
Apache Superset to narzędzie, które szczególnie dobrze sprawdza się wtedy, gdy chcesz połączyć eksplorację danych, dashboardy i rosnące wymagania zespołów AI w jednym miejscu. W praktyce daje szybki dostęp do wykresów, zapytań SQL, kontroli uprawnień i automatyzacji, ale tylko wtedy, gdy stoi za nim dobrze uporządkowana warstwa danych. W tym artykule pokazuję, czym Superset naprawdę jest, jak działa, kiedy ma sens w zespole data/AI i jakie pułapki najczęściej spowalniają wdrożenie.
W skrócie, co daje to narzędzie i kiedy warto po nie sięgnąć
- Superset jest platformą open source do eksploracji danych i wizualizacji, a nie hurtownią ani silnikiem obliczeniowym.
- Najlepiej działa jako warstwa analityczna nad dobrze zaprojektowaną bazą lub warehouse’em.
- Dla zespołów data i AI jest użyteczny nie tylko do dashboardów biznesowych, ale też do monitorowania modeli, jakości danych i metryk operacyjnych.
- Ma sens tam, gdzie liczy się self-service SQL, uprawnienia na poziomie ról i możliwość skalowania analityki bez zamykania się w jednym dostawcy.
- W 2026 warto patrzeć na niego również przez pryzmat integracji z asystentami AI przez MCP.
- Najczęstszy błąd to traktowanie go jak gotowego rozwiązania „wszystko w jednym”, bez pracy nad modelem danych i wydajnością zapytań.
Czym jest Superset i gdzie naprawdę się sprawdza
Najkrócej: to platforma do tworzenia wykresów, dashboardów i analityki ad hoc nad danymi, które już masz w swoim źródle. Nie przechowuje danych jako główna baza i nie zastępuje hurtowni, tylko staje się wygodną warstwą dostępu do nich. W oficjalnych materiałach projektu mocno wybrzmiewa prosty układ pracy: użytkownik eksploruje dane przez interfejs webowy, a Superset przekłada to na zapytania SQL i wizualizacje.
W praktyce najbardziej cenię go wtedy, gdy zespół ma kilka klas odbiorców naraz: analityków, managerów, osoby techniczne i ludzi biznesu. Analityk chce zejść do SQL, manager chce dostać czytelny dashboard, a zespół danych chce utrzymać kontrolę nad definicjami metryk i dostępami. Superset dobrze spina te potrzeby, bo łączy wizualny builder wykresów, edytor SQL i mechanizmy zarządzania uprawnieniami.
To nie jest narzędzie dla sytuacji, w której dane są jeszcze chaotyczne, a definicje KPI zmieniają się co tydzień bez właściciela. Jeśli fundament jest słaby, dashboardy tylko to ujawnią. I właśnie dlatego warto najpierw zrozumieć, jak ta platforma działa od środka.
Jak działa od strony technicznej
Superset ma architekturę, która jest dość prosta w założeniu, ale bardzo ważna w skutkach. Backend działa w Pythonie na Flasku, frontend opiera się na React, a komunikacja z bazami i hurtowniami odbywa się przez zapytania SQL. W praktyce wygląda to tak: otwierasz wykres lub dashboard, Superset wysyła zapytanie do źródła danych, pobiera wynik i renderuje go w przeglądarce.
To oznacza dwie rzeczy. Po pierwsze, szybkość całego systemu zależy głównie od jakości źródła danych, indeksów, widoku logicznego i samego SQL, a nie od „magii” interfejsu. Po drugie, jeśli zespół nie dba o model danych, Superset nie naprawi problemu, tylko go elegancko pokaże.
Warto znać kilka pojęć, bo ułatwiają planowanie wdrożenia:
- Dataset to logiczny zbiór danych, na którym budujesz analizy i wykresy.
- Virtual dataset oznacza warstwę opartą o zapytanie SQL, a nie koniecznie fizyczną tabelę.
- RLS czyli row-level security pozwala ograniczać widoczność wierszy danych dla konkretnych ról lub użytkowników.
- SQL Lab to wbudowane miejsce do pisania i testowania zapytań.
Na poziomie wdrożeniowym ważna jest też warstwa API. Superset udostępnia REST API, więc część operacji można automatyzować, a to pomaga przy większych zespołach i powtarzalnych procesach. Z takiej architektury wynika też, że to narzędzie naturalnie prowadzi do tematów AI i automatyzacji, bo świetnie nadaje się jako interfejs do pracy z danymi, a nie tylko jako „kolejny BI”.
Co wnosi do zespołów data i AI
W obszarze data i AI Superset jest użyteczny przede wszystkim tam, gdzie trzeba obserwować metryki, a nie budować modele od zera. Najczęstsze scenariusze, które widzę w praktyce, to monitoring jakości danych, śledzenie KPI produktów cyfrowych, kontrola wyników modeli oraz analiza wykorzystania feature’ów przez użytkowników. Dla zespołu ML to często ważniejsze niż sam trening, bo dopiero metryki operacyjne pokazują, czy model zachowuje się stabilnie po wdrożeniu.
Przykład jest prosty: masz model scoringowy dla e-commerce. W Superset możesz pokazywać rozkład predykcji, udział decyzji pozytywnych, opóźnienia pipeline’u, brakujące wartości w wejściu i zmianę kluczowych cech w czasie. To nie jest narzędzie do trenowania modelu, ale do kontrolowania jego działania w produkcji już jak najbardziej.
W 2026 dochodzi jeszcze jeden ciekawy wątek: integracje z asystentami AI przez MCP. Oficjalna dokumentacja projektu pokazuje, że Superset może współpracować z klientami typu Claude czy ChatGPT, jeśli administrator włączy odpowiednią warstwę po stronie serwera. To ważne nie dlatego, że „AI zrobi wszystko za ludzi”, tylko dlatego, że użytkownik może szybciej zadawać pytania po ludzku, a potem przechodzić do wykresu, SQL albo dashboardu bez przeskakiwania między kilkoma narzędziami.
Tu jednak zachowałbym ostrożność. AI przydaje się jako interfejs i przyspieszacz pracy, ale nie zastępuje porządnego modelu danych, definicji metryk i kontroli dostępu. Jeśli te trzy warstwy są słabe, asystent tylko szybciej pokaże bałagan.
Jak zacząć bez utopienia zespołu w konfiguracji
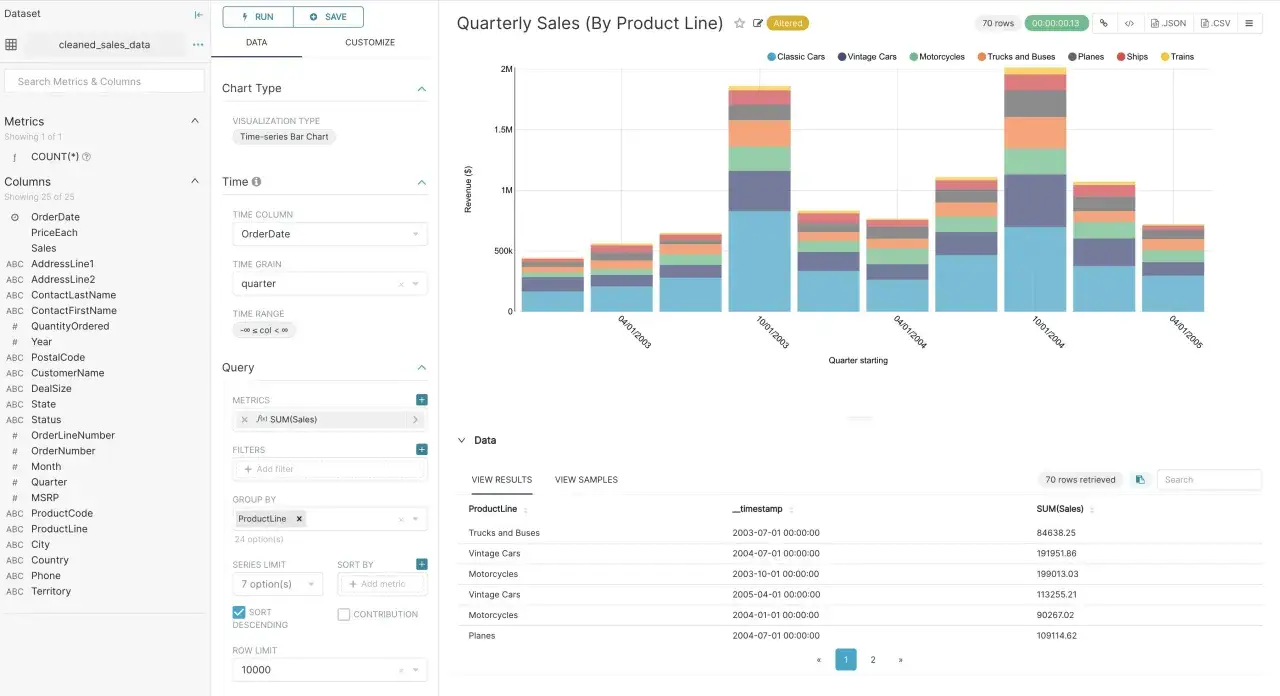
Najrozsądniej zacząć od jednego źródła danych i jednego, dobrze opisanego przypadku użycia. Jeśli chcesz zbudować sensowny start, nie zaczynaj od pięciu dashboardów i dwunastu ról. Zrób najpierw jeden przepływ: baza, dataset, wykres, dashboard, uprawnienia. W dobrze przygotowanym środowisku pierwszy prototyp da się postawić w kilkadziesiąt minut, ale porządne wdrożenie to już kwestia dni, nie godzin.
- Wybierz źródło, które ma jasne definicje pól i stabilny schemat.
- Ustal, kto będzie właścicielem metryk, a kto tylko konsumentem dashboardów.
- Dodaj połączenie do bazy lub hurtowni i sprawdź, czy konta techniczne mają wyłącznie potrzebne uprawnienia.
- Zbuduj jeden dataset oraz 2-3 wykresy, które odpowiadają na realne pytanie biznesowe.
- Dodaj filtrację po czasie, regionie albo produkcie, żeby zweryfikować, czy dashboard jest naprawdę użyteczny.
- Dopiero potem dokładaj role, RLS i automatyzację raportów.
Na etapie startu zaskakująco często wygrywa prostota. Lepszy jest jeden dashboard, który żyje codziennie, niż dziesięć ozdobnych widoków, których nikt nie otwiera. Gdy to działa, można przejść do pytania, kiedy Superset jest lepszym wyborem niż inne narzędzia.
Kiedy wybrać go zamiast innych narzędzi
To narzędzie wygrywa wtedy, gdy chcesz mieć pełną kontrolę nad danymi, samodzielny hosting i rozsądny koszt licencji. Sama licencja jest open source, więc nie płacisz za dostęp do produktu, ale płacisz za infrastrukturę, utrzymanie, bezpieczeństwo i czas ludzi, którzy to ogarną. W polskich zespołach to ważne, bo łatwo zachwycić się brakiem opłaty licencyjnej i zignorować koszt operacyjny.
| Kryterium | Superset | Komercyjne BI | Notebooki i skrypty |
|---|---|---|---|
| Koszt licencji | Brak opłaty licencyjnej | Subskrypcja lub licencja | Zwykle brak, ale bez warstwy biznesowej |
| Najlepsze zastosowanie | Dashboardy, self-service SQL, eksploracja danych | Raportowanie dla dużych organizacji | Eksperymenty i analiza jednorazowa |
| Kontrola i governance | Dobra, ale wymaga konfiguracji | Zwykle bardzo rozbudowana | Słaba, trzeba budować samemu |
| AI i automatyzacja | MCP i integracje z asystentami | Zależy od dostawcy | Własne integracje i skrypty |
| Ryzyko vendor lock-in | Niskie | Wyższe | Niskie, ale przy dużym chaosie operacyjnym rośnie |
Jeśli potrzebujesz pikselowo dopracowanych raportów finansowych, ciężkiego workflow approval albo bardzo specyficznych funkcji enterprise, komercyjne BI może być prostszą drogą. Jeśli natomiast zespół ma dużo SQL, dużo źródeł danych i chce budować wspólną warstwę analityczną bez zamykania się w jednym ekosystemie, Superset ma bardzo mocne argumenty.
Nie wybrałbym go natomiast jako głównego narzędzia do pracy, jeśli cały zespół oczekuje głównie gotowych szablonów, prostego drag-and-drop i minimum konfiguracji. Tu różnica jest uczciwie bardzo praktyczna: Superset daje kontrolę, ale od użytkownika wymaga większej dyscypliny.
Gdzie najczęściej pojawiają się błędy i ograniczenia
Najczęstszy błąd to budowanie dashboardów zanim zespół ustali definicje metryk. Wtedy każda osoba interpretuje „aktywny użytkownik” trochę inaczej, a dashboard zamiast porządkować rzeczywistość, tylko utrwala nieporozumienie. Drugi problem to zbyt ciężkie zapytania. Superset nie jest winny temu, że zapytanie trwa 40 sekund, jeśli źródłowa tabela nie ma indeksów, a model danych miesza pół hurtowni z pół arkusza kalkulacyjnego.
Warto też uważać na bezpieczeństwo. To narzędzie do wizualizacji i eksploracji, nie firewall dla danych. Jeśli pracujesz na danych osobowych, finansowych albo operacyjnych w środowisku zgodnym z wymaganiami europejskimi, musisz dopiąć role, zakresy widoczności i polityki dostępu w bazie oraz w samej aplikacji. Superset pomaga to organizować, ale nie zastępuje administracji danych.
Ostatnia rzecz to aktualizacje. W 2026 projekt jest aktywnie rozwijany, a repozytorium pokazuje już wydanie 6.1.0, więc cykl zmian jest realny, nie teoretyczny. To dobra wiadomość, ale oznacza też, że warto testować nowe wersje na środowisku stagingowym, zanim wprowadzisz je do produkcji. W przypadku narzędzi analitycznych drobna zmiana w uprawnieniach albo interfejsie potrafi zatrzymać pracę całego zespołu na pół dnia.
Te ograniczenia nie dyskwalifikują platformy. One po prostu ustawiają właściwe oczekiwania, a to jest zwykle większa wartość niż kolejna lista „plusów i minusów”.
Co jeszcze warto zrobić, żeby analityka nie rozpadła się po pierwszym kwartale
Jeśli miałbym wskazać trzy rzeczy, które naprawdę decydują o trwałości wdrożenia, byłyby to: model danych, definicje metryk i odpowiedzialność za dostęp. Bez tego każdy dashboard starzeje się szybciej, niż powinien. I właśnie dlatego traktuję Superset jako warstwę końcową, a nie punkt wyjścia.
Najlepiej działa układ, w którym:
- warstwa źródłowa jest czysta i opisana;
- metryki mają jednego właściciela;
- dashboardy są projektowane pod konkretne decyzje, a nie pod „ładny podgląd danych”;
- użytkownicy wiedzą, które wykresy są oficjalne, a które eksploracyjne;
- zespół regularnie sprawdza czas odpowiedzi, bo po przekroczeniu kilku sekund użycie zaczyna spadać.