
ChatGPT nie działa jak wyszukiwarka ani baza gotowych odpowiedzi. To model językowy, który uczy się wzorców z danych, a potem buduje odpowiedź token po tokenie na podstawie kontekstu, który mu podasz. W tym artykule rozbijam ten mechanizm na prostsze części: od danych treningowych, przez transformer i dopasowanie do ludzkich instrukcji, aż po ograniczenia, które w praktyce najbardziej wpływają na jakość odpowiedzi.
Najkrócej: to model, który przewiduje kolejne tokeny na podstawie kontekstu
- Tekst jest dzielony na tokeny, czyli mniejsze jednostki niż całe słowa, a model wybiera najbardziej prawdopodobną kontynuację.
- Rdzeniem ChatGPT jest architektura transformer, która analizuje zależności między fragmentami tekstu przez mechanizm uwagi.
- Najpierw model uczy się na dużych zbiorach danych, a potem jest dopasowywany do instrukcji człowieka i preferowanych odpowiedzi.
- To dlatego brzmi płynnie i pomocnie, ale nadal może halucynować, mylić fakty i źle interpretować niejasne polecenia.
- Lepsze efekty daje prompt z celem, kontekstem, ograniczeniami i oczekiwanym formatem odpowiedzi.
Od tekstu do tokenów
Jeśli chcesz naprawdę zrozumieć, jak działa ChatGPT, zacznij od najprostszej rzeczy: model nie czyta zdań jak człowiek, tylko przetwarza je w postaci tokenów. Token to kawałek tekstu, który może być całym słowem, jego fragmentem albo nawet samym znakiem interpunkcyjnym. Dzięki temu model operuje na liczbach, a nie na „znaczeniu” w ludzkim sensie.
Gdy wpisujesz pytanie, system zamienia je na ciąg reprezentacji numerycznych. Potem model analizuje ten ciąg i wybiera najbardziej prawdopodobny kolejny token, potem następny i następny. Właśnie dlatego odpowiedź powstaje stopniowo, a nie jako gotowa myśl z jednego rzutu. To też wyjaśnia, czemu dwa bardzo podobne pytania mogą dać lekko różne odpowiedzi.
| Pojęcie | Co oznacza | Dlaczego ma znaczenie |
|---|---|---|
| Token | Mały fragment tekstu, niekoniecznie całe słowo | Model liczy i generuje odpowiedzi w takich jednostkach, więc długość promptu i odpowiedzi działa inaczej niż zwykłe „liczenie słów” |
| Okno kontekstu | Ilość tekstu, którą model bierze pod uwagę naraz | Gdy rozmowa jest długa, wcześniejsze fragmenty mogą przestać mieścić się w bieżącym kontekście |
| Parametry | Duży zbiór liczb opisujących wyuczone wzorce | To one przechowują statystyczną „wiedzę” modelu, a nie pojedyncze zdania z pamięci |
Najważniejsze jest jednak to, że model nie działa jak archiwum dokumentów. On nie „szuka w pamięci” gotowej odpowiedzi, tylko szacuje, jaka kontynuacja pasuje najlepiej do aktualnego kontekstu. To właśnie dlatego trzeba myśleć o nim bardziej jak o bardzo zaawansowanym silniku predykcji języka niż o encyklopedii. Z takiego podejścia naturalnie wynika pytanie, co sprawia, że potrafi uwzględniać cały sens zdania, a nie tylko ostatnie kilka słów.
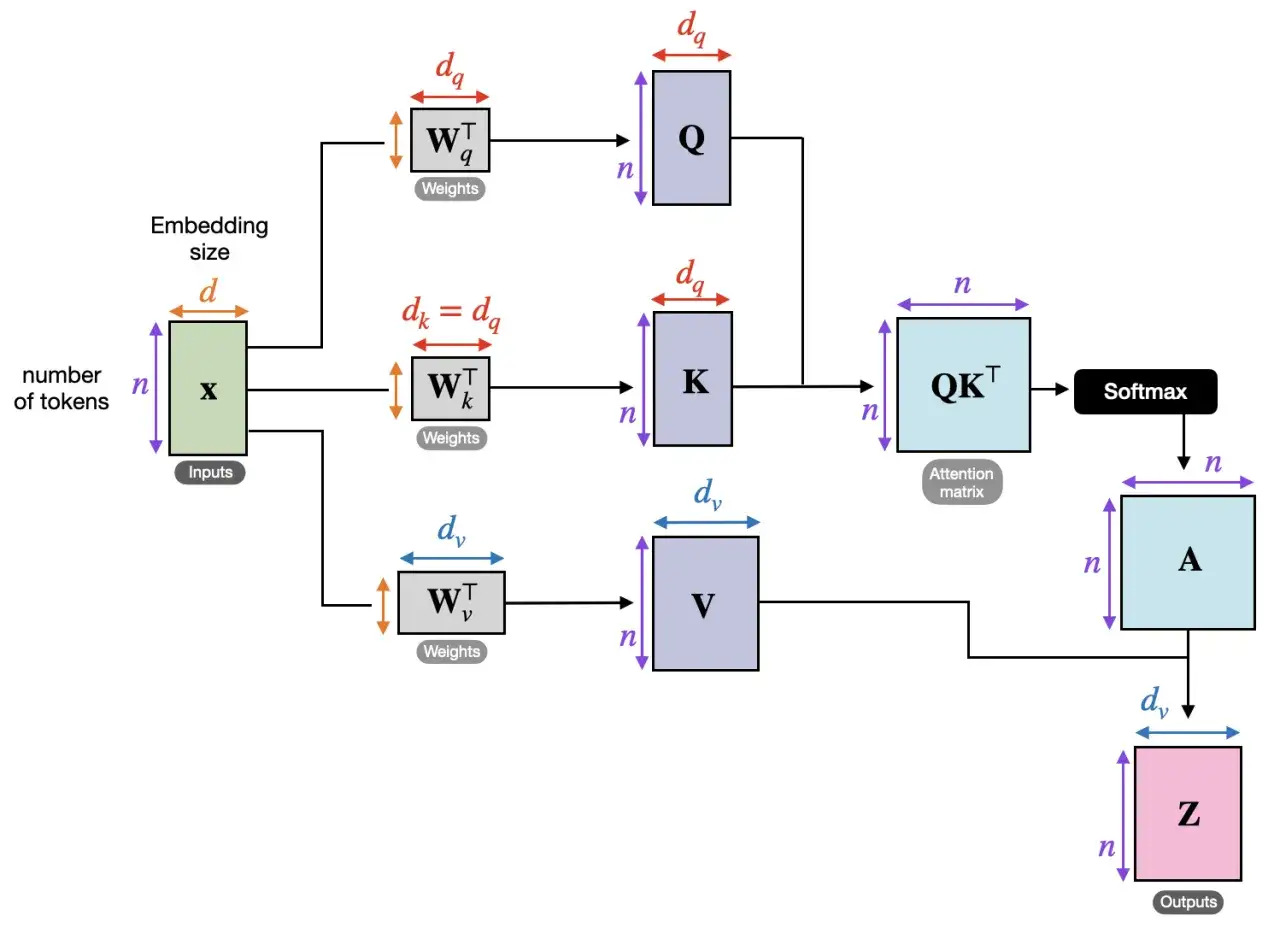
Transformer, który pilnuje kontekstu
Sercem GPT jest architektura transformer. To właśnie ona sprawia, że model potrafi śledzić zależności między odległymi fragmentami tekstu bez klasycznego „czytania od lewej do prawej” w stylu starych modeli rekurencyjnych. Transformer opiera się na mechanizmie uwagi, czyli self-attention, który pozwala modelowi ocenić, które elementy zdania są dla siebie nawzajem najważniejsze.
Praktycznie wygląda to tak: gdy model przetwarza zdanie, nie traktuje każdego tokenu izolowanie. Zamiast tego porównuje tokeny ze sobą, nadaje im różne wagi i buduje reprezentację kontekstu. Dzięki temu rozumie, że zaimek może odnosić się do osoby wspomnianej wcześniej, a przymiotnik wpływa na znaczenie rzeczownika, nawet jeśli między nimi stoi kilka innych słów.
| Mechanizm | Rola | Efekt w odpowiedzi |
|---|---|---|
| Self-attention | Ocena, które tokeny są względem siebie istotne | Lepiej łapie odniesienia, zależności i sens całego akapitu |
| Warstwy transformera | Stopniowe przekształcanie reprezentacji tekstu | Model buduje coraz bardziej złożony obraz treści |
| Równoległe przetwarzanie | Analiza wielu fragmentów jednocześnie | Trening jest szybszy i lepiej skaluje się na dużych zbiorach danych |
To ważne także z perspektywy użytkownika. Jeśli pytanie jest dobrze osadzone w kontekście, model ma z czego wyciągać zależności. Jeśli kontekst jest urwany, chaotyczny albo zbyt krótki, transformer nadal zrobi swoje, ale na słabszym materiale. Dopiero na takim fundamencie ma sens rozmowa o danych treningowych i o tym, skąd model bierze wzorce, z których potem skleja odpowiedź.
Skąd model bierze umiejętność odpowiadania
ChatGPT nie powstaje przez „wgranie wiedzy” do jednego pliku. Najpierw przechodzi etap uczenia na ogromnych zbiorach tekstu, a w nowszych wersjach także na innych typach danych, jeśli dany model jest multimodalny. W uproszczeniu chodzi o to, żeby nauczył się statystycznych zależności: jak ludzie formułują zdania, jak układają argumenty, jak wyjaśniają pojęcia i jak odpowiadają na pytania.
W praktyce proces składa się z kilku etapów. Najpierw model uczy się ogólnego wzorca języka, potem jest dopasowywany do instrukcji człowieka, a na końcu dostaje dodatkowe strojenie pod kątem jakości odpowiedzi. To właśnie ten ostatni etap sprawia, że brzmi bardziej jak asystent niż surowy generator tekstu.
| Etap | Co się dzieje | Co z tego wynika |
|---|---|---|
| Pretraining | Model uczy się na dużych zbiorach tekstu i przewiduje kolejne tokeny | Łapie język, styl, wzorce i zależności statystyczne |
| Supervised fine-tuning | Ludzie pokazują przykładowe, dobre odpowiedzi | Model uczy się odpowiadać bardziej jak pomocny asystent |
| Reward model | Odpowiedzi są porównywane i oceniane pod kątem jakości | System wie, które warianty są lepsze od innych |
| RLHF | Dodatkowe strojenie na podstawie ludzkich preferencji | Odpowiedzi stają się bardziej użyteczne, bezpieczne i zgodne z intencją użytkownika |
Właśnie tutaj najlepiej widać różnicę między „czystym” modelem językowym a produktem, z którego korzysta człowiek. Sama baza wie dużo o języku, ale dopiero dopasowanie do instrukcji i preferencji sprawia, że dostajesz odpowiedź, która zwykle wygląda sensownie. To jednak nie oznacza, że model przestaje się mylić. I to prowadzi nas do najważniejszego praktycznego ograniczenia.
Dlaczego brzmi pewnie, a jednak się myli
Największe nieporozumienie wokół ChatGPT polega na tym, że wiele osób bierze płynny styl wypowiedzi za oznakę pewności wiedzy. Ja traktuję to inaczej: model generuje język przekonująco, ale nie gwarantuje prawdy. OpenAI samo zwraca uwagę, że takie systemy potrafią tworzyć odpowiedzi brzmiące wiarygodnie, choć faktycznie błędne lub bezsensowne.
Źródło problemu jest proste i jednocześnie kłopotliwe. Model został nauczony przewidywać najbardziej prawdopodobną kontynuację, a nie odróżniać prawdę od fałszu w sposób, w jaki robi to człowiek wyposażony w wiedzę o świecie i zdrowy sceptycyzm. Jeżeli w danych treningowych pewien wzorzec występował często, model może go odtworzyć nawet wtedy, gdy w konkretnej sytuacji jest nietrafny.
- Halucynacje pojawiają się wtedy, gdy model wymyśla fakt, cytat, datę albo nazwisko, mimo że odpowiada z dużą pewnością.
- Wrażliwość na brzmienie promptu oznacza, że drobna zmiana sformułowania może wyraźnie poprawić albo pogorszyć odpowiedź.
- Niejasne pytania często kończą się zgadywaniem intencji, zamiast dopytania o szczegóły.
- Nadmierna gadatliwość bywa skutkiem preferowania odpowiedzi, które brzmią „pełniej”, nawet gdy nie są lepsze merytorycznie.
- Błędy bezpieczeństwa i stronniczości nadal się zdarzają, dlatego odpowiedzi trzeba filtrować, a nie przyjmować bezkrytycznie.
To właśnie dlatego nie używam ChatGPT jako ostatniego arbitra w sprawach ważnych, tylko jako narzędzia do przyspieszania pracy, porządkowania myśli i generowania wersji roboczych. Jeśli chcesz podnieść jakość odpowiedzi, trzeba zadawać pytania mądrzej. I tu wchodzi druga połowa praktyki: dobry prompt.
Jak pisać prompty, które naprawdę pomagają
Najlepsze wyniki dostaję wtedy, gdy traktuję prompt jak krótki brief, a nie jak jednozdaniowe hasło. Model dużo lepiej pracuje, kiedy wie, jaki jest cel, dla kogo ma pisać, jaki ma przyjąć format i czego ma unikać. To nie jest magia, tylko zwykłe zawężanie przestrzeni możliwych odpowiedzi.
Jeśli mam opisać coś technicznego, zwykle dodaję cztery rzeczy: kontekst, oczekiwany poziom szczegółowości, ograniczenia i format końcowy. Dzięki temu ChatGPT nie musi zgadywać, czy ma pisać krótki opis, długi poradnik, tekst ekspercki czy listę punktów. Zmniejsza to liczbę odpowiedzi, które są poprawne językowo, ale zupełnie nietrafione zadaniowo.
- Podaj cel, czyli co dokładnie ma powstać.
- Dodaj kontekst, czyli dla kogo i w jakiej sytuacji tekst ma być użyty.
- Określ format, na przykład listę, tabelę, sekcje H2 albo krótki akapit.
- Wprowadź ograniczenia, na przykład długość, ton, zakres tematyczny albo poziom trudności.
- Poproś o sprawdzenie założeń, jeśli temat jest niejednoznaczny albo zależy od kilku warunków.
Słabo: napisz o AI.
Lepiej: napisz 900-słowny artykuł dla początkujących o tym, jak działają modele językowe, z prostymi przykładami, bez żargonu i z krótką sekcją o ograniczeniach.
W praktyce to działa zaskakująco dobrze, bo model dostaje mniej okazji do błądzenia. A gdy prompt jest niejednoznaczny, lepiej poprosić go o warianty lub o doprecyzowanie założeń, niż liczyć na to, że sam „domyśli się” idealnie. To z kolei prowadzi do mniej efektownej, ale dużo ważniejszej sprawy: jak obchodzić się z danymi, które wkładasz do narzędzia.
Dane i prywatność bez złudzeń
W obszarze danych najważniejsza jest jedna zasada: nie traktuję czatu jak sejfu. Nawet jeśli model nie przechowuje kopii treningowych danych jak zwykła baza dokumentów, to treści, które wpisujesz, nadal są przetwarzane przez usługę według jej zasad. Z tego powodu nie wrzucam do rozmowy niczego, czego nie chciałbym ujawnić w szerszym obiegu.
W praktyce oznacza to ostrożność przy danych osobowych, hasłach, fragmentach umów, kodach dostępu, poufnych dokumentach i wewnętrznych informacjach firmowych. Jeśli pracuję na materiałach biznesowych, najpierw sprawdzam politykę organizacji, a dopiero potem decyduję, czy dany fragment w ogóle nadaje się do analizy w modelu językowym.
- Nie wklejam danych wrażliwych, jeśli nie są absolutnie potrzebne do zadania.
- Anonimizuję dane, gdy mogę osiągnąć ten sam efekt bez ujawniania szczegółów.
- Traktuję odpowiedzi jako materiał roboczy, a nie jako gotową decyzję prawną, medyczną czy finansową.
- Przy dokumentach firmowych sprawdzam zasady bezpieczeństwa i uprawnienia dostępu.
- Gdy temat wymaga wysokiej dokładności, weryfikuję wynik w niezależnym źródle lub u specjalisty.
Tu szczególnie widać, że ChatGPT jest narzędziem do pracy z informacją, a nie automatycznym gwarantem poprawności. Kiedy zasady obchodzenia się z danymi są jasne, model staje się rozsądnym wsparciem, a nie ryzykiem samym w sobie. Zostaje jeszcze tylko zamknąć to w kilku konkretnych wnioskach, które przydają się na co dzień.
Co zostaje z tego w codziennej pracy
Najbardziej użyteczne w zrozumieniu działania ChatGPT jest to, że przestajesz oczekiwać od niego cudów i zaczynasz używać go precyzyjnie. To nie jest system, który „wie wszystko”, tylko system, który bardzo dobrze składa prawdopodobne odpowiedzi z kontekstu, danych i instrukcji. Gdy o tym pamiętasz, łatwiej oddzielić to, co naprawdę pomaga, od tego, co tylko dobrze brzmi.
Ja patrzę na ten model jak na szybki mechanizm do generowania szkiców, wariantów, streszczeń i roboczych analiz. Najwięcej zyskujesz wtedy, gdy prosisz go o konkret, sprawdzasz fakty, doprecyzowujesz założenia i nie karmisz go zbędnym chaosem. Właśnie tak wygląda praktyczne korzystanie z AI, które naprawdę wspiera pracę zamiast ją udawać.