treściach generowanych programowo i jest niezależny od nazwy encji. | Jest mniej intuicyjny podczas ręcznej edycji. |
| Zapis szesnastkowy | © |
Krótki i wygodny, gdy myślisz w Unicode albo kopiujesz wartość z dokumentacji. | Łatwiej pomylić zapis, jeśli ktoś rzadko pracuje z kodami znaków. |
Warto zapamiętać jedną rzecz: nazwane encje są najbardziej czytelne w kodzie źródłowym, a zapisy liczbowe są bardziej techniczne. Dodatkowo w HTML nazwane encje powinny kończyć się średnikiem, bo bez niego łatwo o niejednoznaczność, zwłaszcza w atrybutach. To prowadzi do kolejnego pytania: kiedy w ogóle nie trzeba niczego zamieniać.
Kiedy lepiej zostawić zwykły znak
Jeżeli dokument jest poprawnie ustawiony na UTF-8, większość znaków możesz zostawić wprost. Polskie litery, symbol euro, znak stopnia, myślnik półpauzy czy znak towarowy nie wymagają encji tylko dlatego, że są „specjalne”. W praktyce lepiej brzmi i lepiej się utrzymuje treść, która wygląda naturalnie także w kodzie źródłowym.
To szczególnie ważne w UX i UI. Gdy tekst ma być szybko skanowany przez użytkownika, nadmiar encji nie poprawia niczego, a czasem wręcz przeszkadza osobie edytującej treść. Z kolei traktuję jako narzędzie typograficzne, nie jako ozdobę. Używam go chętnie w zapisach typu 15 min, 3 kg albo ul. Kwiatowa, ale nie wstawiam go wszędzie tam, gdzie po prostu nie chce mi się poprawiać łamania linii. Na małych ekranach nadmiar niełamliwych spacji potrafi zrobić więcej szkody niż pożytku.
- Zostawiam znak literalnie, jeśli nie zagraża składni HTML i dokument działa w UTF-8.
- Używam encji, gdy znak może zostać odczytany jako tag, atrybut albo początek innego kodu.
-
Sięgam po
Ta kolejność dobrze działa w większości projektów frontendowych, bo chroni zarówno czytelność, jak i układ interfejsu. Następny krok to unikanie błędów, które najczęściej psują pracę z encjami.
Najczęstsze błędy, które psują treść albo linki
Przy znakach specjalnych błędy zwykle nie wyglądają spektakularnie. To raczej drobne rzeczy, które później kosztują czas: źle wygenerowany link, zepsuty atrybut, dziwna spacja w przycisku albo niechciana zmiana treści po imporcie do CMS-a. Z mojego doświadczenia wynika, że właśnie te małe potknięcia są najdroższe w utrzymaniu.
-
Nieescapowany
&w adresach - jeśli whrefmasz parametr z kilkoma wartościami, zapis bez&może zostać źle odczytany przez parser. -
Brak średnika - zapis typu
©bywa interpretowany inaczej niż się wydaje, więc w kodzie lepiej zawsze kończyć encję średnikiem. -
Podwójne kodowanie - jeśli treść przejdzie przez dwa etapy escape’owania, z
<robi się coś, czego użytkownik już nie rozpozna. -
Nadmierne użycie
- Mieszanie HTML z JavaScriptem lub CSS - encja HTML nie jest tym samym co escape w stringu JS, więc ten sam znak trzeba zabezpieczać w odpowiednim miejscu.
Jeśli mam zapamiętać tylko jedną rzecz z tej sekcji, to tę: zawsze sprawdzam kontekst. Ten sam znak może wymagać innego traktowania w treści, innego w atrybucie i jeszcze innego w stringu po stronie JavaScriptu. Dzięki temu kod nie tylko działa, ale też pozostaje czytelny dla zespołu.
Co zostawiam w głowie przy pracy z treściami ui
Przy projekcie frontendowym trzymam się prostego porządku: najpierw poprawne kodowanie dokumentu, potem ucieczka znaków składniowych, a dopiero na końcu dobór encji typograficznych. To wystarcza, żeby treść wyglądała dobrze, a interfejs nie łamał się w najmniej oczekiwanym momencie.
- UTF-8 daje największą swobodę i zwykle eliminuje potrzebę ręcznego kodowania większości symboli.
- Encje są obowiązkowe tam, gdzie znak mógłby zostać odczytany jako składnia HTML.
-
- Czytelność kodu ma znaczenie również w treściach redakcyjnych, bo później poprawiają je copywriterzy, tłumacze i osoby z zespołu UX.
Jeżeli pilnujesz tych zasad, praca ze znakami specjalnymi przestaje być źródłem przypadkowych błędów, a staje się zwykłą, przewidywalną częścią frontendu. Właśnie o to chodzi: żeby treść była poprawna technicznie, wygodna w edycji i bezpieczna dla układu strony.